 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Identification of Structure Function of Academic Articles Using Contextual Information
Dec 02, 2021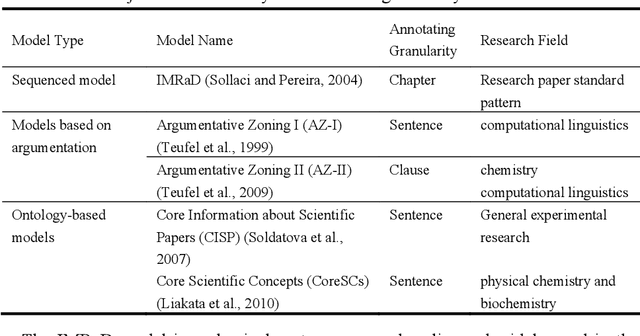
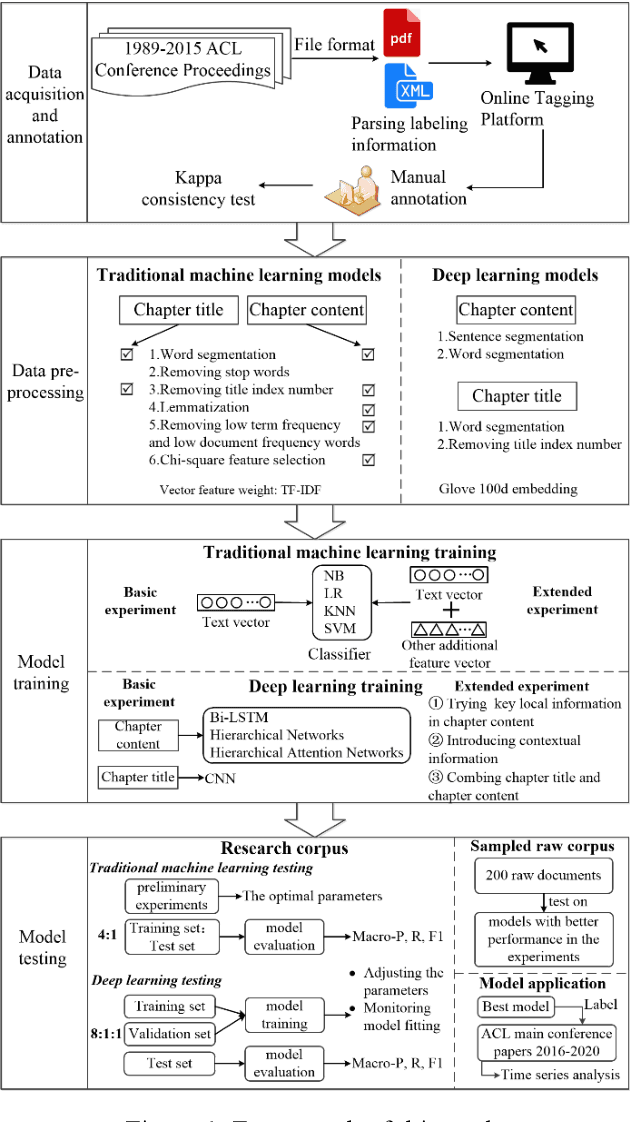
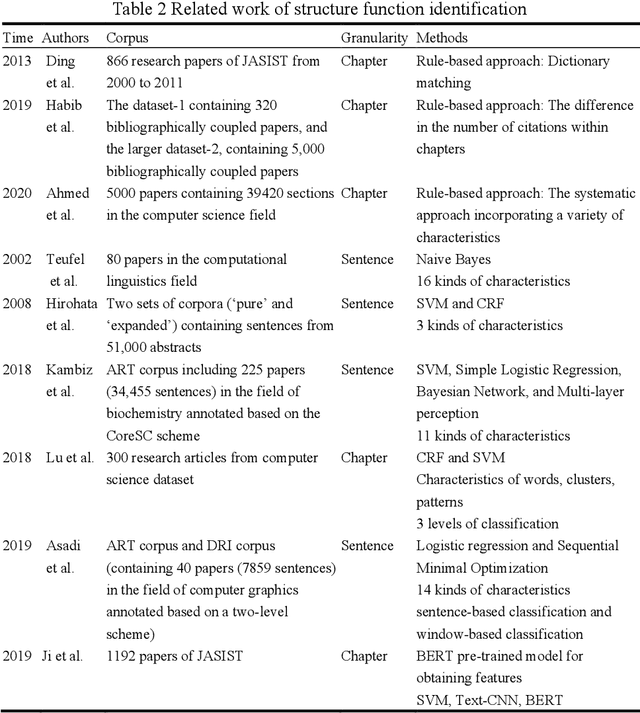
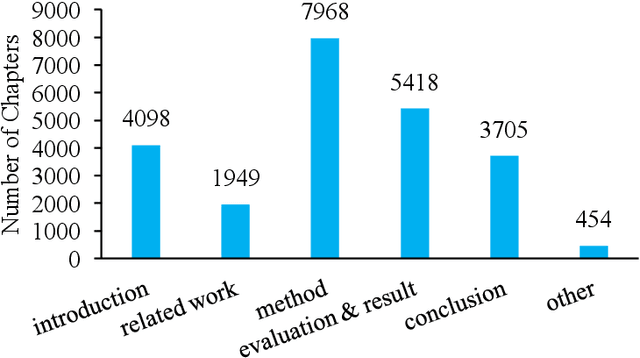
With the enrichment of literature resources, researchers are facing the growing problem of information explosion and knowledge overload. To help scholars retrieve literature and acquire knowledge successfully, clarifying the semantic structure of the content in academic literature has become the essential research question. In the research on identifying the structure function of chapters in academic articles, only a few studies used the deep learning model and explored the optimization for feature input. This limits the application, optimization potential of deep learning models for the research task. This paper took articles of the ACL conference as the corpus. We employ the traditional machine learning models and deep learning models to construct the classifiers based on various feature input. Experimental results show that (1) Compared with the chapter content, the chapter title is more conducive to identifying the structure function of academic articles. (2) Relative position is a valuable feature for building traditional models. (3) Inspired by (2), this paper further introduces contextual information into the deep learning models and achieved significant results. Meanwhile, our models show good migration ability in the open test containing 200 sampled non-training samples. We also annotated the ACL main conference papers in recent five years based on the best practice performing models and performed a time series analysis of the overall corpus. This work explores and summarizes the practical features and models for this task through multiple comparative experiments and provides a reference for related text classification tasks. Finally, we indicate the limitations and shortcomings of the current model and the direction of further optimization.
