 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQD: Visual Query Detection in Natural Scenes
Apr 11, 2019
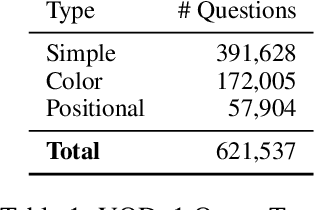
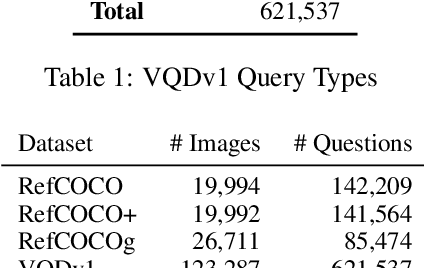
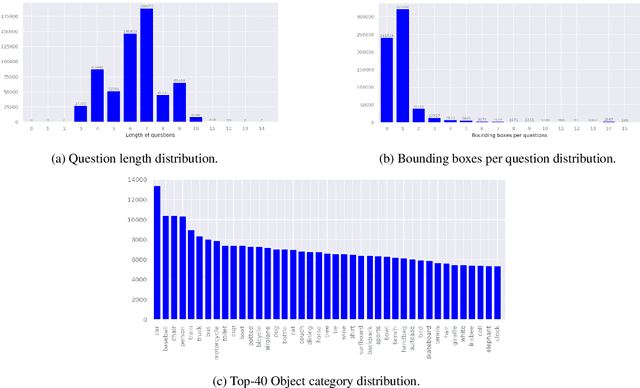
We propose Visual Query Detection (VQD), a new visual grounding task. In VQD, a system is guided by natural language to localize a variable number of objects in an image. VQD is related to visual referring expression recognition, where the task is to localize only one object. We describe the first dataset for VQD and we propose baseline algorithms that demonstrate the difficulty of the task compared to referring expression recognition.
Answer Them All! Toward Universal Visual Question Answering Models
Apr 05, 2019

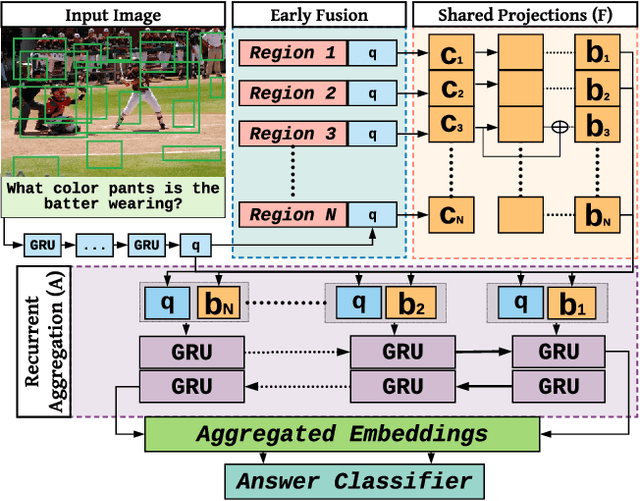
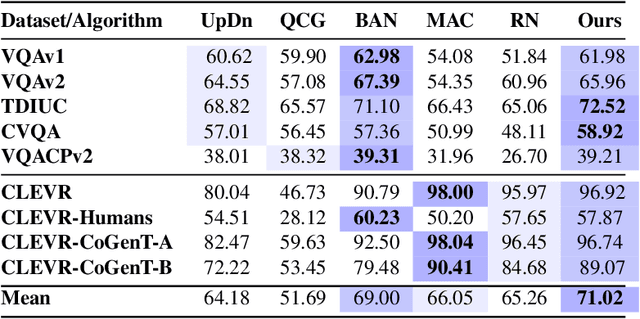
Visual Question Answering (VQA) research is split into two camps: the first focuses on VQA datasets that require natural image understanding and the second focuses on synthetic datasets that test reasoning. A good VQA algorithm should be capable of both, but only a few VQA algorithms are tested in this manner. We compare five state-of-the-art VQA algorithms across eight VQA datasets covering both domains. To make the comparison fair, all of the models are standardized as much as possible, e.g., they use the same visual features, answer vocabularies, etc. We find that methods do not generalize across the two domains. To address this problem, we propose a new VQA algorithm that rivals or exceeds the state-of-the-art for both domains.
