 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Theoretical Understanding of the Robustness of Variational Autoencoders
Jul 14, 2020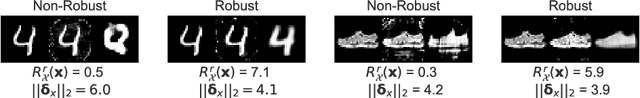

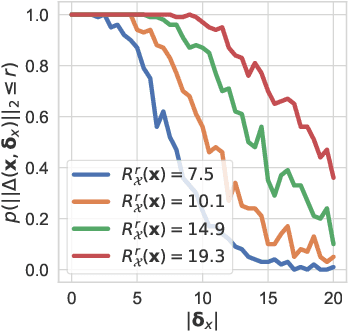
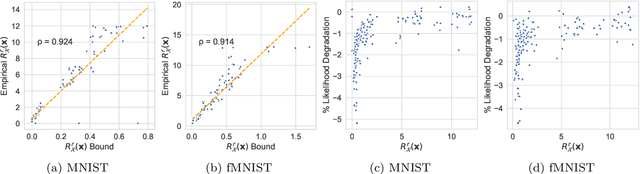
We make inroads into understanding the robustness of Variational Autoencoders (VAEs) to adversarial attacks and other input perturbations. While previous work has developed algorithmic approaches to attacking and defending VAEs, there remains a lack of formalization for what it means for a VAE to be robust. To address this, we develop a novel criterion for robustness in probabilistic models: $r$-robustness. We then use this to construct the first theoretical results for the robustness of VAEs, deriving margins in the input space for which we can provide guarantees about the resulting reconstruction. Informally, we are able to define a region within which any perturbation will produce a reconstruction that is similar to the original reconstruction. To support our analysis, we show that VAEs trained using disentangling methods not only score well under our robustness metrics, but that the reasons for this can be interpreted through our theoretical results.
Relaxed-Responsibility Hierarchical Discrete VAEs
Jul 14, 2020
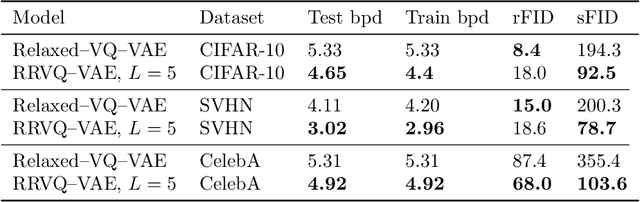
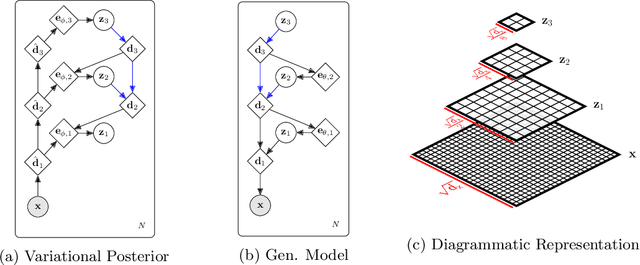

Successfully training Variational Autoencoders (VAEs) with a hierarchy of discrete latent variables remains an area of active research. Leveraging insights from classical methods of inference we introduce $\textit{Relaxed-Responsibility Vector-Quantisation}$, a novel way to parameterise discrete latent variables, a refinement of relaxed Vector-Quantisation. This enables a novel approach to hierarchical discrete variational autoencoder with numerous layers of latent variables that we train end-to-end. Unlike discrete VAEs with a single layer of latent variables, we can produce realistic-looking samples by ancestral sampling: it is not essential to train a second generative model over the learnt latent representations to then sample from and then decode. Further, we observe different layers of our model become associated with different aspects of the data.
