 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional independence by typing
Oct 22, 2020
A central goal of probabilistic programming languages (PPLs) is to separate modelling from inference. However, this goal is hard to achieve in practice. Users are often forced to re-write their models in order to improve efficiency of inference or meet restrictions imposed by the PPL. Conditional independence (CI) relationships among parameters are a crucial aspect of probabilistic models that captures a qualitative summary of the specified model and can facilitate more efficient inference. We present an information flow type system for probabilistic programming that captures conditional independence (CI) relationships, and show that, for a well-typed program in our system, the distribution it implements is guaranteed to have certain CI-relationships. Further, by using type inference, we can statically \emph{deduce} which CI-properties are present in a specified model. As a practical application, we consider the problem of how to perform inference on models with mixed discrete and continuous parameters. Inference on such models is challenging in many existing PPLs, but can be improved through a workaround, where the discrete parameters are used \textit{implicitly}, at the expense of manual model re-writing. We present a source-to-source semantics-preserving transformation, which uses our CI-type system to automate this workaround by eliminating the discrete parameters from a probabilistic program. The resulting program can be seen as a hybrid inference algorithm on the original program, where continuous parameters can be drawn using efficient gradient-based inference methods, while the discrete parameters are drawn using variable elimination. We implement our CI-type system and its example application in SlicStan: a compositional variant of Stan.
BUSTLE: Bottom-up program-Synthesis Through Learning-guided Exploration
Jul 28, 2020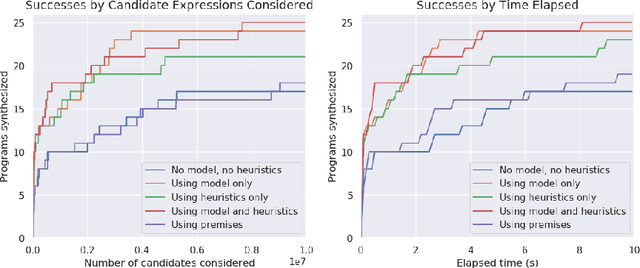
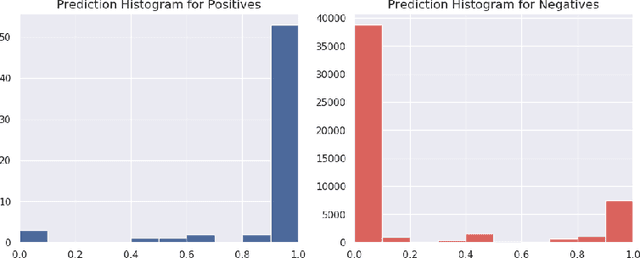
Program synthesis is challenging largely because of the difficulty of search in a large space of programs. Human programmers routinely tackle the task of writing complex programs by writing sub-programs and then analysing their intermediate results to compose them in appropriate ways. Motivated by this intuition, we present a new synthesis approach that leverages learning to guide a bottom-up search over programs. In particular, we train a model to prioritize compositions of intermediate values during search conditioned on a given set of input-output examples. This is a powerful combination because of several emergent properties: First, in bottom-up search, intermediate programs can be executed, providing semantic information to the neural network. Second, given the concrete values from those executions, we can exploit rich features based on recent work on property signatures. Finally, bottom-up search allows the system substantial flexibility in what order to generate the solution, allowing the synthesizer to build up a program from multiple smaller sub-programs. Overall, our empirical evaluation finds that the combination of learning and bottom-up search is remarkably effective, even with simple supervised learning approaches. We demonstrate the effectiveness of our technique on a new data set for synthesis of string transformation programs.
