 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA large-scale and PCR-referenced vocal audio dataset for COVID-19
Dec 15, 2022The UK COVID-19 Vocal Audio Dataset is designed for the training and evaluation of machine learning models that classify SARS-CoV-2 infection status or associated respiratory symptoms using vocal audio. The UK Health Security Agency recruited voluntary participants through the national Test and Trace programme and the REACT-1 survey in England from March 2021 to March 2022, during dominant transmission of the Alpha and Delta SARS-CoV-2 variants and some Omicron variant sublineages. Audio recordings of volitional coughs, exhalations, and speech were collected in the 'Speak up to help beat coronavirus' digital survey alongside demographic, self-reported symptom and respiratory condition data, and linked to SARS-CoV-2 test results. The UK COVID-19 Vocal Audio Dataset represents the largest collection of SARS-CoV-2 PCR-referenced audio recordings to date. PCR results were linked to 70,794 of 72,999 participants and 24,155 of 25,776 positive cases. Respiratory symptoms were reported by 45.62% of participants. This dataset has additional potential uses for bioacoustics research, with 11.30% participants reporting asthma, and 27.20% with linked influenza PCR test results.
Density Estimation with Autoregressive Bayesian Predictives
Jun 13, 2022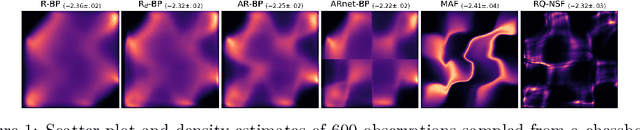
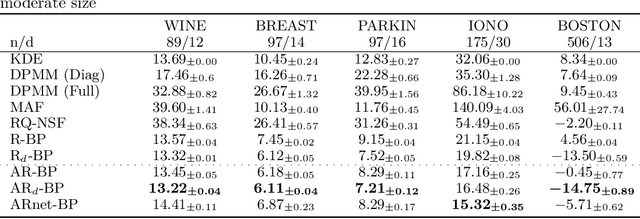
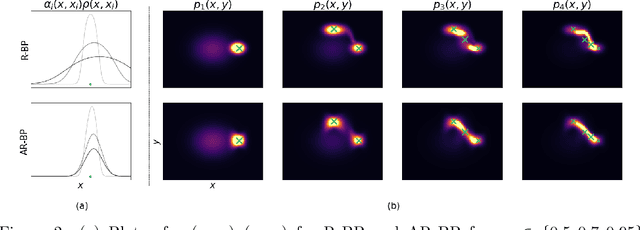
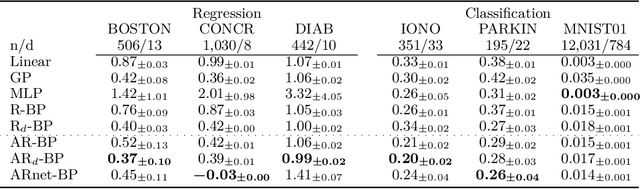
Bayesian methods are a popular choice for statistical inference in small-data regimes due to the regularization effect induced by the prior, which serves to counteract overfitting. In the context of density estimation, the standard Bayesian approach is to target the posterior predictive. In general, direct estimation of the posterior predictive is intractable and so methods typically resort to approximating the posterior distribution as an intermediate step. The recent development of recursive predictive copula updates, however, has made it possible to perform tractable predictive density estimation without the need for posterior approximation. Although these estimators are computationally appealing, they tend to struggle on non-smooth data distributions. This is largely due to the comparatively restrictive form of the likelihood models from which the proposed copula updates were derived. To address this shortcoming, we consider a Bayesian nonparametric model with an autoregressive likelihood decomposition and Gaussian process prior, which yields a data-dependent bandwidth parameter in the copula update. Further, we formulate a novel parameterization of the bandwidth using an autoregressive neural network that maps the data into a latent space, and is thus able to capture more complex dependencies in the data. Our extensions increase the modelling capacity of existing recursive Bayesian density estimators, achieving state-of-the-art results on tabular data sets.