Inferring proximity from Bluetooth Low Energy RSSI with Unscented Kalman Smoothers
Jul 09, 2020
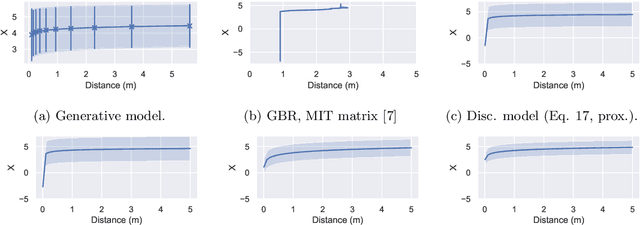
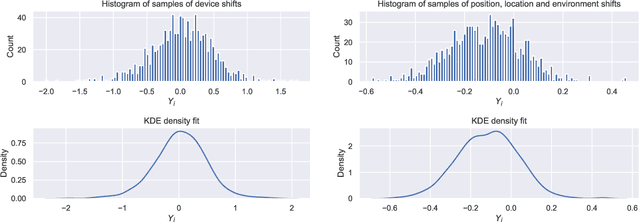
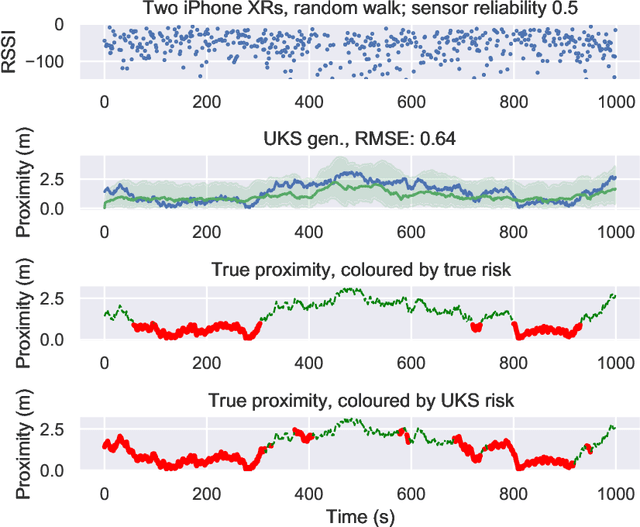
The Covid-19 pandemic has resulted in a variety of approaches for managing infection outbreaks in international populations. One example is mobile phone applications, which attempt to alert infected individuals and their contacts by automatically inferring two key components of infection risk: the proximity to an individual who may be infected, and the duration of proximity. The former component, proximity, relies on Bluetooth Low Energy (BLE) Received Signal Strength Indicator(RSSI) as a distance sensor, and this has been shown to be problematic; not least because of unpredictable variations caused by different device types, device location on-body, device orientation, the local environment and the general noise associated with radio frequency propagation. In this paper, we present an approach that infers posterior probabilities over distance given sequences of RSSI values. Using a single-dimensional Unscented Kalman Smoother (UKS) for non-linear state space modelling, we outline several Gaussian process observation transforms, including: a generative model that directly captures sources of variation; and a discriminative model that learns a suitable observation function from training data using both distance and infection risk as optimisation objective functions. Our results show that good risk prediction can be achieved in $\mathcal{O}(n)$ time on real-world data sets, with the UKS outperforming more traditional classification methods learned from the same training data.
Neural Ensemble Search for Performant and Calibrated Predictions
Jun 15, 2020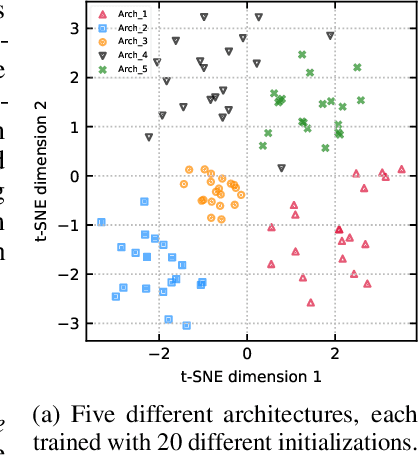
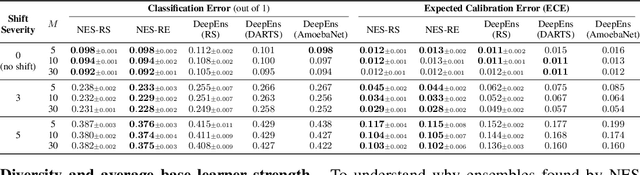


Ensembles of neural networks achieve superior performance compared to stand-alone networks not only in terms of accuracy on in-distribution data but also on data with distributional shift alongside improved uncertainty calibration. Diversity among networks in an ensemble is believed to be key for building strong ensembles, but typical approaches only ensemble different weight vectors of a fixed architecture. Instead, we investigate neural architecture search (NAS) for explicitly constructing ensembles to exploit diversity among networks of varying architectures and to achieve robustness against distributional shift. By directly optimizing ensemble performance, our methods implicitly encourage diversity among networks, without the need to explicitly define diversity. We find that the resulting ensembles are more diverse compared to ensembles composed of a fixed architecture and are therefore also more powerful. We show significant improvements in ensemble performance on image classification tasks both for in-distribution data and during distributional shift with better uncertainty calibration.
