 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI for Autonomous Driving: A Review
May 21, 2025Generative AI (GenAI) is rapidly advancing the field of Autonomous Driving (AD), extending beyond traditional applications in text, image, and video generation. We explore how generative models can enhance automotive tasks, such as static map creation, dynamic scenario generation, trajectory forecasting, and vehicle motion planning. By examining multiple generative approaches ranging from Variational Autoencoder (VAEs) over Generative Adversarial Networks (GANs) and Invertible Neural Networks (INNs) to Generative Transformers (GTs) and Diffusion Models (DMs), we highlight and compare their capabilities and limitations for AD-specific applications. Additionally, we discuss hybrid methods integrating conventional techniques with generative approaches, and emphasize their improved adaptability and robustness. We also identify relevant datasets and outline open research questions to guide future developments in GenAI. Finally, we discuss three core challenges: safety, interpretability, and realtime capabilities, and present recommendations for image generation, dynamic scenario generation, and planning.
Closing the Loop: Motion Prediction Models beyond Open-Loop Benchmarks
May 08, 2025Fueled by motion prediction competitions and benchmarks, recent years have seen the emergence of increasingly large learning based prediction models, many with millions of parameters, focused on improving open-loop prediction accuracy by mere centimeters. However, these benchmarks fail to assess whether such improvements translate to better performance when integrated into an autonomous driving stack. In this work, we systematically evaluate the interplay between state-of-the-art motion predictors and motion planners. Our results show that higher open-loop accuracy does not always correlate with better closed-loop driving behavior and that other factors, such as temporal consistency of predictions and planner compatibility, also play a critical role. Furthermore, we investigate downsized variants of these models, and, surprisingly, find that in some cases models with up to 86% fewer parameters yield comparable or even superior closed-loop driving performance. Our code is available at https://github.com/continental/pred2plan.
Uncertainty-Aware Trajectory Prediction via Rule-Regularized Heteroscedastic Deep Classification
Apr 17, 2025



Deep learning-based trajectory prediction models have demonstrated promising capabilities in capturing complex interactions. However, their out-of-distribution generalization remains a significant challenge, particularly due to unbalanced data and a lack of enough data and diversity to ensure robustness and calibration. To address this, we propose SHIFT (Spectral Heteroscedastic Informed Forecasting for Trajectories), a novel framework that uniquely combines well-calibrated uncertainty modeling with informative priors derived through automated rule extraction. SHIFT reformulates trajectory prediction as a classification task and employs heteroscedastic spectral-normalized Gaussian processes to effectively disentangle epistemic and aleatoric uncertainties. We learn informative priors from training labels, which are automatically generated from natural language driving rules, such as stop rules and drivability constraints, using a retrieval-augmented generation framework powered by a large language model. Extensive evaluations over the nuScenes dataset, including challenging low-data and cross-location scenarios, demonstrate that SHIFT outperforms state-of-the-art methods, achieving substantial gains in uncertainty calibration and displacement metrics. In particular, our model excels in complex scenarios, such as intersections, where uncertainty is inherently higher. Project page: https://kumarmanas.github.io/SHIFT/.
* 17 Pages, 9 figures. Accepted to Robotics: Science and Systems(RSS), 2025
Informed Spectral Normalized Gaussian Processes for Trajectory Prediction
Mar 18, 2024