TallyQA: Answering Complex Counting Questions
Oct 31, 2018
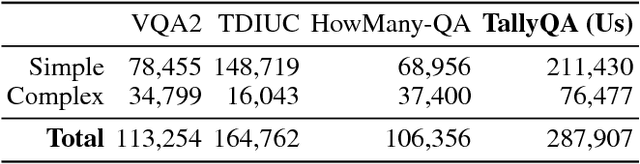
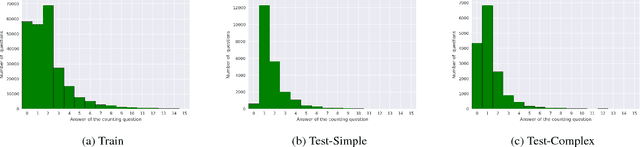
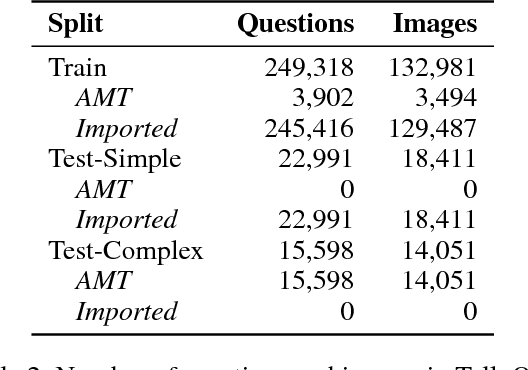
Most counting questions in visual question answering (VQA) datasets are simple and require no more than object detection. Here, we study algorithms for complex counting questions that involve relationships between objects, attribute identification, reasoning, and more. To do this, we created TallyQA, the world's largest dataset for open-ended counting. We propose a new algorithm for counting that uses relation networks with region proposals. Our method lets relation networks be efficiently used with high-resolution imagery. It yields state-of-the-art results compared to baseline and recent systems on both TallyQA and the HowMany-QA benchmark.
Memory Efficient Experience Replay for Streaming Learning
Sep 16, 2018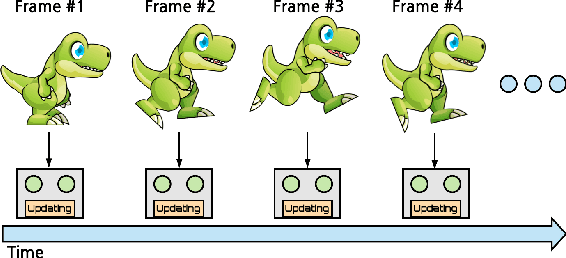
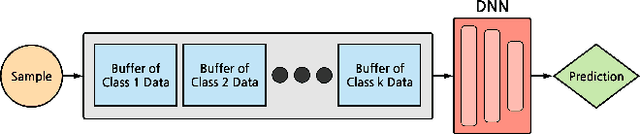

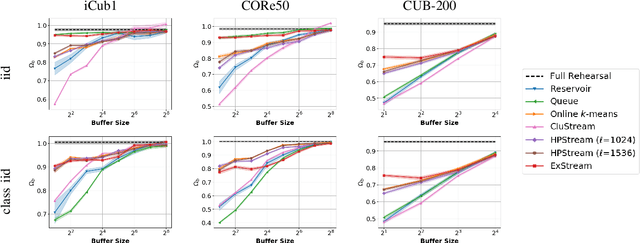
In supervised machine learning, an agent is typically trained once and then deployed. While this works well for static settings, robots often operate in changing environments and must quickly learn new things from data streams. In this paradigm, known as streaming learning, a learner is trained online, in a single pass, from a data stream that cannot be assumed to be independent and identically distributed (iid). Streaming learning will cause conventional deep neural networks (DNNs) to fail for two reasons: 1) they need multiple passes through the entire dataset; and 2) non-iid data will cause catastrophic forgetting. An old fix to both of these issues is rehearsal. To learn a new example, rehearsal mixes it with previous examples, and then this mixture is used to update the DNN. Full rehearsal is slow and memory intensive because it stores all previously observed examples, and its effectiveness for preventing catastrophic forgetting has not been studied in modern DNNs. Here, we describe the ExStream algorithm for memory efficient rehearsal and compare it to alternatives. We find that full rehearsal can eliminate catastrophic forgetting in a variety of streaming learning settings, with ExStream performing well using far less memory and computation.