Enhancing Keyphrase Extraction from Academic Articles with their Reference Information
Nov 30, 2021
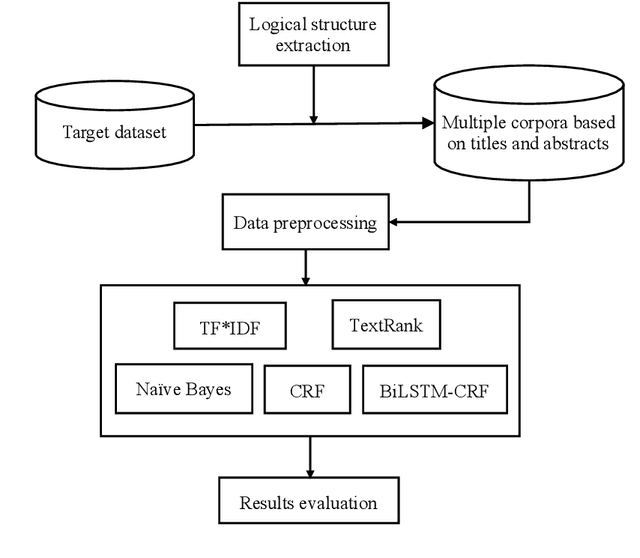
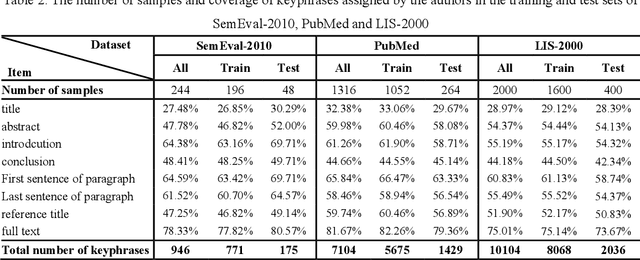
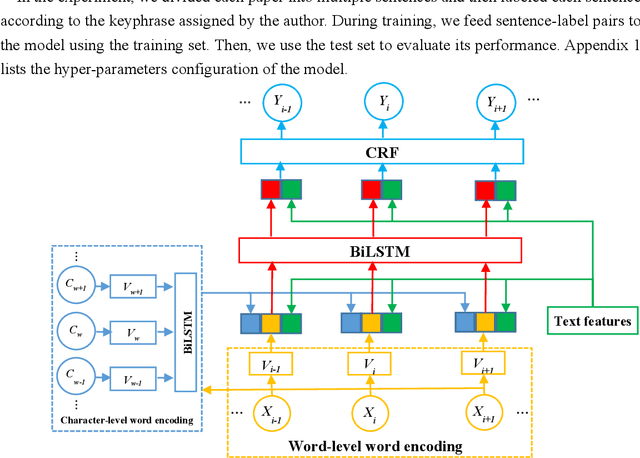
With the development of Internet technology, the phenomenon of information overload is becoming more and more obvious. It takes a lot of time for users to obtain the information they need. However, keyphrases that summarize document information highly are helpful for users to quickly obtain and understand documents. For academic resources, most existing studies extract keyphrases through the title and abstract of papers. We find that title information in references also contains author-assigned keyphrases. Therefore, this article uses reference information and applies two typical methods of unsupervised extraction methods (TF*IDF and TextRank), two representative traditional supervised learning algorithms (Na\"ive Bayes and Conditional Random Field) and a supervised deep learning model (BiLSTM-CRF), to analyze the specific performance of reference information on keyphrase extraction. It is expected to improve the quality of keyphrase recognition from the perspective of expanding the source text. The experimental results show that reference information can increase precision, recall, and F1 of automatic keyphrase extraction to a certain extent. This indicates the usefulness of reference information on keyphrase extraction of academic papers and provides a new idea for the following research on automatic keyphrase extraction.