Prior parameter distributions provide an elegant way to represent prior expert and world knowledge for informed learning. Previous work has shown that using such informative priors to regularize probabilistic deep learning (DL) models increases their performance and data-efficiency. However, commonly used sampling-based approximations for probabilistic DL models can be computationally expensive, requiring multiple inference passes and longer training times. Promising alternatives are compute-efficient last layer kernel approximations like spectral normalized Gaussian processes (SNGPs). We propose a novel regularization-based continual learning method for SNGPs, which enables the use of informative priors that represent prior knowledge learned from previous tasks. Our proposal builds upon well-established methods and requires no rehearsal memory or parameter expansion. We apply our informed SNGP model to the trajectory prediction problem in autonomous driving by integrating prior drivability knowledge. On two public datasets, we investigate its performance under diminishing training data and across locations, and thereby demonstrate an increase in data-efficiency and robustness to location-transfers over non-informed and informed baselines.
Informed Priors for Knowledge Integration in Trajectory Prediction
Nov 01, 2022Informed machine learning methods allow the integration of prior knowledge into learning systems. This can increase accuracy and robustness or reduce data needs. However, existing methods often assume hard constraining knowledge, that does not require to trade-off prior knowledge with observations, but can be used to directly reduce the problem space. Other approaches use specific, architectural changes as representation of prior knowledge, limiting applicability. We propose an informed machine learning method, based on continual learning. This allows the integration of arbitrary, prior knowledge, potentially from multiple sources, and does not require specific architectures. Furthermore, our approach enables probabilistic and multi-modal predictions, that can improve predictive accuracy and robustness. We exemplify our approach by applying it to a state-of-the-art trajectory predictor for autonomous driving. This domain is especially dependent on informed learning approaches, as it is subject to an overwhelming large variety of possible environments and very rare events, while requiring robust and accurate predictions. We evaluate our model on a commonly used benchmark dataset, only using data already available in a conventional setup. We show that our method outperforms both non-informed and informed learning methods, that are often used in the literature. Furthermore, we are able to compete with a conventional baseline, even using half as many observation examples.
Flexible development and evaluation of machine-learning-supported optimal control and estimation methods via HILO-MPC
Mar 25, 2022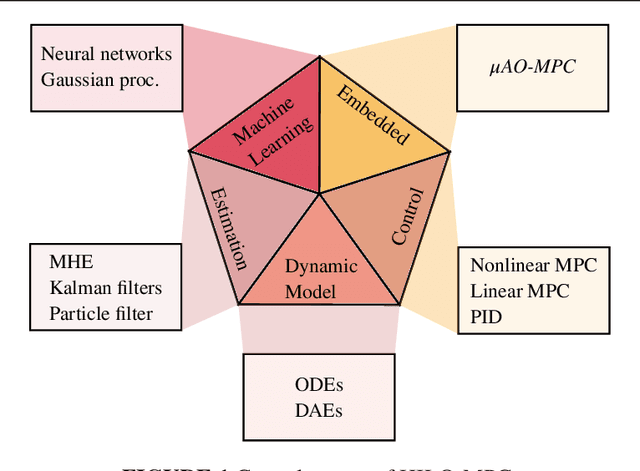

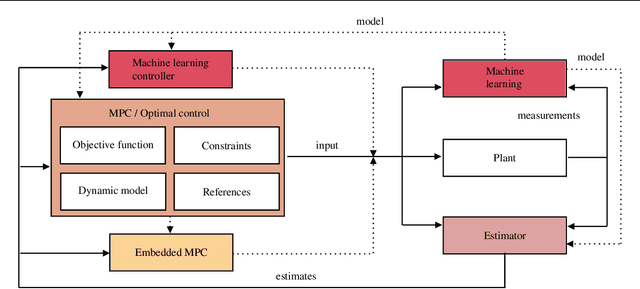
Model-based optimization approaches for monitoring and control, such as model predictive control and optimal state and parameter estimation, have been used for decades in many engineering applications. Models describing the dynamics, constraints, and desired performance criteria are fundamental to model-based approaches. Thanks to recent technological advancements in digitalization, machine learning methods such as deep learning, and computing power, there has been an increasing interest in using machine learning methods alongside model-based approaches for control and estimation. The number of new methods and theoretical findings using machine learning for model-based control and optimization is increasing rapidly. This paper outlines the basic ideas and principles behind an easy-to-use Python toolbox that allows to quickly and efficiently solve machine-learning-supported optimization, model predictive control, and estimation problems. The toolbox leverages state-of-the-art machine learning libraries to train components used to define the problem. It allows to efficiently solve the resulting optimization problems. Machine learning can be used for a broad spectrum of tasks, ranging from model predictive control for stabilization, setpoint tracking, path following, and trajectory tracking to moving horizon estimation and Kalman filtering. For linear systems, it enables quick code generation for embedded MPC applications. HILO-MPC is flexible and adaptable, making it especially suitable for research and fundamental development tasks. Due to its simplicity and numerous already implemented examples, it is also a powerful teaching tool. The usability is underlined, presenting a series of application examples.