 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountTRuCoLa: Rule Confidence Learning for Temporal Knowledge Graph Forecasting
Sep 11, 2025We address the task of temporal knowledge graph (TKG) forecasting by introducing a fully explainable method based on temporal rules. Motivated by recent work proposing a strong baseline using recurrent facts, our approach learns four simple types of rules with a confidence function that considers both recency and frequency. Evaluated on nine datasets, our method matches or surpasses the performance of eight state-of-the-art models and two baselines, while providing fully interpretable predictions.
A*Net and NBFNet Learn Negative Patterns on Knowledge Graphs
Dec 06, 2024In this technical report, we investigate the predictive performance differences of a rule-based approach and the GNN architectures NBFNet and A*Net with respect to knowledge graph completion. For the two most common benchmarks, we find that a substantial fraction of the performance difference can be explained by one unique negative pattern on each dataset that is hidden from the rule-based approach. Our findings add a unique perspective on the performance difference of different model classes for knowledge graph completion: Models can achieve a predictive performance advantage by penalizing scores of incorrect facts opposed to providing high scores for correct facts.
Reevaluation of Inductive Link Prediction
Sep 30, 2024Within this paper, we show that the evaluation protocol currently used for inductive link prediction is heavily flawed as it relies on ranking the true entity in a small set of randomly sampled negative entities. Due to the limited size of the set of negatives, a simple rule-based baseline can achieve state-of-the-art results, which simply ranks entities higher based on the validity of their type. As a consequence of these insights, we reevaluate current approaches for inductive link prediction on several benchmarks using the link prediction protocol usually applied to the transductive setting. As some inductive methods suffer from scalability issues when evaluated in this setting, we propose and apply additionally an improved sampling protocol, which does not suffer from the problem mentioned above. The results of our evaluation differ drastically from the results reported in so far.
* Published in RuleML+RR 2024
History repeats Itself: A Baseline for Temporal Knowledge Graph Forecasting
Apr 29, 2024



Temporal Knowledge Graph (TKG) Forecasting aims at predicting links in Knowledge Graphs for future timesteps based on a history of Knowledge Graphs. To this day, standardized evaluation protocols and rigorous comparison across TKG models are available, but the importance of simple baselines is often neglected in the evaluation, which prevents researchers from discerning actual and fictitious progress. We propose to close this gap by designing an intuitive baseline for TKG Forecasting based on predicting recurring facts. Compared to most TKG models, it requires little hyperparameter tuning and no iterative training. Further, it can help to identify failure modes in existing approaches. The empirical findings are quite unexpected: compared to 11 methods on five datasets, our baseline ranks first or third in three of them, painting a radically different picture of the predictive quality of the state of the art.
On the Aggregation of Rules for Knowledge Graph Completion
Sep 01, 2023



Rule learning approaches for knowledge graph completion are efficient, interpretable and competitive to purely neural models. The rule aggregation problem is concerned with finding one plausibility score for a candidate fact which was simultaneously predicted by multiple rules. Although the problem is ubiquitous, as data-driven rule learning can result in noisy and large rulesets, it is underrepresented in the literature and its theoretical foundations have not been studied before in this context. In this work, we demonstrate that existing aggregation approaches can be expressed as marginal inference operations over the predicting rules. In particular, we show that the common Max-aggregation strategy, which scores candidates based on the rule with the highest confidence, has a probabilistic interpretation. Finally, we propose an efficient and overlooked baseline which combines the previous strategies and is competitive to computationally more expensive approaches.
SAFRAN: An interpretable, rule-based link prediction method outperforming embedding models
Sep 16, 2021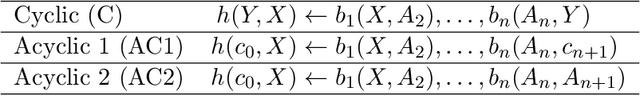

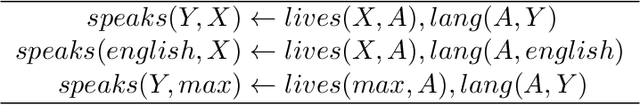
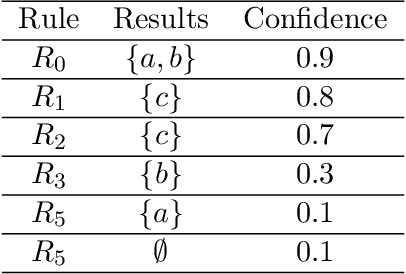
Neural embedding-based machine learning models have shown promise for predicting novel links in knowledge graphs. Unfortunately, their practical utility is diminished by their lack of interpretability. Recently, the fully interpretable, rule-based algorithm AnyBURL yielded highly competitive results on many general-purpose link prediction benchmarks. However, current approaches for aggregating predictions made by multiple rules are affected by redundancies. We improve upon AnyBURL by introducing the SAFRAN rule application framework, which uses a novel aggregation approach called Non-redundant Noisy-OR that detects and clusters redundant rules prior to aggregation. SAFRAN yields new state-of-the-art results for fully interpretable link prediction on the established general-purpose benchmarks FB15K-237, WN18RR and YAGO3-10. Furthermore, it exceeds the results of multiple established embedding-based algorithms on FB15K-237 and WN18RR and narrows the gap between rule-based and embedding-based algorithms on YAGO3-10.