Neural Score Matching for High-Dimensional Causal Inference
Mar 01, 2022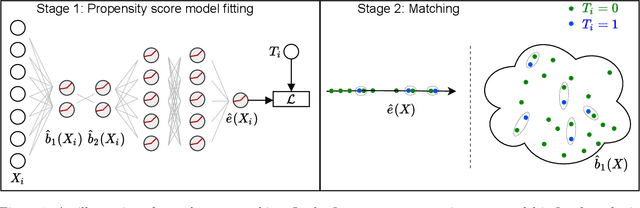
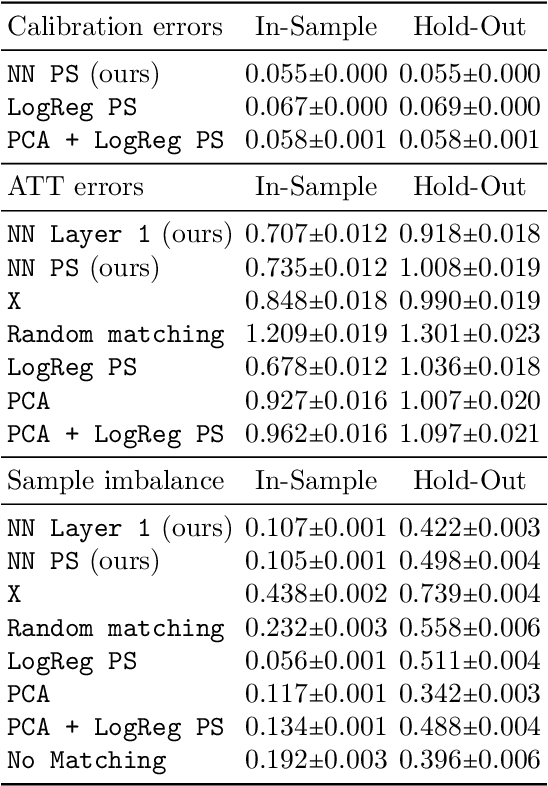
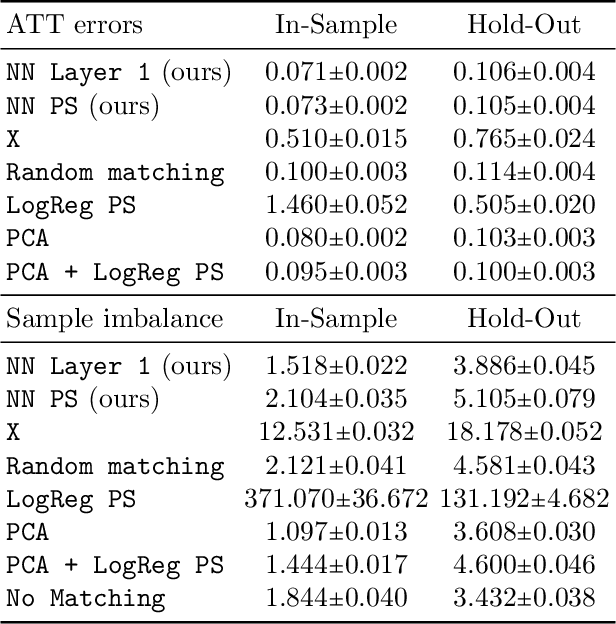
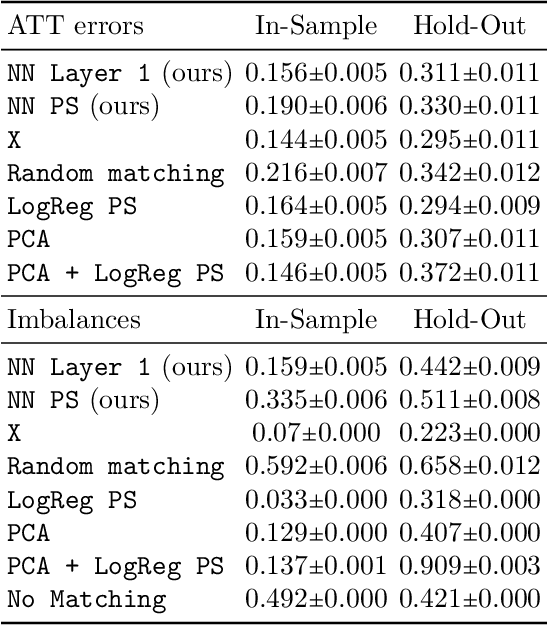
Traditional methods for matching in causal inference are impractical for high-dimensional datasets. They suffer from the curse of dimensionality: exact matching and coarsened exact matching find exponentially fewer matches as the input dimension grows, and propensity score matching may match highly unrelated units together. To overcome this problem, we develop theoretical results which motivate the use of neural networks to obtain non-trivial, multivariate balancing scores of a chosen level of coarseness, in contrast to the classical, scalar propensity score. We leverage these balancing scores to perform matching for high-dimensional causal inference and call this procedure neural score matching. We show that our method is competitive against other matching approaches on semi-synthetic high-dimensional datasets, both in terms of treatment effect estimation and reducing imbalance.