Neural Program Synthesis with a Differentiable Fixer
Jun 19, 2020
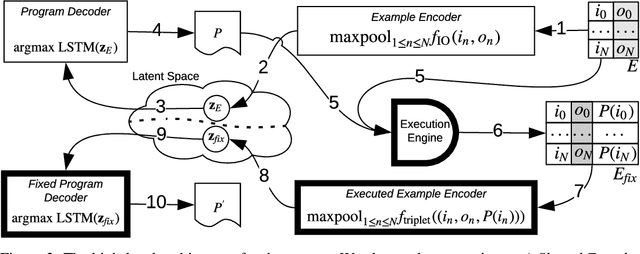
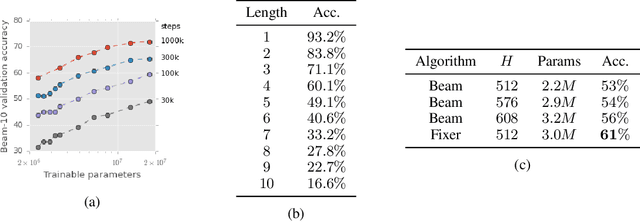
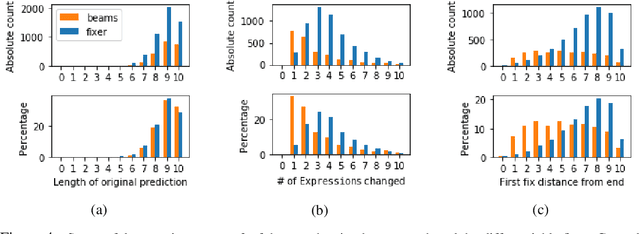
We present a new program synthesis approach that combines an encoder-decoder based synthesis architecture with a differentiable program fixer. Our approach is inspired from the fact that human developers seldom get their program correct on the first attempt, and perform iterative testing-based program fixing to get to the desired program functionality. Similarly, our approach first learns a distribution over programs conditioned on an encoding of a set of input-output examples, and then iteratively performs fix operations using the differentiable fixer. The fixer takes as input the original examples and the current program's outputs on example inputs, and generates a new distribution over the programs with the goal of reducing the discrepancies between the current program outputs and the desired example outputs. We train our architecture end-to-end on the RobustFill domain, and show that the addition of the fixer module leads to a significant improvement on synthesis accuracy compared to using beam search.
SCELMo: Source Code Embeddings from Language Models
Apr 28, 2020



Continuous embeddings of tokens in computer programs have been used to support a variety of software development tools, including readability, code search, and program repair. Contextual embeddings are common in natural language processing but have not been previously applied in software engineering. We introduce a new set of deep contextualized word representations for computer programs based on language models. We train a set of embeddings using the ELMo (embeddings from language models) framework of Peters et al (2018). We investigate whether these embeddings are effective when fine-tuned for the downstream task of bug detection. We show that even a low-dimensional embedding trained on a relatively small corpus of programs can improve a state-of-the-art machine learning system for bug detection.
OptTyper: Probabilistic Type Inference by Optimising Logical and Natural Constraints
Apr 01, 2020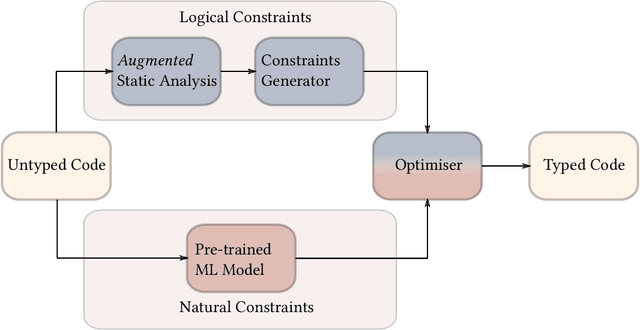

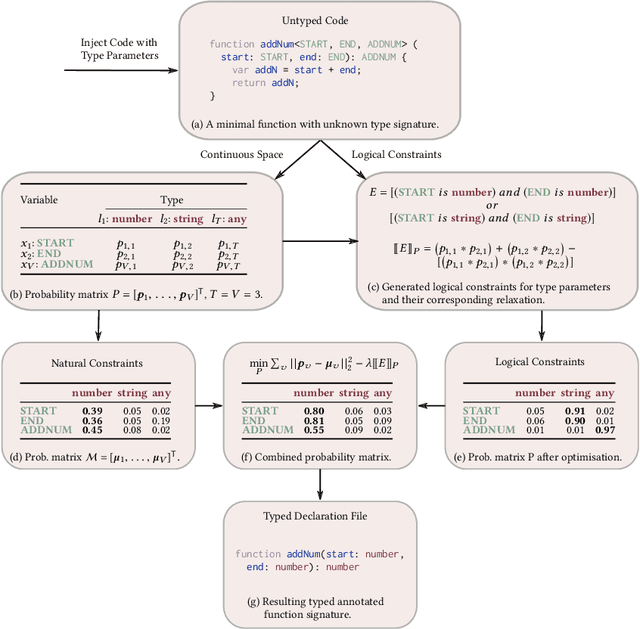

