 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Words: Multimodal LLM Knows When to Speak
May 20, 2025While large language model (LLM)-based chatbots have demonstrated strong capabilities in generating coherent and contextually relevant responses, they often struggle with understanding when to speak, particularly in delivering brief, timely reactions during ongoing conversations. This limitation arises largely from their reliance on text input, lacking the rich contextual cues in real-world human dialogue. In this work, we focus on real-time prediction of response types, with an emphasis on short, reactive utterances that depend on subtle, multimodal signals across vision, audio, and text. To support this, we introduce a new multimodal dataset constructed from real-world conversational videos, containing temporally aligned visual, auditory, and textual streams. This dataset enables fine-grained modeling of response timing in dyadic interactions. Building on this dataset, we propose MM-When2Speak, a multimodal LLM-based model that adaptively integrates visual, auditory, and textual context to predict when a response should occur, and what type of response is appropriate. Experiments show that MM-When2Speak significantly outperforms state-of-the-art unimodal and LLM-based baselines, achieving up to a 4x improvement in response timing accuracy over leading commercial LLMs. These results underscore the importance of multimodal inputs for producing timely, natural, and engaging conversational AI.
Co-localization with Category-Consistent CNN Features and Geodesic Distance Propagation
Apr 03, 2017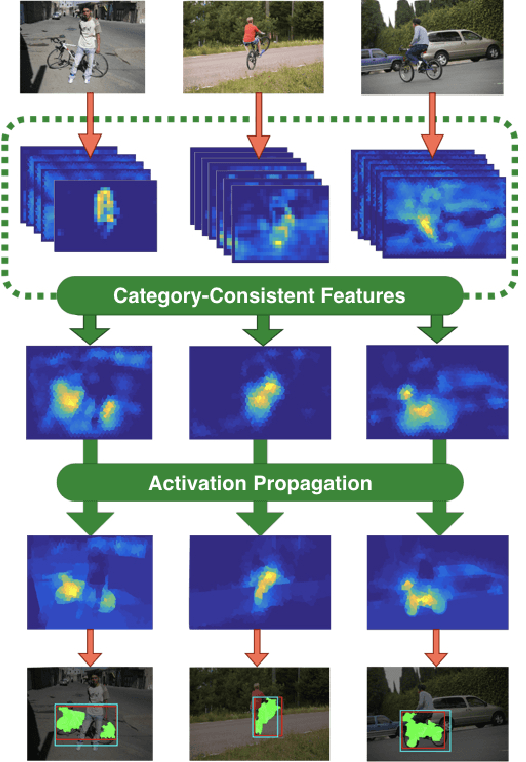



Co-localization is the problem of localizing objects of the same class using only the set of images that contain them. This is a challenging task because the object detector must be built without negative examples that can lead to more informative supervision signals. The main idea of our method is to cluster the feature space of a generically pre-trained CNN, to find a set of CNN features that are consistently and highly activated for an object category, which we call category-consistent CNN features. Then, we propagate their combined activation map using superpixel geodesic distances for co-localization. In our first set of experiments, we show that the proposed method achieves state-of-the-art performance on three related benchmarks: PASCAL 2007, PASCAL-2012, and the Object Discovery dataset. We also show that our method is able to detect and localize truly unseen categories, on six held-out ImageNet categories with accuracy that is significantly higher than previous state-of-the-art. Our intuitive approach achieves this success without any region proposals or object detectors, and can be based on a CNN that was pre-trained purely on image classification tasks without further fine-tuning.