A Graph Based Neural Network Approach to Immune Profiling of Multiplexed Tissue Samples
Feb 01, 2022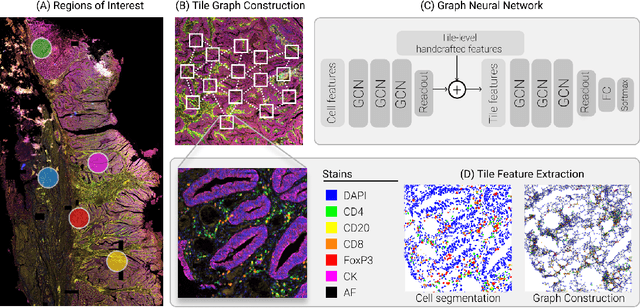

Multiplexed immunofluorescence provides an unprecedented opportunity for studying specific cell-to-cell and cell microenvironment interactions. We employ graph neural networks to combine features obtained from tissue morphology with measurements of protein expression to profile the tumour microenvironment associated with different tumour stages. Our framework presents a new approach to analysing and processing these complex multi-dimensional datasets that overcomes some of the key challenges in analysing these data and opens up the opportunity to abstract biologically meaningful interactions.
Bias Mitigated Learning from Differentially Private Synthetic Data: A Cautionary Tale
Aug 24, 2021
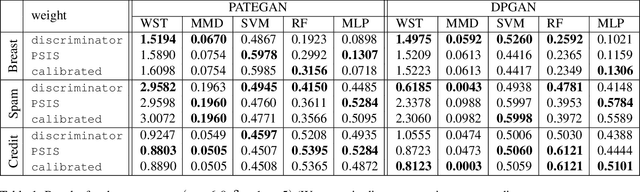
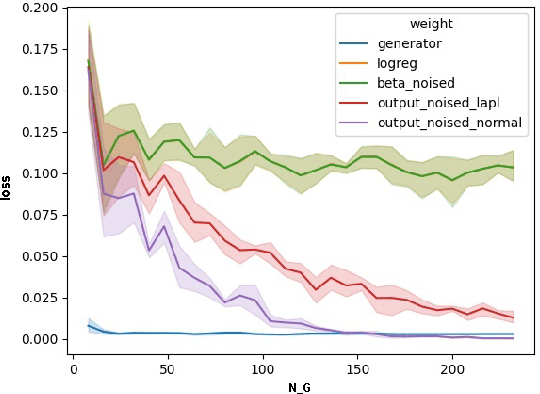
Increasing interest in privacy-preserving machine learning has led to new models for synthetic private data generation from undisclosed real data. However, mechanisms of privacy preservation introduce artifacts in the resulting synthetic data that have a significant impact on downstream tasks such as learning predictive models or inference. In particular, bias can affect all analyses as the synthetic data distribution is an inconsistent estimate of the real-data distribution. We propose several bias mitigation strategies using privatized likelihood ratios that have general applicability to differentially private synthetic data generative models. Through large-scale empirical evaluation, we show that bias mitigation provides simple and effective privacy-compliant augmentation for general applications of synthetic data. However, the work highlights that even after bias correction significant challenges remain on the usefulness of synthetic private data generators for tasks such as prediction and inference.