Continual Lifelong Learning with Neural Networks: A Review
Jul 07, 2018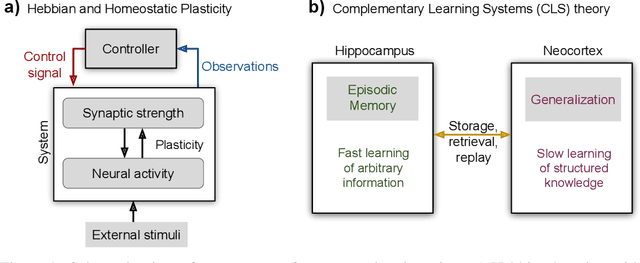
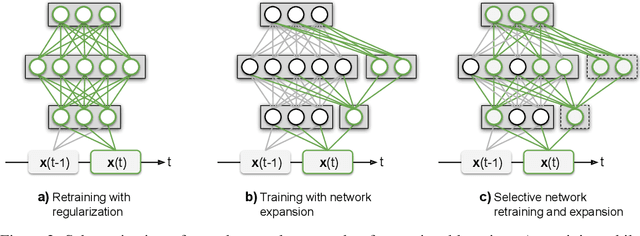

Humans and animals have the ability to continually acquire and fine-tune knowledge throughout their lifespan. This ability, referred to as lifelong learning, is mediated by a rich set of neurocognitive mechanisms that together contribute to the development and specialization of our sensorimotor skills as well as to the long-term memory consolidation and retrieval without catastrophic forgetting. Consequently, lifelong learning capabilities are crucial for computational learning systems and autonomous agents interacting in the real world and processing continuous streams of information. However, lifelong learning remains a long-standing challenge for machine learning and neural network models since the continual acquisition of incrementally available information from non-stationary data distributions generally leads to catastrophic forgetting or interference. This limitation represents a major drawback also for state-of-the-art deep and shallow neural network models that typically learn representations from stationary batches of training data, thus without accounting for situations in which the number of tasks is not known a priori and the information becomes incrementally available over time. In this review, we critically summarize the main challenges linked to lifelong learning for artificial learning systems and compare existing neural network approaches that alleviate, to different extents, catastrophic forgetting. Although significant advances have been made in domain-specific learning with neural networks, extensive research efforts are required for the development of robust lifelong learning on autonomous agents and robots. We discuss well-established and emerging research motivated by lifelong learning factors in biological systems such as neurosynaptic plasticity, multi-task transfer learning, intrinsically motivated exploration, and crossmodal learning.