Impacts Towards a comprehensive assessment of the book impact by integrating multiple evaluation sources
Jul 22, 2021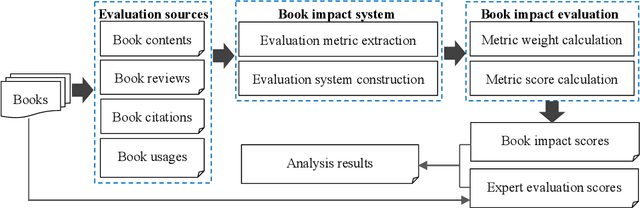
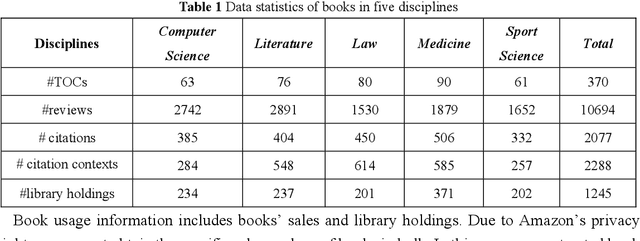

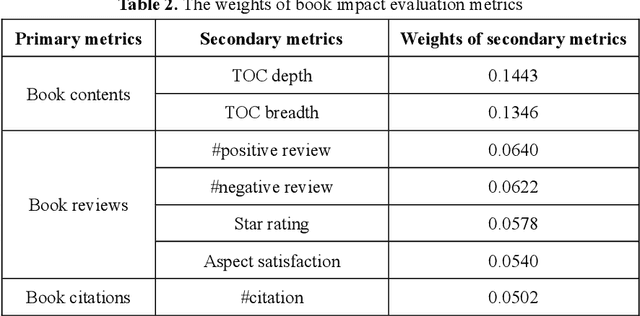
The surge in the number of books published makes the manual evaluation methods difficult to efficiently evaluate books. The use of books' citations and alternative evaluation metrics can assist manual evaluation and reduce the cost of evaluation. However, most existing evaluation research was based on a single evaluation source with coarse-grained analysis, which may obtain incomprehensive or one-sided evaluation results of book impact. Meanwhile, relying on a single resource for book assessment may lead to the risk that the evaluation results cannot be obtained due to the lack of the evaluation data, especially for newly published books. Hence, this paper measured book impact based on an evaluation system constructed by integrating multiple evaluation sources. Specifically, we conducted finer-grained mining on the multiple evaluation sources, including books' internal evaluation resources and external evaluation resources. Various technologies (e.g. topic extraction, sentiment analysis, text classification) were used to extract corresponding evaluation metrics from the internal and external evaluation resources. Then, Expert evaluation combined with analytic hierarchy process was used to integrate the evaluation metrics and construct a book impact evaluation system. Finally, the reliability of the evaluation system was verified by comparing with the results of expert evaluation, detailed and diversified evaluation results were then obtained. The experimental results reveal that differential evaluation resources can measure the books' impacts from different dimensions, and the integration of multiple evaluation data can assess books more comprehensively. Meanwhile, the book impact evaluation system can provide personalized evaluation results according to the users' evaluation purposes. In addition, the disciplinary differences should be considered for assessing books' impacts.