On Locality of Local Explanation Models
Jun 24, 2021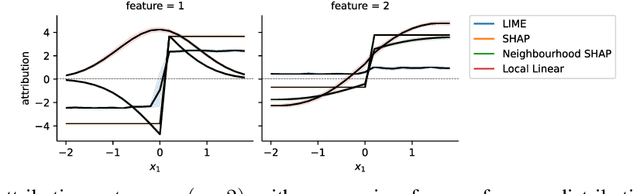
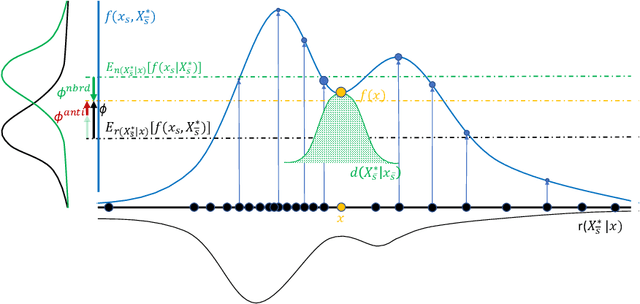

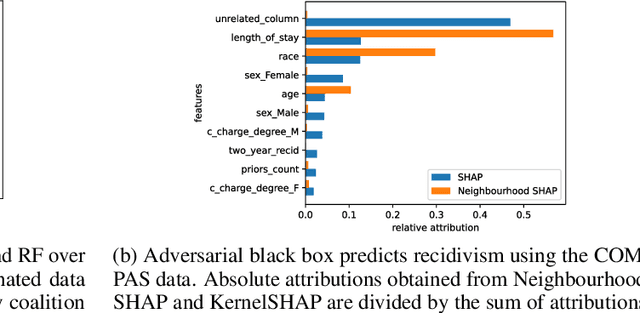
Shapley values provide model agnostic feature attributions for model outcome at a particular instance by simulating feature absence under a global population distribution. The use of a global population can lead to potentially misleading results when local model behaviour is of interest. Hence we consider the formulation of neighbourhood reference distributions that improve the local interpretability of Shapley values. By doing so, we find that the Nadaraya-Watson estimator, a well-studied kernel regressor, can be expressed as a self-normalised importance sampling estimator. Empirically, we observe that Neighbourhood Shapley values identify meaningful sparse feature relevance attributions that provide insight into local model behaviour, complimenting conventional Shapley analysis. They also increase on-manifold explainability and robustness to the construction of adversarial classifiers.
Deep Generative Pattern-Set Mixture Models for Nonignorable Missingness
Mar 05, 2021

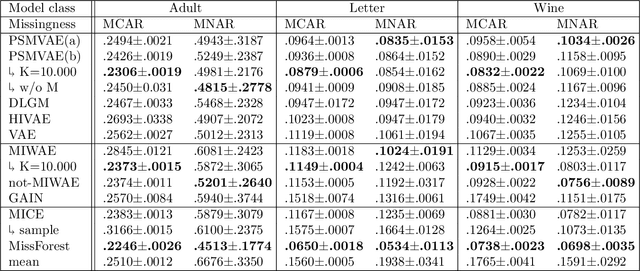

We propose a variational autoencoder architecture to model both ignorable and nonignorable missing data using pattern-set mixtures as proposed by Little (1993). Our model explicitly learns to cluster the missing data into missingness pattern sets based on the observed data and missingness masks. Underpinning our approach is the assumption that the data distribution under missingness is probabilistically semi-supervised by samples from the observed data distribution. Our setup trades off the characteristics of ignorable and nonignorable missingness and can thus be applied to data of both types. We evaluate our method on a wide range of data sets with different types of missingness and achieve state-of-the-art imputation performance. Our model outperforms many common imputation algorithms, especially when the amount of missing data is high and the missingness mechanism is nonignorable.