Scalable and interpretable rule-based link prediction for large heterogeneous knowledge graphs
Dec 10, 2020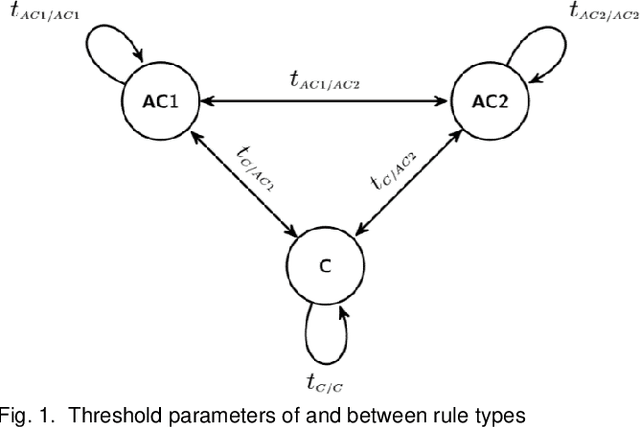


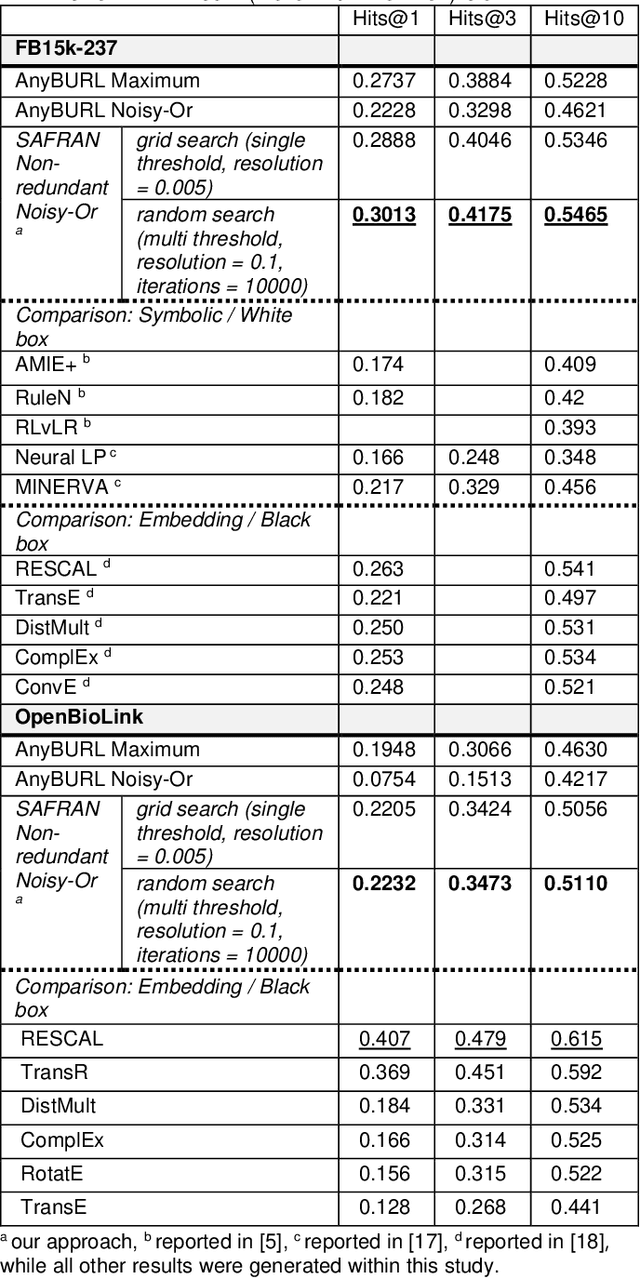
Neural embedding-based machine learning models have shown promise for predicting novel links in biomedical knowledge graphs. Unfortunately, their practical utility is diminished by their lack of interpretability. Recently, the fully interpretable, rule-based algorithm AnyBURL yielded highly competitive results on many general-purpose link prediction benchmarks. However, its applicability to large-scale prediction tasks on complex biomedical knowledge bases is limited by long inference times and difficulties with aggregating predictions made by multiple rules. We improve upon AnyBURL by introducing the SAFRAN rule application framework which aggregates rules through a scalable clustering algorithm. SAFRAN yields new state-of-the-art results for fully interpretable link prediction on the established general-purpose benchmark FB15K-237 and the large-scale biomedical benchmark OpenBioLink. Furthermore, it exceeds the results of multiple established embedding-based algorithms on FB15K-237 and narrows the gap between rule-based and embedding-based algorithms on OpenBioLink. We also show that SAFRAN increases inference speeds by up to two orders of magnitude.
