 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Restructuring of Categories and Implementation of Guidelines Essential for VLM Adoption in Healthcare
May 12, 2025The intricate and multifaceted nature of vision language model (VLM) development, adaptation, and application necessitates the establishment of clear and standardized reporting protocols, particularly within the high-stakes context of healthcare. Defining these reporting standards is inherently challenging due to the diverse nature of studies involving VLMs, which vary significantly from the development of all new VLMs or finetuning for domain alignment to off-the-shelf use of VLM for targeted diagnosis and prediction tasks. In this position paper, we argue that traditional machine learning reporting standards and evaluation guidelines must be restructured to accommodate multiphase VLM studies; it also has to be organized for intuitive understanding of developers while maintaining rigorous standards for reproducibility. To facilitate community adoption, we propose a categorization framework for VLM studies and outline corresponding reporting standards that comprehensively address performance evaluation, data reporting protocols, and recommendations for manuscript composition. These guidelines are organized according to the proposed categorization scheme. Lastly, we present a checklist that consolidates reporting standards, offering a standardized tool to ensure consistency and quality in the publication of VLM-related research.
Multimodal Machine Learning in Image-Based and Clinical Biomedicine: Survey and Prospects
Nov 20, 2023Machine learning (ML) applications in medical artificial intelligence (AI) systems have shifted from traditional and statistical methods to increasing application of deep learning models. This survey navigates the current landscape of multimodal ML, focusing on its profound impact on medical image analysis and clinical decision support systems. Emphasizing challenges and innovations in addressing multimodal representation, fusion, translation, alignment, and co-learning, the paper explores the transformative potential of multimodal models for clinical predictions. It also questions practical implementation of such models, bringing attention to the dynamics between decision support systems and healthcare providers. Despite advancements, challenges such as data biases and the scarcity of "big data" in many biomedical domains persist. We conclude with a discussion on effective innovation and collaborative efforts to further the miss
Learning-Based Radiomic Prediction of Type 2 Diabetes Mellitus Using Image-Derived Phenotypes
Sep 20, 2022

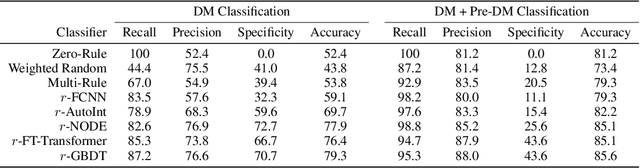
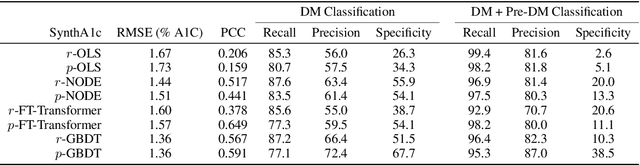
Early diagnosis of Type 2 Diabetes Mellitus (T2DM) is crucial to enable timely therapeutic interventions and lifestyle modifications. As medical imaging data become more widely available for many patient populations, we sought to investigate whether image-derived phenotypic data could be leveraged in tabular learning classifier models to predict T2DM incidence without the use of invasive blood lab measurements. We show that both neural network and decision tree models that use image-derived phenotypes can predict patient T2DM status with recall scores as high as 87.6%. We also propose the novel use of these same architectures as 'SynthA1c encoders' that are able to output interpretable values mimicking blood hemoglobin A1C empirical lab measurements. Finally, we demonstrate that T2DM risk prediction model sensitivity to small perturbations in input vector components can be used to predict performance on covariates sampled from previously unseen patient populations.