* International Conference on Artificial Intelligence and Statistics (AISTATS)
Asymmetric Heavy Tails and Implicit Bias in Gaussian Noise Injections
Feb 13, 2021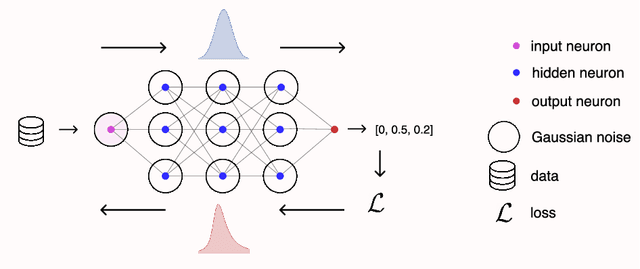
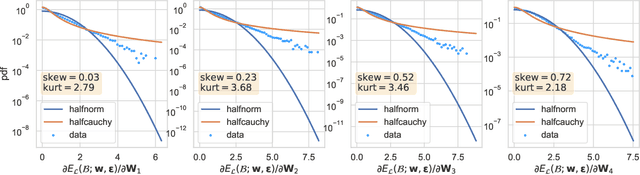
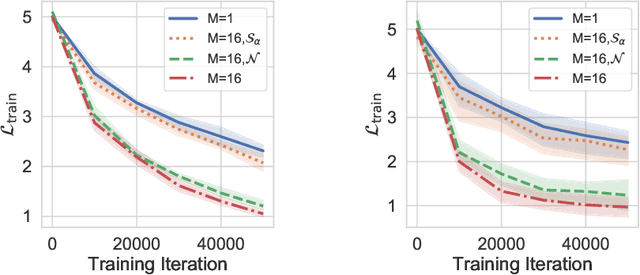
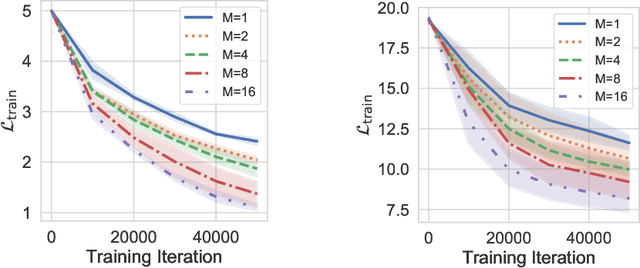
Gaussian noise injections (GNIs) are a family of simple and widely-used regularisation methods for training neural networks, where one injects additive or multiplicative Gaussian noise to the network activations at every iteration of the optimisation algorithm, which is typically chosen as stochastic gradient descent (SGD). In this paper we focus on the so-called `implicit effect' of GNIs, which is the effect of the injected noise on the dynamics of SGD. We show that this effect induces an asymmetric heavy-tailed noise on SGD gradient updates. In order to model this modified dynamics, we first develop a Langevin-like stochastic differential equation that is driven by a general family of asymmetric heavy-tailed noise. Using this model we then formally prove that GNIs induce an `implicit bias', which varies depending on the heaviness of the tails and the level of asymmetry. Our empirical results confirm that different types of neural networks trained with GNIs are well-modelled by the proposed dynamics and that the implicit effect of these injections induces a bias that degrades the performance of networks.