We present a new approach to the type inference problem for dynamic languages. Our goal is to combine logical constraints, that is, deterministic information from a type system, with natural constraints, uncertain information about types from sources like identifier names. To this end, we introduce a framework for probabilistic type inference that combines logic and learning: logical constraints on the types are extracted from the program, and deep learning is applied to predict types from surface-level code properties that are statistically associated, such as variable names. The main insight of our method is to constrain the predictions from the learning procedure to respect the logical constraints, which we achieve by relaxing the logical inference problem of type prediction into a continuous optimisation problem. To evaluate the idea, we built a tool called OptTyper to predict a TypeScript declaration file for a JavaScript library. OptTyper combines a continuous interpretation of logical constraints derived by a simple program transformation and static analysis of the JavaScript code, with natural constraints obtained from a deep learning model, which learns naming conventions for types from a large codebase. We evaluate OptTyper on a data set of 5,800 open-source JavaScript projects that have type annotations in the well-known DefinitelyTyped repository. We find that combining logical and natural constraints yields a large improvement in performance over either kind of information individually, and produces 50% fewer incorrect type predictions than previous approaches.
Towards Modular Algorithm Induction
Feb 27, 2020
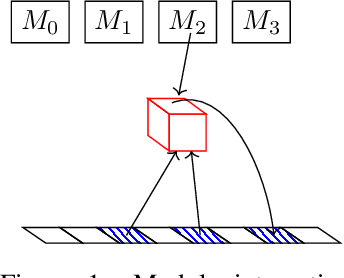
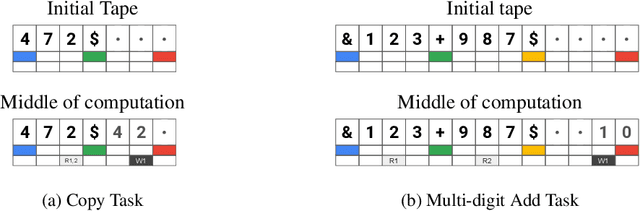
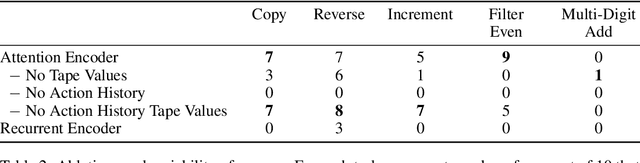
We present a modular neural network architecture Main that learns algorithms given a set of input-output examples. Main consists of a neural controller that interacts with a variable-length input tape and learns to compose modules together with their corresponding argument choices. Unlike previous approaches, Main uses a general domain-agnostic mechanism for selection of modules and their arguments. It uses a general input tape layout together with a parallel history tape to indicate most recently used locations. Finally, it uses a memoryless controller with a length-invariant self-attention based input tape encoding to allow for random access to tape locations. The Main architecture is trained end-to-end using reinforcement learning from a set of input-output examples. We evaluate Main on five algorithmic tasks and show that it can learn policies that generalizes perfectly to inputs of much longer lengths than the ones used for training.