Learning Bijective Feature Maps for Linear ICA
Feb 19, 2020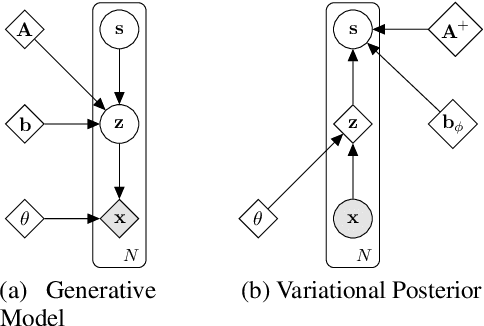
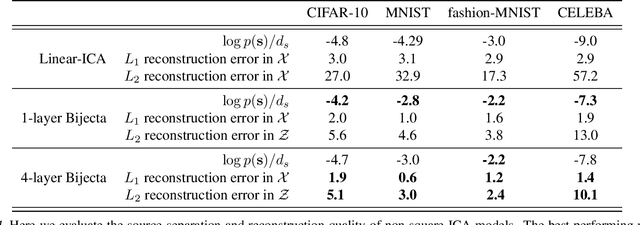

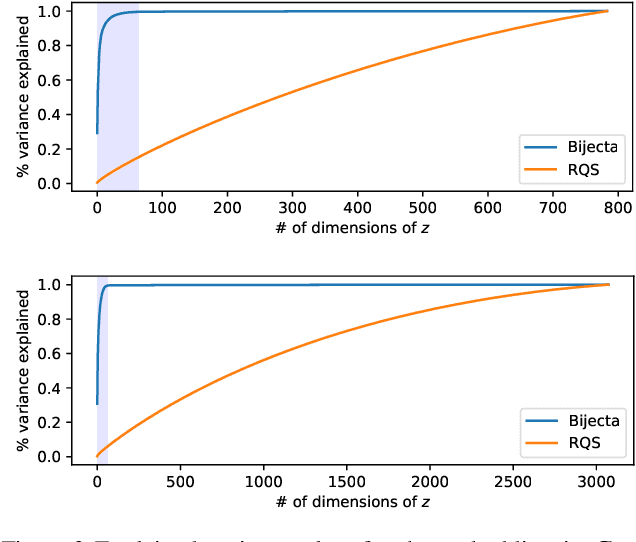
Separating high-dimensional data like images into independent latent factors remains an open research problem. Here we develop a method that jointly learns a linear independent component analysis (ICA) model with non-linear bijective feature maps. By combining these two methods, ICA can learn interpretable latent structure for images. For non-square ICA, where we assume the number of sources is less than the dimensionality of data, we achieve better unsupervised latent factor discovery than flow-based models and linear ICA. This performance scales to large image datasets such as CelebA.
Regularising Deep Networks with Deep Generative Models
Oct 11, 2019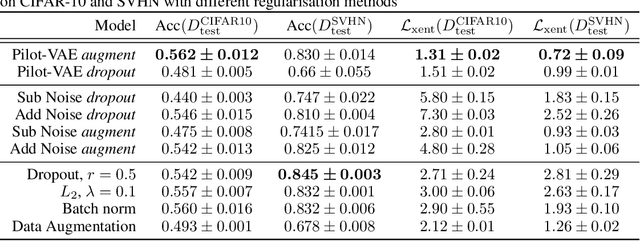
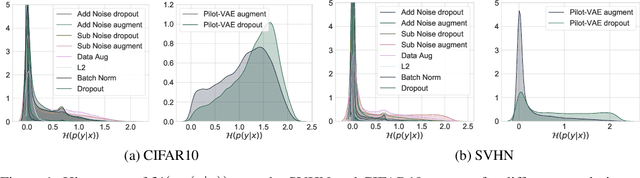
We develop a new method for regularising neural networks. We learn a probability distribution over the activations of all layers of the model and then insert imputed values into the network during training. We obtain a posterior for an arbitrary subset of activations conditioned on the remainder. This is a generalisation of data augmentation to the hidden layers of a network, and a form of data-aware dropout. We demonstrate that our training method leads to higher test accuracy and lower test-set cross-entropy for neural networks trained on CIFAR-10 and SVHN compared to standard regularisation baselines: our approach leads to networks with better calibrated uncertainty over the class posteriors all the while delivering greater test-set accuracy.