Foundations of Bayesian Learning from Synthetic Data
Nov 24, 2020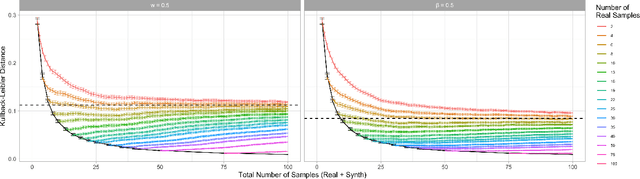
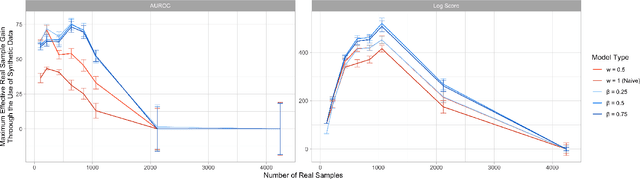
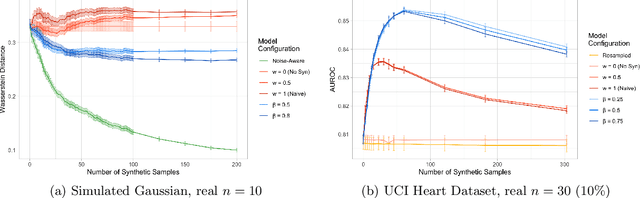
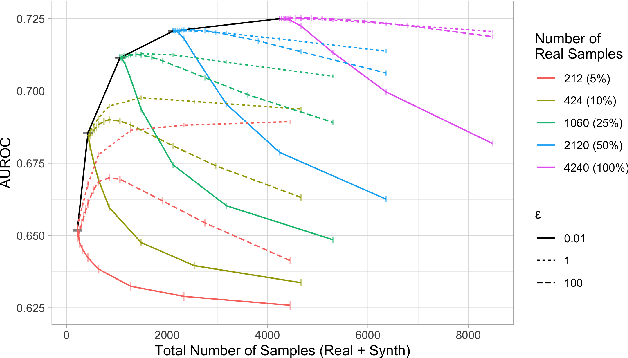
There is significant growth and interest in the use of synthetic data as an enabler for machine learning in environments where the release of real data is restricted due to privacy or availability constraints. Despite a large number of methods for synthetic data generation, there are comparatively few results on the statistical properties of models learnt on synthetic data, and fewer still for situations where a researcher wishes to augment real data with another party's synthesised data. We use a Bayesian paradigm to characterise the updating of model parameters when learning in these settings, demonstrating that caution should be taken when applying conventional learning algorithms without appropriate consideration of the synthetic data generating process and learning task. Recent results from general Bayesian updating support a novel and robust approach to Bayesian synthetic-learning founded on decision theory that outperforms standard approaches across repeated experiments on supervised learning and inference problems.
Explicit Regularisation in Gaussian Noise Injections
Jul 14, 2020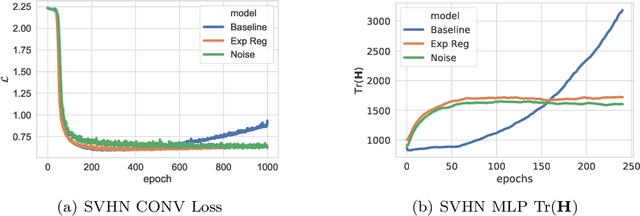

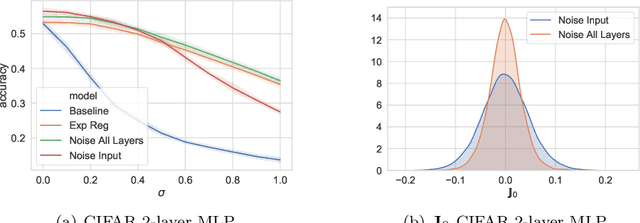
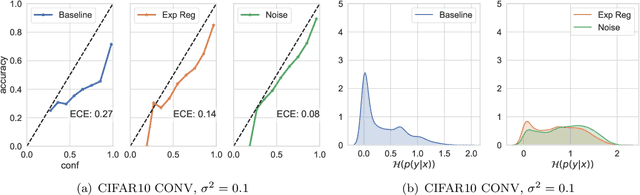
We study the regularisation induced in neural networks by Gaussian noise injections (GNIs). Though such injections have been extensively studied when applied to data, there have been few studies on understanding the regularising effect they induce when applied to network activations. Here we derive the explicit regulariser of GNIs, obtained by marginalising out the injected noise, and show that it is a form of Tikhonov regularisation which penalises functions with high-frequency components in the Fourier domain. We show analytically and empirically that such regularisation produces calibrated classifiers with large classification margins and that the explicit regulariser we derive is able to reproduce these effects.