Reinforced Anytime Bottom Up Rule Learning for Knowledge Graph Completion
Apr 09, 2020

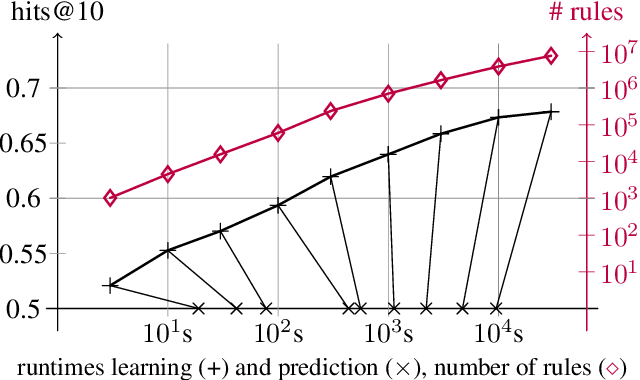
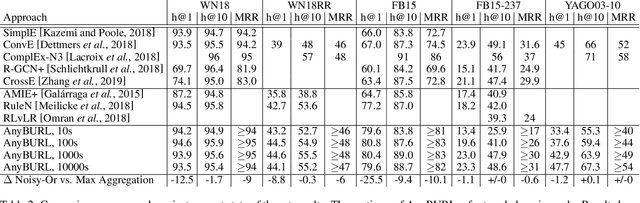
Most of todays work on knowledge graph completion is concerned with sub-symbolic approaches that focus on the concept of embedding a given graph in a low dimensional vector space. Against this trend, we propose an approach called AnyBURL that is rooted in the symbolic space. Its core algorithm is based on sampling paths, which are generalized into Horn rules. Previously published results show that the prediction quality of AnyBURL is on the same level as current state of the art with the additional benefit of offering an explanation for the predicted fact. In this paper, we are concerned with two extensions of AnyBURL. Firstly, we change AnyBURLs interpretation of rules from $\Theta$-subsumption into $\Theta$-subsumption under Object Identity. Secondly, we introduce reinforcement learning to better guide the sampling process. We found out that reinforcement learning helps finding more valuable rules earlier in the search process. We measure the impact of both extensions and compare the resulting approach with current state of the art approaches. Our results show that AnyBURL outperforms most sub-symbolic methods.
Do Embedding Models Perform Well for Knowledge Base Completion?
