 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-aware Human Motion Forecasting via Mutual Distance Prediction
Oct 01, 2023



In this paper, we tackle the problem of scene-aware 3D human motion forecasting. A key challenge of this task is to predict future human motions that are consistent with the scene, by modelling the human-scene interactions. While recent works have demonstrated that explicit constraints on human-scene interactions can prevent the occurrence of ghost motion, they only provide constraints on partial human motion e.g., the global motion of the human or a few joints contacting the scene, leaving the rest motion unconstrained. To address this limitation, we propose to model the human-scene interaction with the mutual distance between the human body and the scene. Such mutual distances constrain both the local and global human motion, resulting in a whole-body motion constrained prediction. In particular, mutual distance constraints consist of two components, the signed distance of each vertex on the human mesh to the scene surface, and the distance of basis scene points to the human mesh. We develop a pipeline with two prediction steps that first predicts the future mutual distances from the past human motion sequence and the scene, and then forecasts the future human motion conditioning on the predicted mutual distances. During training, we explicitly encourage consistency between the predicted poses and the mutual distances. Our approach outperforms the state-of-the-art methods on both synthetic and real datasets.
P2C: Self-Supervised Point Cloud Completion from Single Partial Clouds
Jul 27, 2023



Point cloud completion aims to recover the complete shape based on a partial observation. Existing methods require either complete point clouds or multiple partial observations of the same object for learning. In contrast to previous approaches, we present Partial2Complete (P2C), the first self-supervised framework that completes point cloud objects using training samples consisting of only a single incomplete point cloud per object. Specifically, our framework groups incomplete point clouds into local patches as input and predicts masked patches by learning prior information from different partial objects. We also propose Region-Aware Chamfer Distance to regularize shape mismatch without limiting completion capability, and devise the Normal Consistency Constraint to incorporate a local planarity assumption, encouraging the recovered shape surface to be continuous and complete. In this way, P2C no longer needs multiple observations or complete point clouds as ground truth. Instead, structural cues are learned from a category-specific dataset to complete partial point clouds of objects. We demonstrate the effectiveness of our approach on both synthetic ShapeNet data and real-world ScanNet data, showing that P2C produces comparable results to methods trained with complete shapes, and outperforms methods learned with multiple partial observations. Code is available at https://github.com/CuiRuikai/Partial2Complete.
Disguising Personal Identity Information in EEG Signals
Oct 18, 2020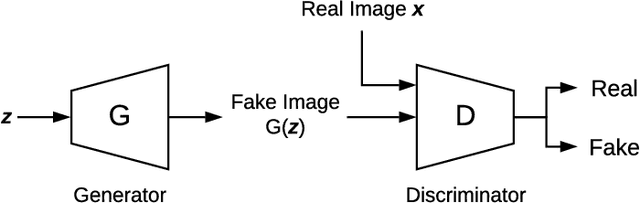
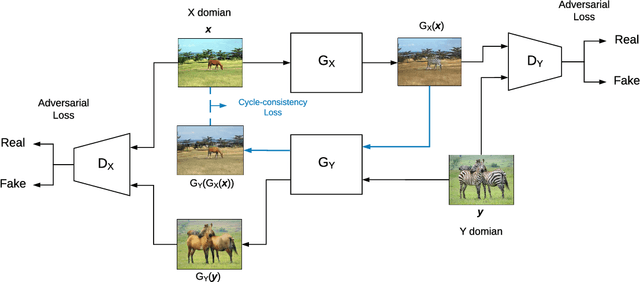
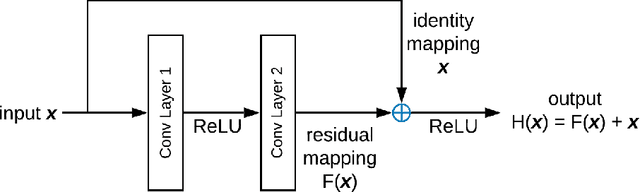
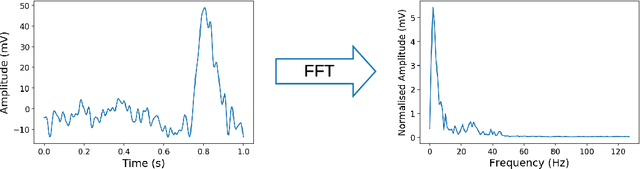
There is a need to protect the personal identity information in public EEG datasets. However, it is challenging to remove such information that has infinite classes (open set). We propose an approach to disguise the identity information in EEG signals with dummy identities, while preserving the key features. The dummy identities are obtained by applying grand average on EEG spectrums across the subjects within a group that have common attributes. The personal identity information in original EEGs are transformed into disguised ones with a CycleGANbased EEG disguising model. With the constraints added to the model, the features of interest in EEG signals can be preserved. We evaluate the model by performing classification tasks on both the original and the disguised EEG and compare the results. For evaluation, we also experiment with ResNet classifiers, which perform well especially on the identity recognition task with an accuracy of 98.4%. The results show that our EEG disguising model can hide about 90% of personal identity information and can preserve most of the other key features.