 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Exploration at Scale
Mar 18, 2026We develop an online learning algorithm that dramatically improves the data efficiency of reinforcement learning from human feedback (RLHF). Our algorithm incrementally updates reward and language models as choice data is received. The reward model is fit to the choice data, while the language model is updated by a variation of reinforce, with reinforcement signals provided by the reward model. Several features enable the efficiency gains: a small affirmative nudge added to each reinforcement signal, an epistemic neural network that models reward uncertainty, and information-directed exploration. With Gemma large language models (LLMs), our algorithm matches the performance of offline RLHF trained on 200K labels using fewer than 20K labels, representing more than a 10x gain in data efficiency. Extrapolating from our results, we expect our algorithm trained on 1M labels to match offline RLHF trained on 1B labels. This represents a 1,000x gain. To our knowledge, these are the first results to demonstrate that such large improvements are possible.
CheXpert: A Large Chest Radiograph Dataset with Uncertainty Labels and Expert Comparison
Jan 21, 2019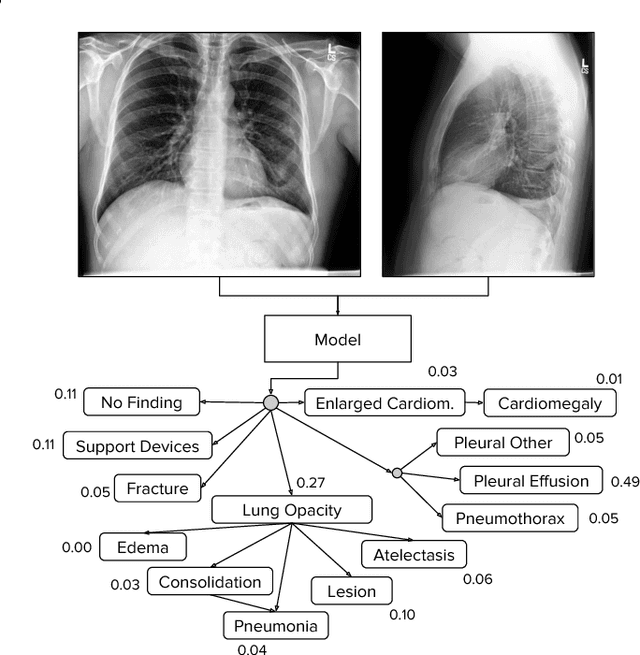
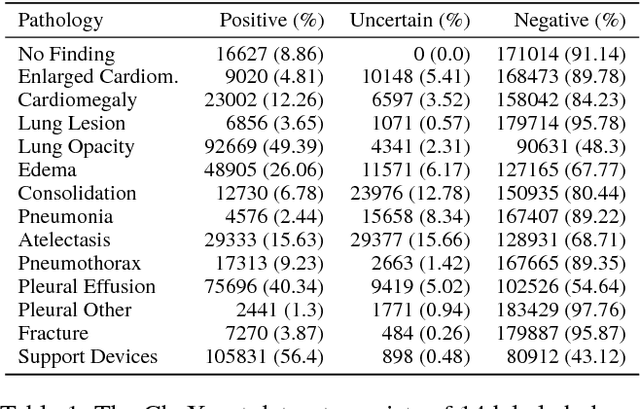

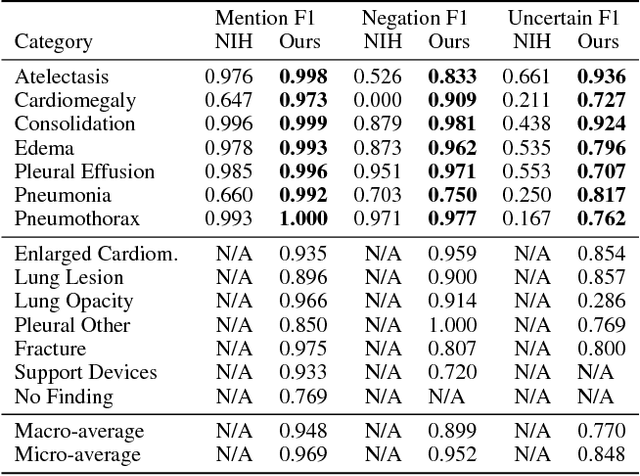
Large, labeled datasets have driven deep learning methods to achieve expert-level performance on a variety of medical imaging tasks. We present CheXpert, a large dataset that contains 224,316 chest radiographs of 65,240 patients. We design a labeler to automatically detect the presence of 14 observations in radiology reports, capturing uncertainties inherent in radiograph interpretation. We investigate different approaches to using the uncertainty labels for training convolutional neural networks that output the probability of these observations given the available frontal and lateral radiographs. On a validation set of 200 chest radiographic studies which were manually annotated by 3 board-certified radiologists, we find that different uncertainty approaches are useful for different pathologies. We then evaluate our best model on a test set composed of 500 chest radiographic studies annotated by a consensus of 5 board-certified radiologists, and compare the performance of our model to that of 3 additional radiologists in the detection of 5 selected pathologies. On Cardiomegaly, Edema, and Pleural Effusion, the model ROC and PR curves lie above all 3 radiologist operating points. We release the dataset to the public as a standard benchmark to evaluate performance of chest radiograph interpretation models. The dataset is freely available at https://stanfordmlgroup.github.io/competitions/chexpert .