Characterizing the Temporal Dynamics of Information in Visually Guided Predictive Control Using LSTM Recurrent Neural Networks
May 15, 2018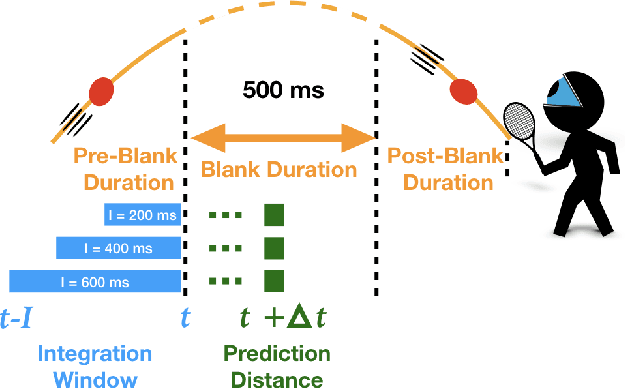

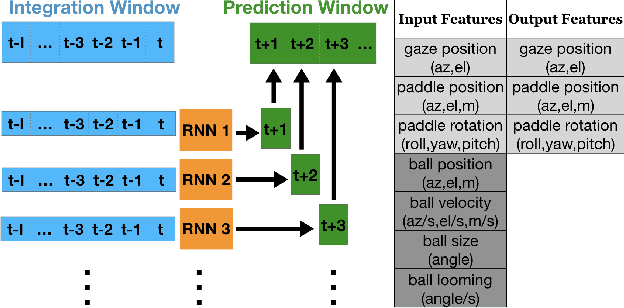
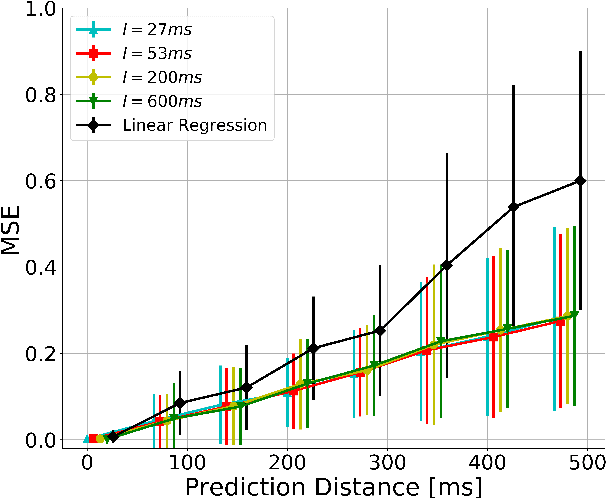
Theories for visually guided action account for online control in the presence of reliable sources of visual information, and predictive control to compensate for visuomotor delay and temporary occlusion. In this study, we characterize the temporal relationship between information integration window and prediction distance using computational models. Subjects were immersed in a simulated environment and attempted to catch virtual balls that were transiently "blanked" during flight. Recurrent neural networks were trained to reproduce subject's gaze and hand movements during blank. The models successfully predict gaze behavior within 3 degrees, and hand movements within 8.5 cm as far as 500 ms in time, with integration window as short as 27 ms. Furthermore, we quantified the contribution of each input source of information to motor output through an ablation study. The model is a proof of concept for prediction as a discrete mapping between information integrated over time and a temporally distant motor output.
Algorithms for Semantic Segmentation of Multispectral Remote Sensing Imagery using Deep Learning
May 01, 2018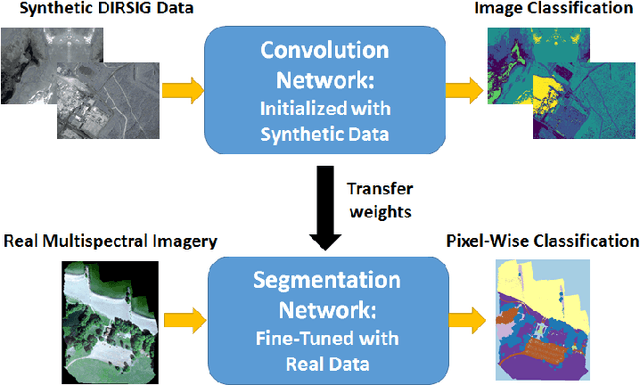
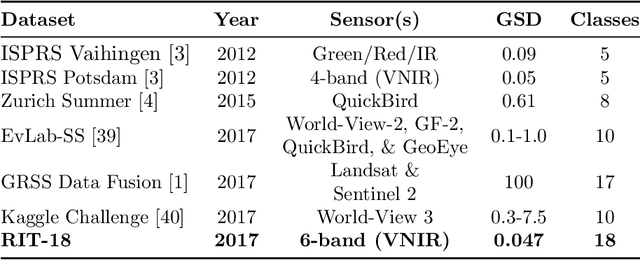
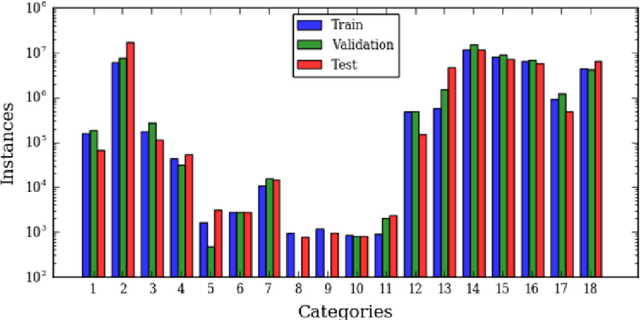