Incremental Sampling Without Replacement for Sequence Models
Feb 21, 2020
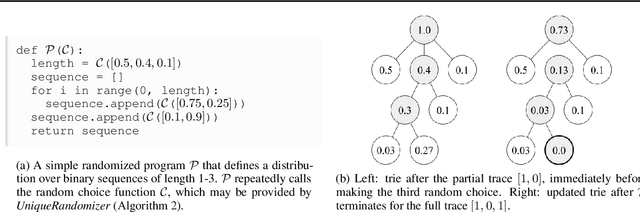
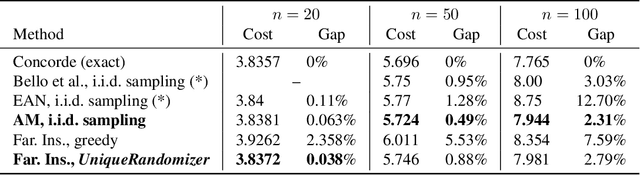
Sampling is a fundamental technique, and sampling without replacement is often desirable when duplicate samples are not beneficial. Within machine learning, sampling is useful for generating diverse outputs from a trained model. We present an elegant procedure for sampling without replacement from a broad class of randomized programs, including generative neural models that construct outputs sequentially. Our procedure is efficient even for exponentially-large output spaces. Unlike prior work, our approach is incremental, i.e., samples can be drawn one at a time, allowing for increased flexibility. We also present a new estimator for computing expectations from samples drawn without replacement. We show that incremental sampling without replacement is applicable to many domains, e.g., program synthesis and combinatorial optimization.
Learning to Represent Programs with Property Signatures
Feb 13, 2020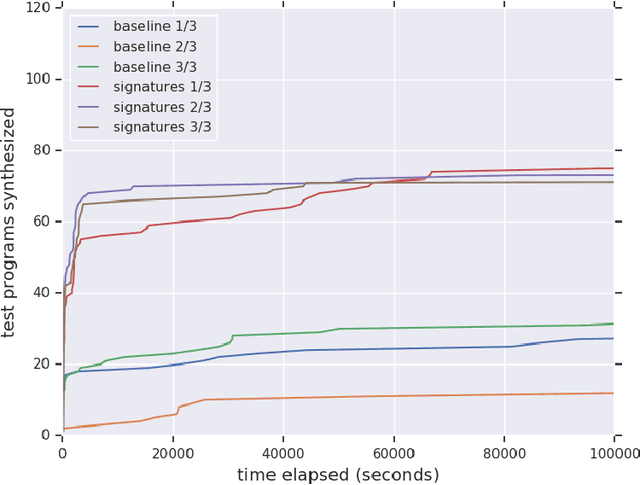
We introduce the notion of property signatures, a representation for programs and program specifications meant for consumption by machine learning algorithms. Given a function with input type $\tau_{in}$ and output type $\tau_{out}$, a property is a function of type: $(\tau_{in}, \tau_{out}) \rightarrow \texttt{Bool}$ that (informally) describes some simple property of the function under consideration. For instance, if $\tau_{in}$ and $\tau_{out}$ are both lists of the same type, one property might ask `is the input list the same length as the output list?'. If we have a list of such properties, we can evaluate them all for our function to get a list of outputs that we will call the property signature. Crucially, we can `guess' the property signature for a function given only a set of input/output pairs meant to specify that function. We discuss several potential applications of property signatures and show experimentally that they can be used to improve over a baseline synthesizer so that it emits twice as many programs in less than one-tenth of the time.