Breaking Community Boundary: Comparing Academic and Social Communication Preferences regarding Global Pandemics
Apr 12, 2021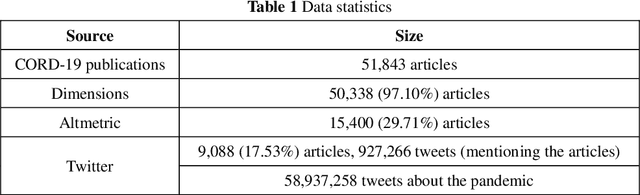
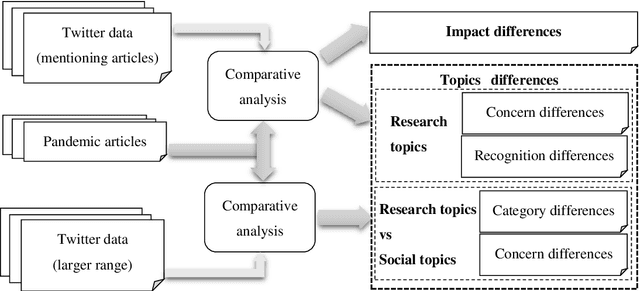
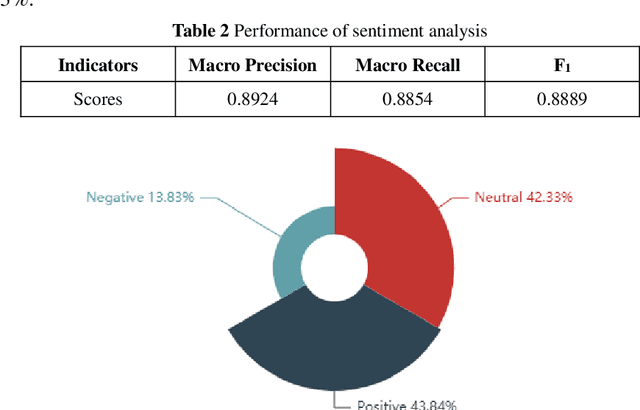
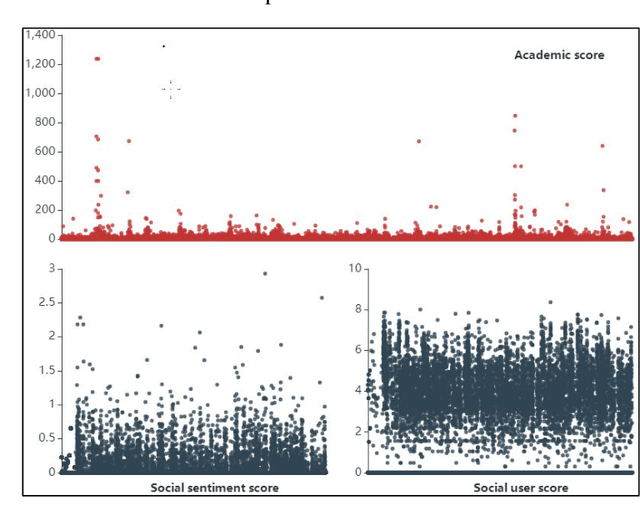
The global spread of COVID-19 has caused pandemics to be widely discussed. This is evident in the large number of scientific articles and the amount of user-generated content on social media. This paper aims to compare academic communication and social communication about the pandemic from the perspective of communication preference differences. It aims to provide information for the ongoing research on global pandemics, thereby eliminating knowledge barriers and information inequalities between the academic and the social communities. First, we collected the full text and the metadata of pandemic-related articles and Twitter data mentioning the articles. Second, we extracted and analyzed the topics and sentiment tendencies of the articles and related tweets. Finally, we conducted pandemic-related differential analysis on the academic community and the social community. We mined the resulting data to generate pandemic communication preferences (e.g., information needs, attitude tendencies) of researchers and the public, respectively. The research results from 50,338 articles and 927,266 corresponding tweets mentioning the articles revealed communication differences about global pandemics between the academic and the social communities regarding the consistency of research recognition and the preferences for particular research topics. The analysis of large-scale pandemic-related tweets also confirmed the communication preference differences between the two communities.
Using Full-text Content of Academic Articles to Build a Methodology Taxonomy of Information Science in China
Jan 20, 2021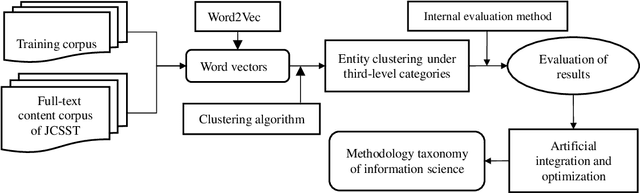
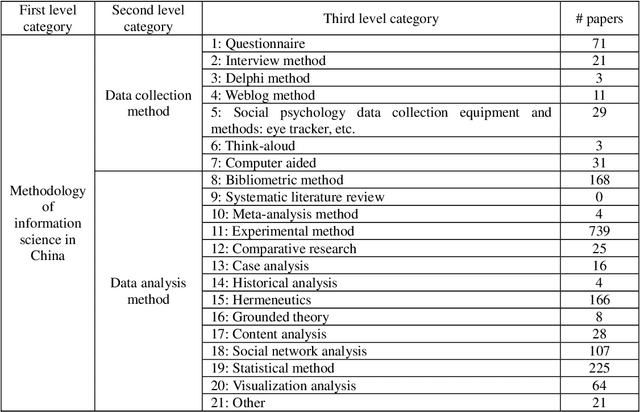

Research on the construction of traditional information science methodology taxonomy is mostly conducted manually. From the limited corpus, researchers have attempted to summarize some of the research methodology entities into several abstract levels (generally three levels); however, they have been unable to provide a more granular hierarchy. Moreover, updating the methodology taxonomy is traditionally a slow process. In this study, we collected full-text academic papers related to information science. First, we constructed a basic methodology taxonomy with three levels by manual annotation. Then, the word vectors of the research methodology entities were trained using the full-text data. Accordingly, the research methodology entities were clustered and the basic methodology taxonomy was expanded using the clustering results to obtain a methodology taxonomy with more levels. This study provides new concepts for constructing a methodology taxonomy of information science. The proposed methodology taxonomy is semi-automated; it is more detailed than conventional schemes and the speed of taxonomy renewal has been enhanced.