Deep convolutional neural networks (DCNNs) have been used to achieve state-of-the-art performance on many computer vision tasks (e.g., object recognition, object detection, semantic segmentation) thanks to a large repository of annotated image data. Large labeled datasets for other sensor modalities, e.g., multispectral imagery (MSI), are not available due to the large cost and manpower required. In this paper, we adapt state-of-the-art DCNN frameworks in computer vision for semantic segmentation for MSI imagery. To overcome label scarcity for MSI data, we substitute real MSI for generated synthetic MSI in order to initialize a DCNN framework. We evaluate our network initialization scheme on the new RIT-18 dataset that we present in this paper. This dataset contains very-high resolution MSI collected by an unmanned aircraft system. The models initialized with synthetic imagery were less prone to over-fitting and provide a state-of-the-art baseline for future work.
* 45 pages
EarthMapper: A Tool Box for the Semantic Segmentation of Remote Sensing Imagery
Apr 01, 2018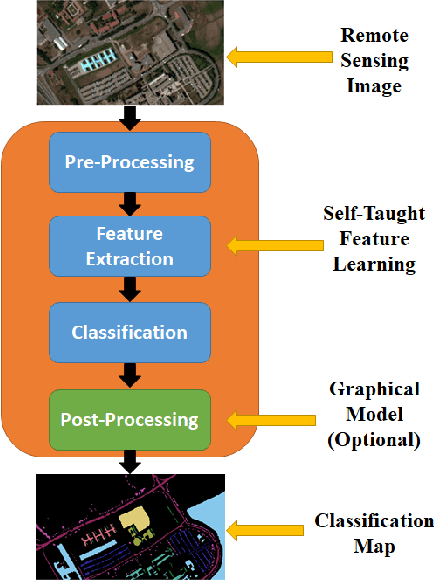
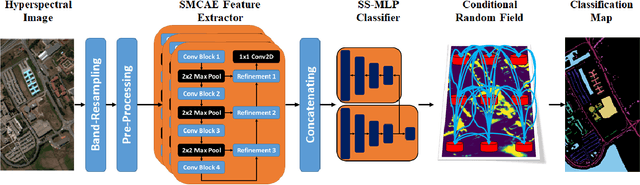
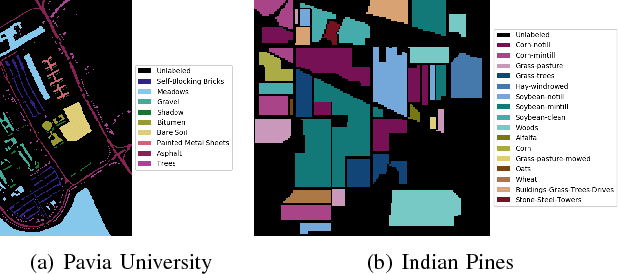
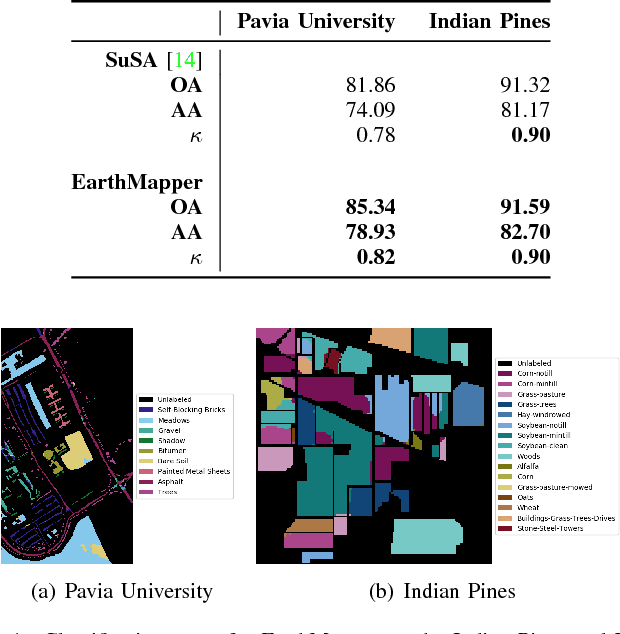
Deep learning continues to push state-of-the-art performance for the semantic segmentation of color (i.e., RGB) imagery; however, the lack of annotated data for many remote sensing sensors (i.e. hyperspectral imagery (HSI)) prevents researchers from taking advantage of this recent success. Since generating sensor specific datasets is time intensive and cost prohibitive, remote sensing researchers have embraced deep unsupervised feature