Squared Earth Mover's Distance-based Loss for Training Deep Neural Networks
Apr 03, 2017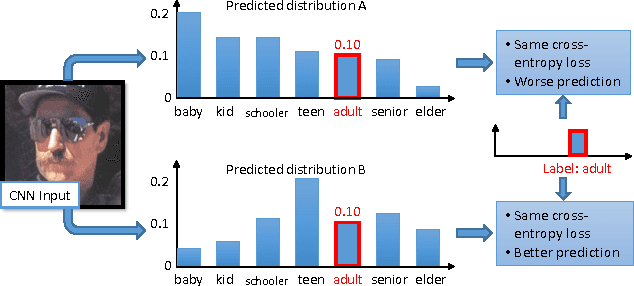
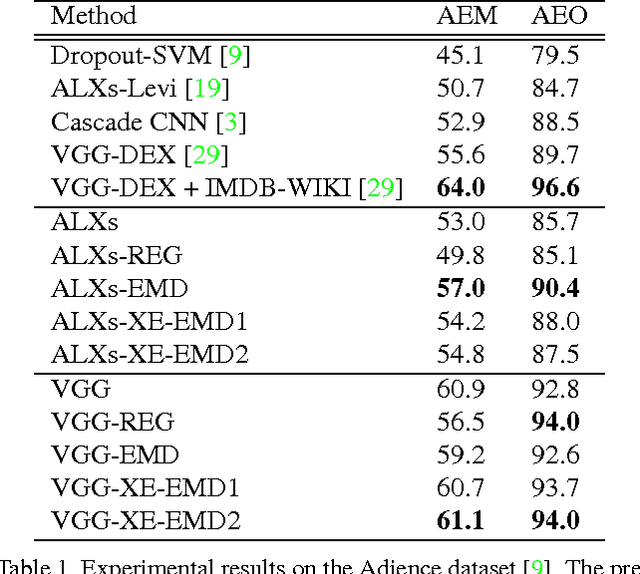
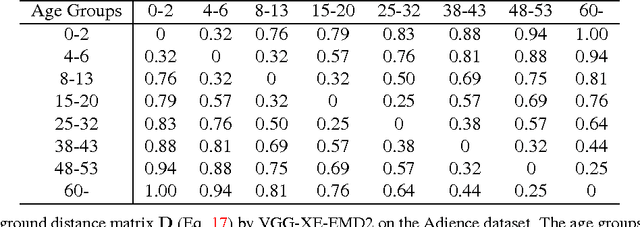
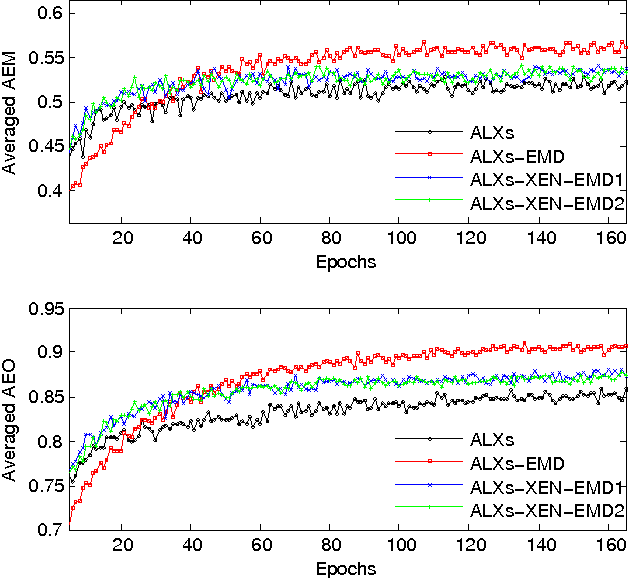
In the context of single-label classification, despite the huge success of deep learning, the commonly used cross-entropy loss function ignores the intricate inter-class relationships that often exist in real-life tasks such as age classification. In this work, we propose to leverage these relationships between classes by training deep nets with the exact squared Earth Mover's Distance (also known as Wasserstein distance) for single-label classification. The squared EMD loss uses the predicted probabilities of all classes and penalizes the miss-predictions according to a ground distance matrix that quantifies the dissimilarities between classes. We demonstrate that on datasets with strong inter-class relationships such as an ordering between classes, our exact squared EMD losses yield new state-of-the-art results. Furthermore, we propose a method to automatically learn this matrix using the CNN's own features during training. We show that our method can learn a ground distance matrix efficiently with no inter-class relationship priors and yield the same performance gain. Finally, we show that our method can be generalized to applications that lack strong inter-class relationships and still maintain state-of-the-art performance. Therefore, with limited computational overhead, one can always deploy the proposed loss function on any dataset over the conventional cross-entropy.
Geodesic Distance Histogram Feature for Video Segmentation
Mar 31, 2017
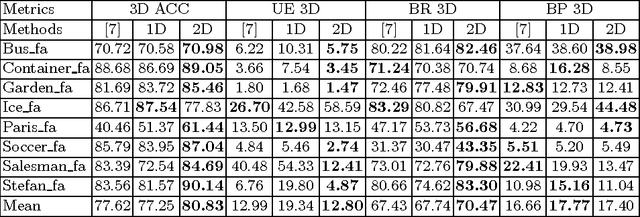
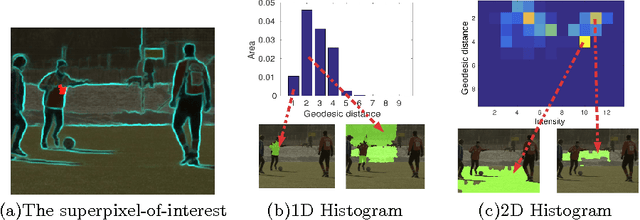
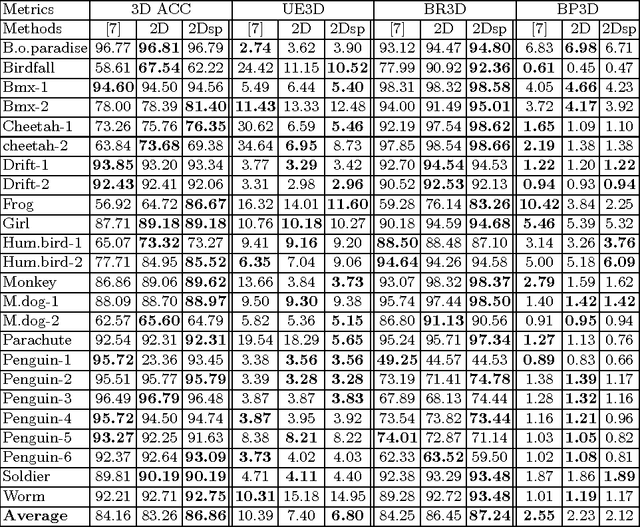
This paper proposes a geodesic-distance-based feature that encodes global information for improved video segmentation algorithms. The feature is a joint histogram of intensity and geodesic distances, where the geodesic distances are computed as the shortest paths between superpixels via their boundaries. We also incorporate adaptive voting weights and spatial pyramid configurations to include spatial information into the geodesic histogram feature and show that this further improves results. The feature is generic and can be used as part of various algorithms. In experiments, we test the geodesic histogram feature by incorporating it into two existing video segmentation frameworks. This leads to significantly better performance in 3D video segmentation benchmarks on two datasets.