Characterizing References from Different Disciplines: A Perspective of Citation Content Analysis
Jan 19, 2021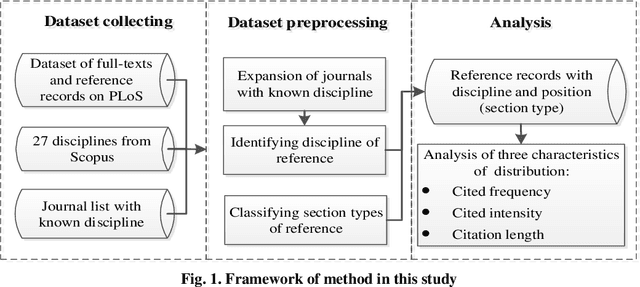
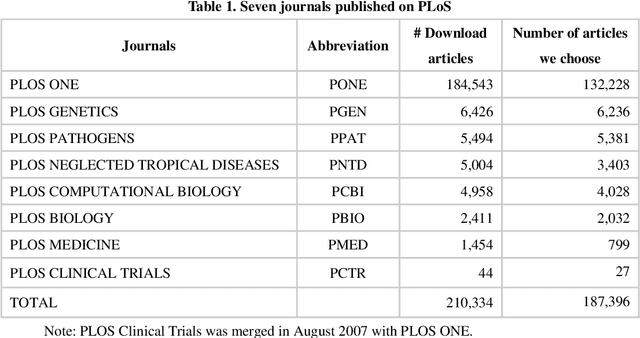
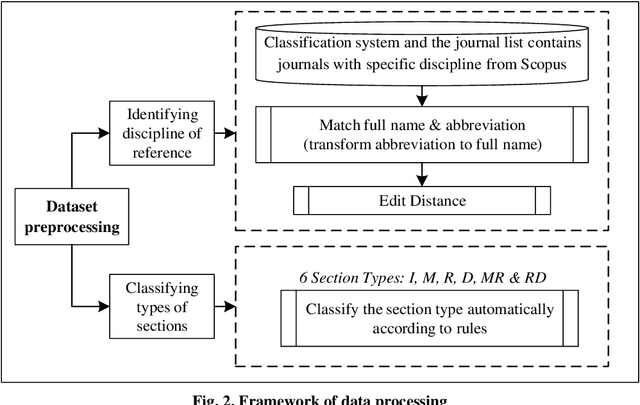
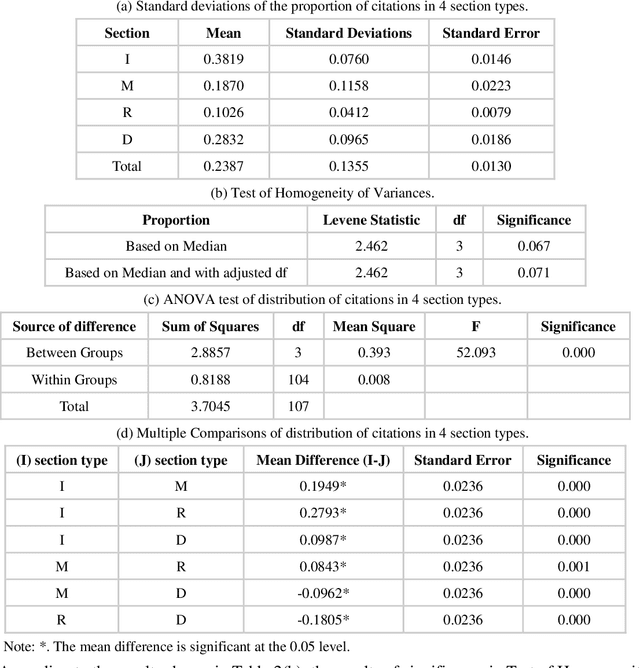
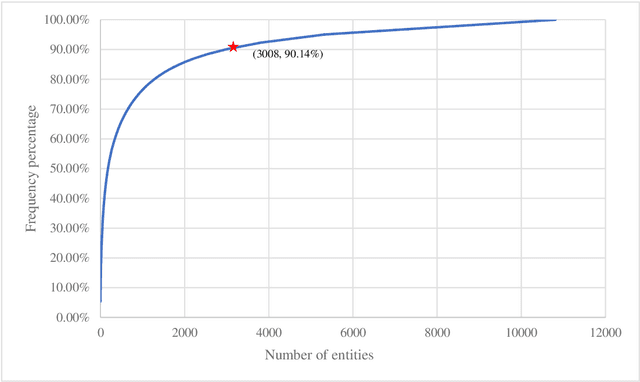
Multidisciplinary cooperation is now common in research since social issues inevitably involve multiple disciplines. In research articles, reference information, especially citation content, is an important representation of communication among different disciplines. Analyzing the distribution characteristics of references from different disciplines in research articles is basic to detecting the sources of referred information and identifying contributions of different disciplines. This work takes articles in PLoS as the data and characterizes the references from different disciplines based on Citation Content Analysis (CCA). First, we download 210,334 full-text articles from PLoS and collect the information of the in-text citations. Then, we identify the discipline of each reference in these academic articles. To characterize the distribution of these references, we analyze three characteristics, namely, the number of citations, the average cited intensity and the average citation length. Finally, we conclude that the distributions of references from different disciplines are significantly different. Although most references come from Natural Science, Humanities and Social Sciences play important roles in the Introduction and Background sections of the articles. Basic disciplines, such as Mathematics, mainly provide research methods in the articles in PLoS. Citations mentioned in the Results and Discussion sections of articles are mainly in-discipline citations, such as citations from Nursing and Medicine in PLoS.