extraction. Although these methods have pushed state-of-the-art performance on current HSI benchmarks, many of these tools are not readily accessible to many researchers. In this letter, we introduce a software pipeline, which we call EarthMapper, for the semantic segmentation of non-RGB remote sensing imagery. It includes self-taught spatial-spectral feature extraction, various standard and deep learning classifiers, and undirected graphical models for post-processing. We evaluated EarthMapper on the Indian Pines and Pavia University datasets and have released this code for public use.
DVQA: Understanding Data Visualizations via Question Answering
Mar 29, 2018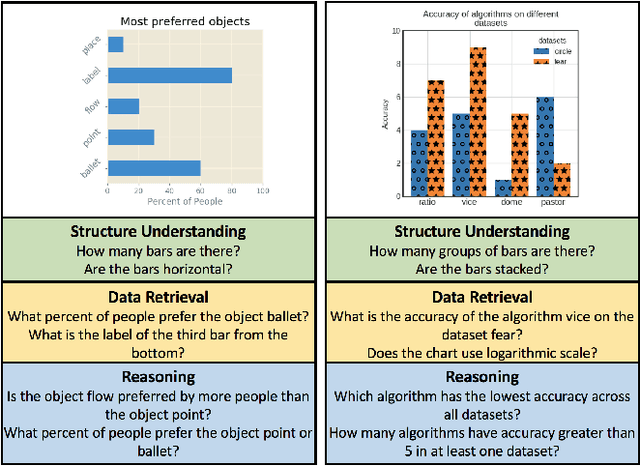
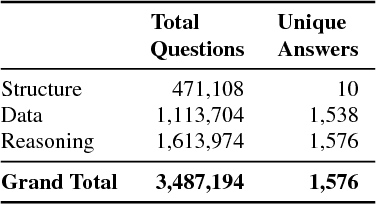
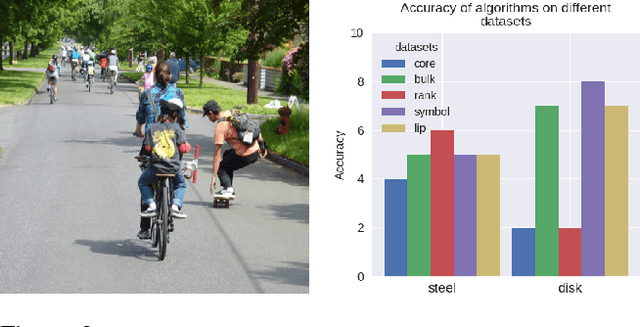
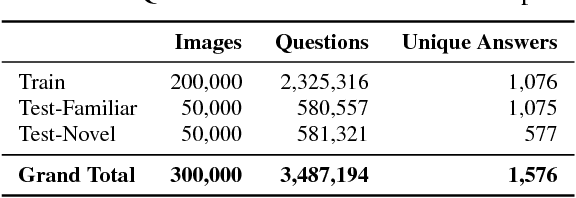
Bar charts are an effective way to convey numeric information, but today's algorithms cannot parse them. Existing methods fail when faced with even minor variations in appearance. Here, we present DVQA, a dataset that tests many aspects of bar chart understanding in a question answering framework. Unlike visual question answering (VQA), DVQA requires processing words and answers that are unique to a particular bar chart. State-of-the-art VQA algorithms perform poorly on DVQA, and we propose two strong baselines that perform considerably better. Our work will enable algorithms to automatically extract numeric and semantic information from vast quantities of bar charts found in scientific publications, Internet articles, business reports, and many other areas.