Nov 06, 2018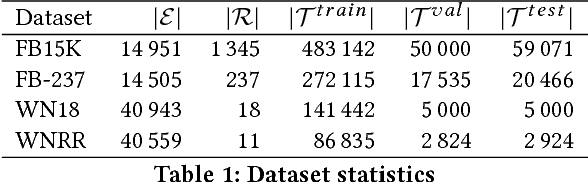
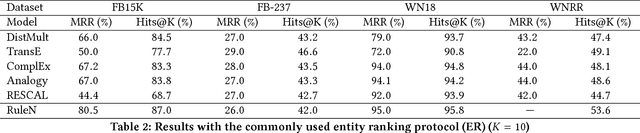
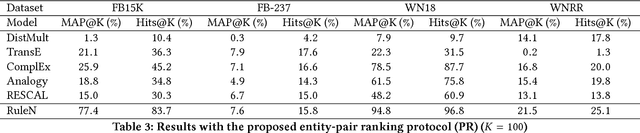
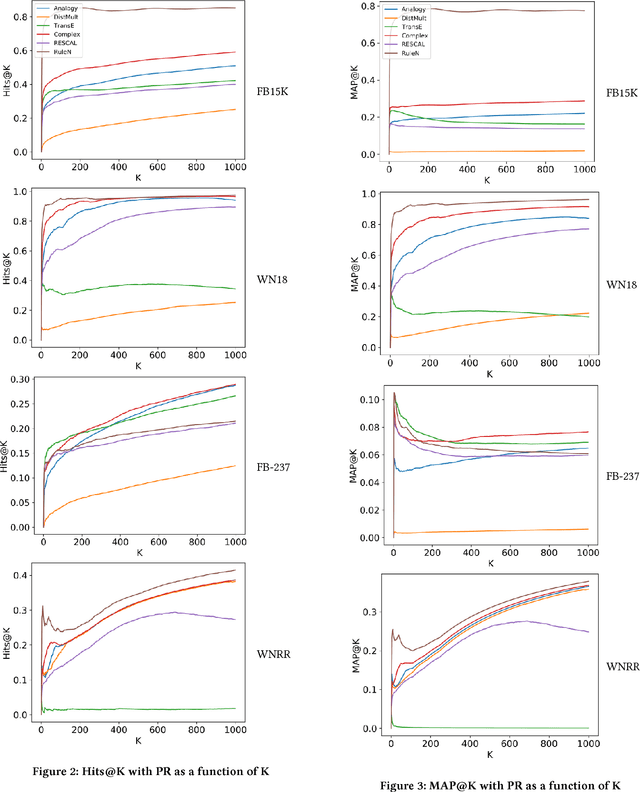
In this work, we put into question the effectiveness of the evaluation methods currently used to measure the performance of latent factor models for the task of knowledge base completion. We argue that by focusing on a small subset of possible facts in the knowledge base, current evaluation practices are better suited for question answering tasks, rather than knowledge base completion, where it is also important to avoid the addition of incorrect facts into the knowledge base. We illustrate our point by showing how models with limited expressiveness achieve state-of-the-art performance, even while adding many incorrect (even nonsensical) facts to a knowledge base. Finally, we show that when using a simple evaluation procedure designed to also penalize the addition of incorrect facts, the general and relative performance of all models looks very different than previously seen. This indicates the need for more powerful latent factor models for the task of knowledge base completion.
Using Abduction in Markov Logic Networks for Root Cause Analysis
Nov 18, 2015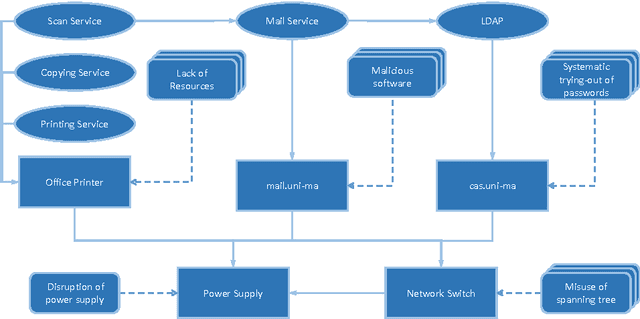
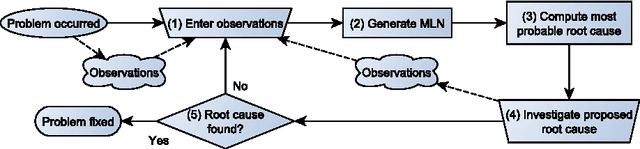
IT infrastructure is a crucial part in most of today's business operations. High availability and reliability, and short response times to outages are essential. Thus a high amount of tool support and automation in risk management is desirable to decrease outages. We propose a new approach for calculating the root cause for an observed failure in an IT infrastructure. Our approach is based on Abduction in Markov Logic Networks. Abduction aims to find an explanation for a given observation in the light of some background knowledge. In failure diagnosis, the explanation corresponds to the root cause, the observation to the failure of a component, and the background knowledge to the dependency graph extended by potential risks. We apply a method to extend a Markov Logic Network in order to conduct abductive reasoning, which is not naturally supported in this formalism. Our approach exhibits a high amount of reusability and enables users without specific knowledge of a concrete infrastructure to gain viable insights in the case of an incident. We implemented the method in a tool and illustrate its suitability for root cause analysis by applying it to a sample scenario.