Disentangling to Cluster: Gaussian Mixture Variational Ladder Autoencoders
Sep 25, 2019


In clustering we normally output one cluster variable for each datapoint. However it is not necessarily the case that there is only one way to partition a given dataset into cluster components. For example, one could cluster objects by their colour, or by their type. Different attributes form a hierarchy, and we could wish to cluster in any of them. By disentangling the learnt latent representations of some dataset into different layers for different attributes we can then cluster in those latent spaces. We call this "disentangled clustering". Extending Variational Ladder Autoencoders (Zhao et al., 2017), we propose a clustering algorithm, VLAC, that outperforms a Gaussian Mixture DGM in cluster accuracy over digit identity on the test set of SVHN. We also demonstrate learning clusters jointly over numerous layers of the hierarchy of latent variables for the data, and show component-wise generation from this hierarchical model.
Disentangling Improves VAEs' Robustness to Adversarial Attacks
Jun 01, 2019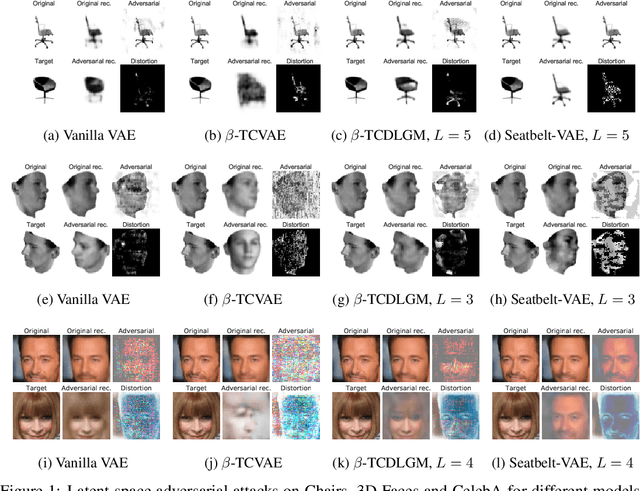

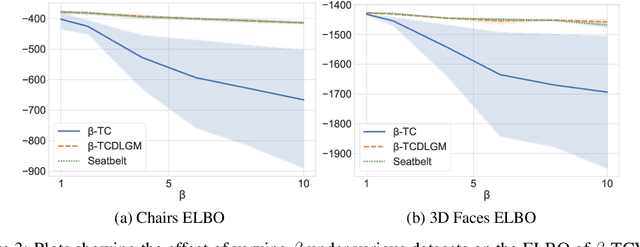

This paper is concerned with the robustness of VAEs to adversarial attacks. We highlight that conventional VAEs are brittle under attack but that methods recently introduced for disentanglement such as $\beta$-TCVAE (Chen et al., 2018) improve robustness, as demonstrated through a variety of previously proposed adversarial attacks (Tabacof et al. (2016); Gondim-Ribeiro et al. (2018); Kos et al.(2018)). This motivated us to develop Seatbelt-VAE, a new hierarchical disentangled VAE that is designed to be significantly more robust to adversarial attacks than existing approaches, while retaining high quality reconstructions.