Low-Shot Learning for the Semantic Segmentation of Remote Sensing Imagery
Mar 26, 2018
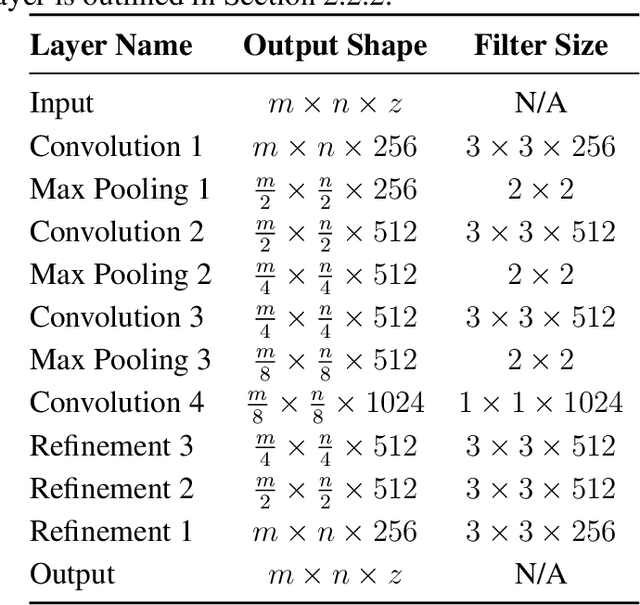
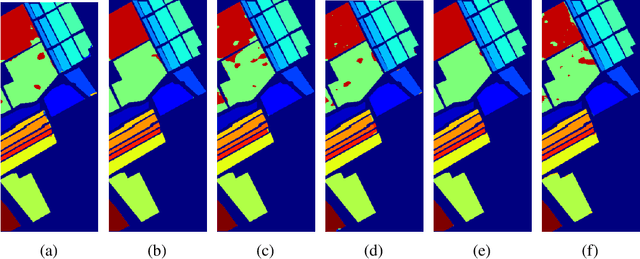
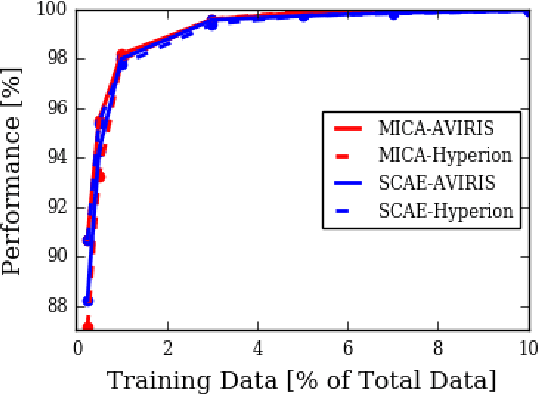
Recent advances in computer vision using deep learning with RGB imagery (e.g., object recognition and detection) have been made possible thanks to the development of large annotated RGB image datasets. In contrast, multispectral image (MSI) and hyperspectral image (HSI) datasets contain far fewer labeled images, in part due to the wide variety of sensors used. These annotations are especially limited for semantic segmentation, or pixel-wise classification, of remote sensing imagery because it is labor intensive to generate image annotations. Low-shot learning algorithms can make effective inferences despite smaller amounts of annotated data. In this paper, we study low-shot learning using self-taught feature learning for semantic segmentation. We introduce 1) an improved self-taught feature learning framework for HSI and MSI data and 2) a semi-supervised classification algorithm. When these are combined, they achieve state-of-the-art performance on remote sensing datasets that have little annotated training data available. These low-shot learning frameworks will reduce the manual image annotation burden and improve semantic segmentation performance for remote sensing imagery.