Chronological Citation Recommendation with Time Preference
Jan 19, 2021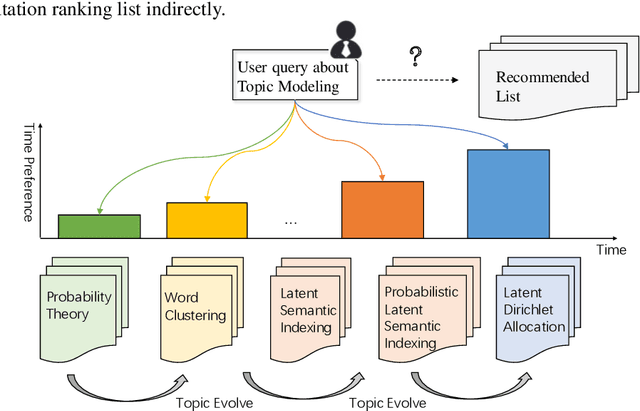

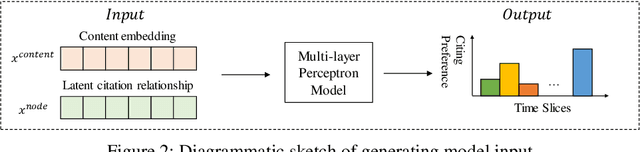
Citation recommendation is an important task to assist scholars in finding candidate literature to cite. Traditional studies focus on static models of recommending citations, which do not explicitly distinguish differences between papers that are caused by temporal variations. Although, some researchers have investigated chronological citation recommendation by adding time related function or modeling textual topics dynamically. These solutions can hardly cope with function generalization or cold-start problems when there is no information for user profiling or there are isolated papers never being cited. With the rise and fall of science paradigms, scientific topics tend to change and evolve over time. People would have the time preference when citing papers, since most of the theoretical basis exist in classical readings that published in old time, while new techniques are proposed in more recent papers. To explore chronological citation recommendation, this paper wants to predict the time preference based on user queries, which is a probability distribution of citing papers published in different time slices. Then, we use this time preference to re-rank the initial citation list obtained by content-based filtering. Experimental results demonstrate that task performance can be further enhanced by time preference and it's flexible to be added in other citation recommendation frameworks.
Enhancing Keyphrase Extraction from Microblogs using Human Reading Time
Oct 25, 2020
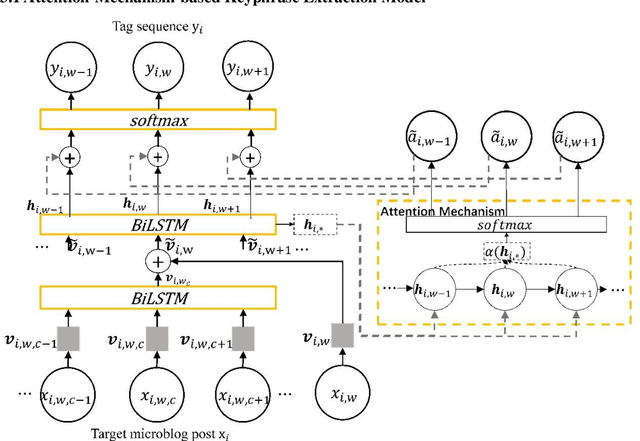
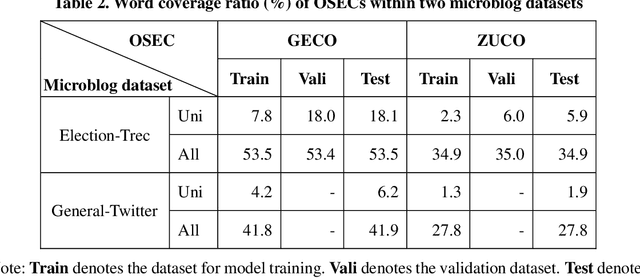
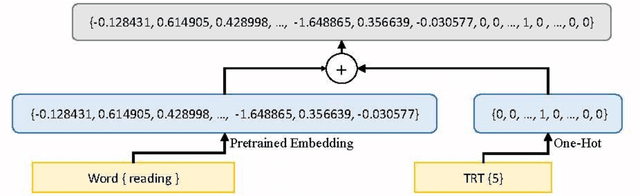
The premise of manual keyphrase annotation is to read the corresponding content of an annotated object. Intuitively, when we read, more important words will occupy a longer reading time. Hence, by leveraging human reading time, we can find the salient words in the corresponding content. However, previous studies on keyphrase extraction ignore human reading features. In this article, we aim to leverage human reading time to extract keyphrases from microblog posts. There are two main tasks in this study. One is to determine how to measure the time spent by a human on reading a word. We use eye fixation durations extracted from an open source eye-tracking corpus (OSEC). Moreover, we propose strategies to make eye fixation duration more effective on keyphrase extraction. The other task is to determine how to integrate human reading time into keyphrase extraction models. We propose two novel neural network models. The first is a model in which the human reading time is used as the ground truth of the attention mechanism. In the second model, we use human reading time as the external feature. Quantitative and qualitative experiments show that our proposed models yield better performance than the baseline models on two microblog datasets.