On the marginal likelihood and cross-validation
May 21, 2019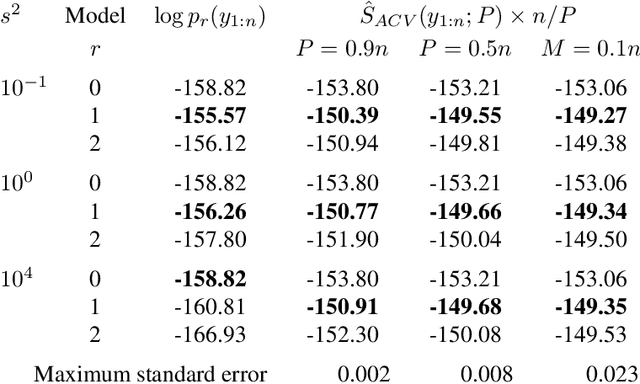
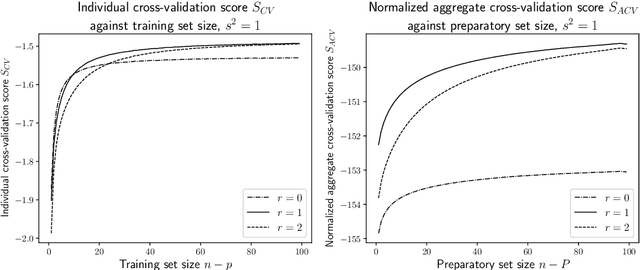
In Bayesian statistics, the marginal likelihood, also known as the evidence, is used to evaluate model fit as it quantifies the joint probability of the data under the prior. In contrast, non-Bayesian models are typically compared using cross-validation on held-out data, either through $k$-fold partitioning or leave-$p$-out subsampling. We show that the marginal likelihood is formally equivalent to exhaustive leave-$p$-out cross-validation averaged over all values of $p$ and all held-out test sets when using the log posterior predictive probability as the scoring rule. Moreover, the log posterior predictive is the only coherent scoring rule under data exchangeability. This offers new insight into the marginal likelihood and cross-validation and highlights the potential sensitivity of the marginal likelihood to the setting of the prior. We suggest an alternative approach using aggregate cross-validation following a preparatory training phase. Our work has connections to prequential analysis and intrinsic Bayes factors but is motivated through a different course.
Scalable Nonparametric Sampling from Multimodal Posteriors with the Posterior Bootstrap
Feb 08, 2019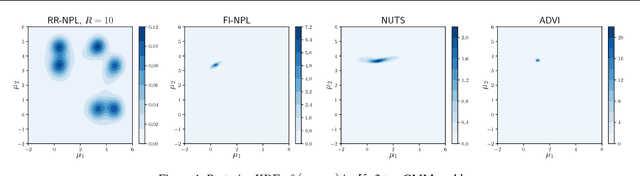
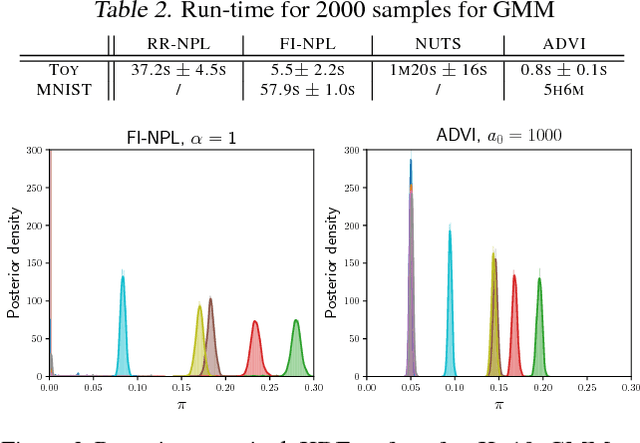
Increasingly complex datasets pose a number of challenges for Bayesian inference. Conventional posterior sampling based on Markov chain Monte Carlo can be too computationally intensive, is serial in nature and mixes poorly between posterior modes. Further, all models are misspecified, which brings into question the validity of the conventional Bayesian update. We present a scalable Bayesian nonparametric learning routine that enables posterior sampling through the optimization of suitably randomized objective functions. A Dirichlet process prior on the unknown data distribution accounts for model misspecification, and admits an embarrassingly parallel posterior bootstrap algorithm that generates independent and exact samples from the nonparametric posterior distribution. Our method is particularly adept at sampling from multimodal posterior distributions via a random restart mechanism. We demonstrate our method on Gaussian mixture model and sparse logistic regression examples.