Learning to Fix Build Errors with Graph2Diff Neural Networks
Nov 04, 2019

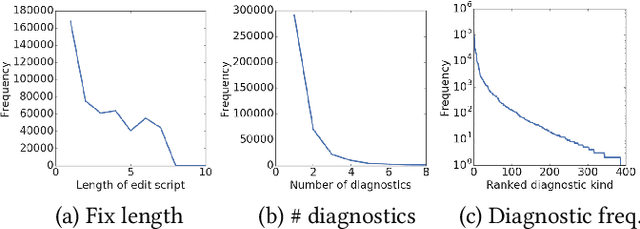

Professional software developers spend a significant amount of time fixing builds, but this has received little attention as a problem in automatic program repair. We present a new deep learning architecture, called Graph2Diff, for automatically localizing and fixing build errors. We represent source code, build configuration files, and compiler diagnostic messages as a graph, and then use a Graph Neural Network model to predict a diff. A diff specifies how to modify the code's abstract syntax tree, represented in the neural network as a sequence of tokens and of pointers to code locations. Our network is an instance of a more general abstraction that we call Graph2Tocopo, which is potentially useful in any development tool for predicting source code changes. We evaluate the model on a dataset of over 500k real build errors and their resolutions from professional developers. Compared to the approach of DeepDelta (Mesbah et al., 2019), our approach tackles the harder task of predicting a more precise diff but still achieves over double the accuracy.
Robust Variational Autoencoders for Outlier Detection in Mixed-Type Data
Jul 15, 2019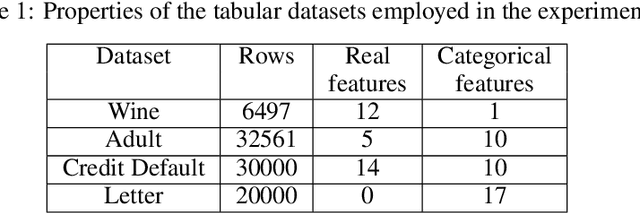

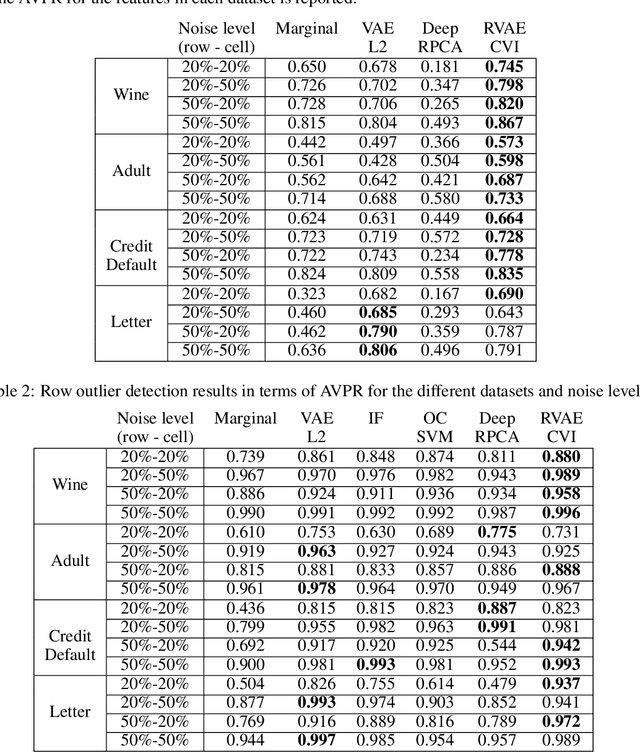

We focus on the problem of unsupervised cell outlier detection in mixed type tabular datasets. Traditional methods for outlier detection are concerned only on detecting which rows in the dataset are outliers. However, identifying which cells in the dataset corrupt a specific row is an important problem in practice, especially in high-dimensional tables. We introduce the Robust Variational Autoencoder (RVAE), a deep generative model that learns the joint distribution of the clean data while identifying the outlier cells in the dataset. RVAE learns the probability of each cell in the dataset being an outlier, balancing the contributions of the different likelihood models in the row outlier score, making the method suitable for outlier detection in mixed type datasets. We show experimentally that the RVAE performs better than several state of the art methods in cell outlier detection for tabular datasets, while providing comparable or better results for row outlier detection.