Using the Full-text Content of Academic Articles to Identify and Evaluate Algorithm Entities in the Domain of Natural Language Processing
Oct 21, 2020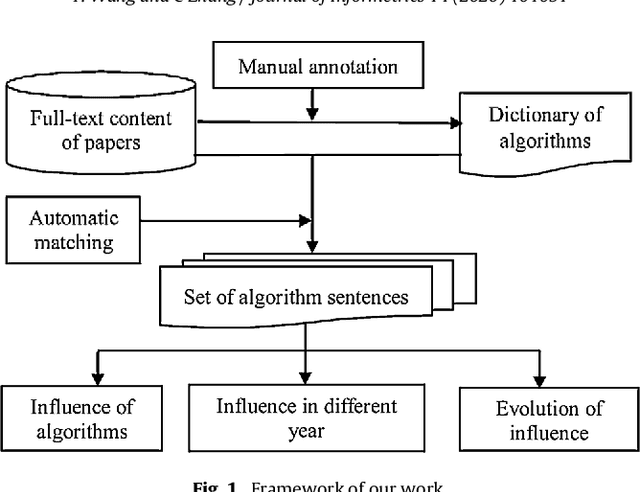
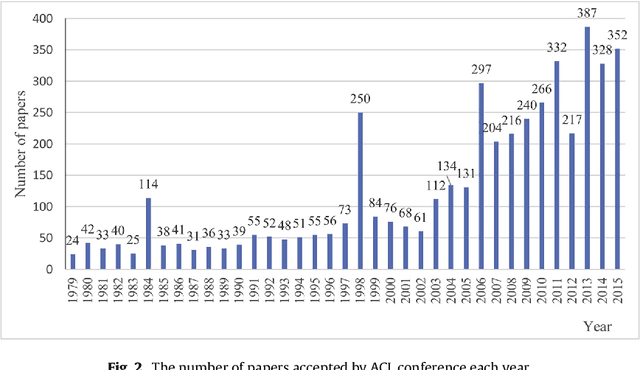
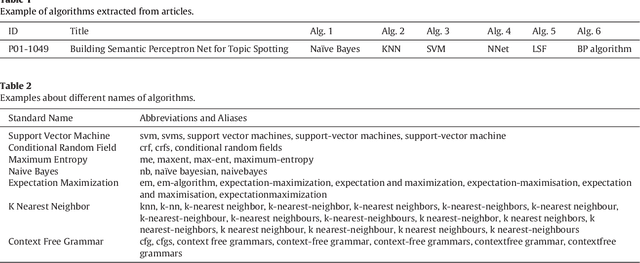
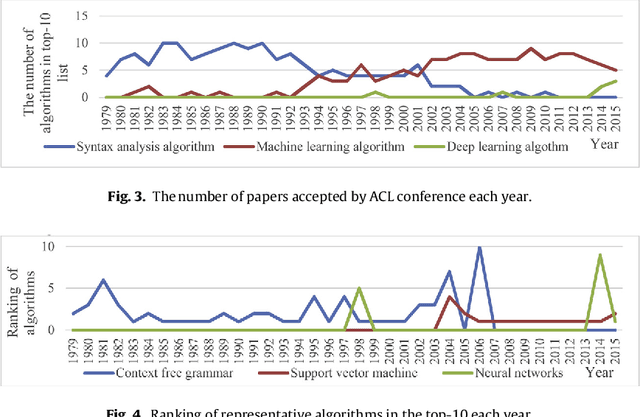
In the era of big data, the advancement, improvement, and application of algorithms in academic research have played an important role in promoting the development of different disciplines. Academic papers in various disciplines, especially computer science, contain a large number of algorithms. Identifying the algorithms from the full-text content of papers can determine popular or classical algorithms in a specific field and help scholars gain a comprehensive understanding of the algorithms and even the field. To this end, this article takes the field of natural language processing (NLP) as an example and identifies algorithms from academic papers in the field. A dictionary of algorithms is constructed by manually annotating the contents of papers, and sentences containing algorithms in the dictionary are extracted through dictionary-based matching. The number of articles mentioning an algorithm is used as an indicator to analyze the influence of that algorithm. Our results reveal the algorithm with the highest influence in NLP papers and show that classification algorithms represent the largest proportion among the high-impact algorithms. In addition, the evolution of the influence of algorithms reflects the changes in research tasks and topics in the field, and the changes in the influence of different algorithms show different trends. As a preliminary exploration, this paper conducts an analysis of the impact of algorithms mentioned in the academic text, and the results can be used as training data for the automatic extraction of large-scale algorithms in the future. The methodology in this paper is domain-independent and can be applied to other domains.
Spatio-Temporal Hybrid Graph Convolutional Network for Traffic Forecasting in Telecommunication Networks
Sep 17, 2020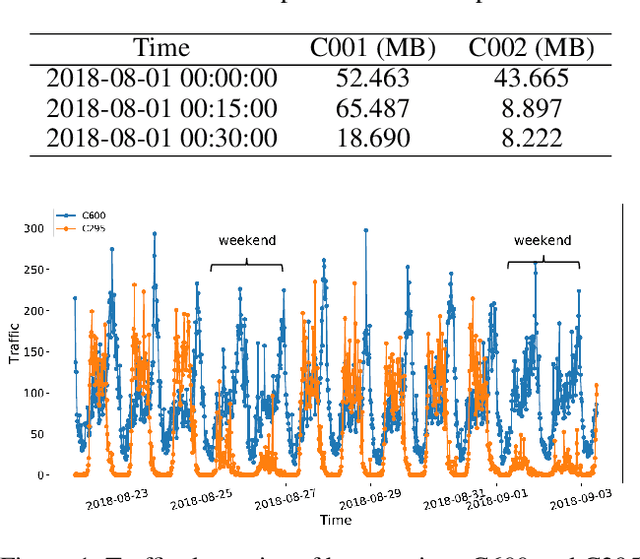
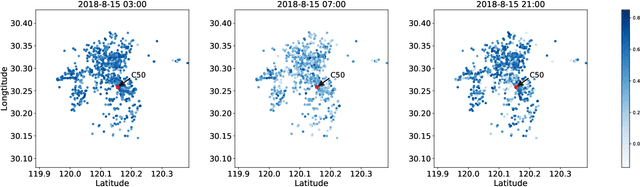
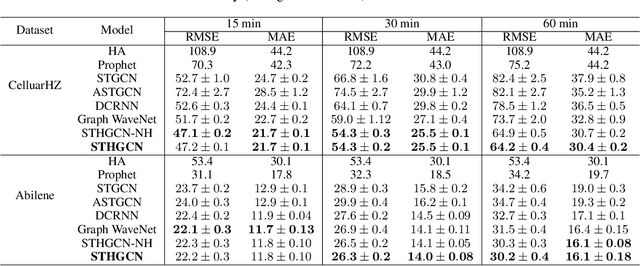
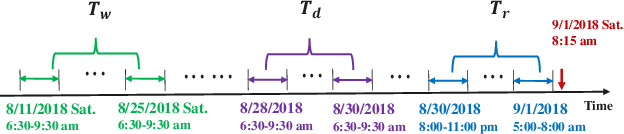
Telecommunication networks play a critical role in modern society. With the arrival of 5G networks, these systems are becoming even more diversified, integrated, and intelligent. Traffic forecasting is one of the key components in such a system, however, it is particularly challenging due to the complex spatial-temporal dependency. In this work, we consider this problem from the aspect of a cellular network and the interactions among its base stations. We thoroughly investigate the characteristics of cellular network traffic and shed light on the dependency complexities based on data collected from a densely populated metropolis area. Specifically, we observe that the traffic shows both dynamic and static spatial dependencies as well as diverse cyclic temporal patterns. To address these complexities, we propose an effective deep-learning-based approach, namely, Spatio-Temporal Hybrid Graph Convolutional Network (STHGCN). It employs GRUs to model the temporal dependency, while capturing the complex spatial dependency through a hybrid-GCN from three perspectives: spatial proximity, functional similarity, and recent trend similarity. We conduct extensive experiments on real-world traffic datasets collected from telecommunication networks. Our experimental results demonstrate the superiority of the proposed model in that it consistently outperforms both classical methods and state-of-the-art deep learning models, while being more robust and stable.