 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Graph Convolution for Skeleton Based Action Recognition
Feb 27, 2018
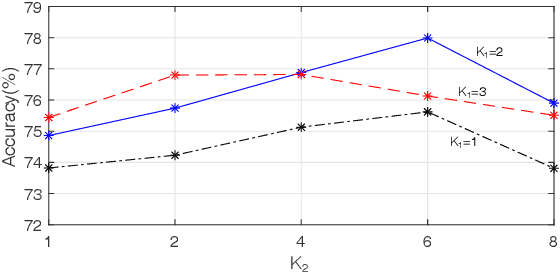
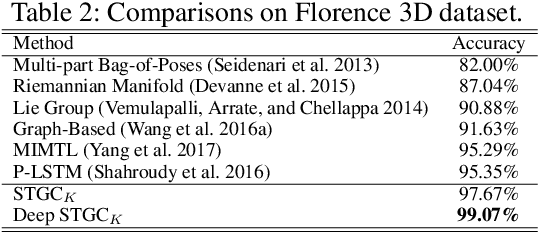
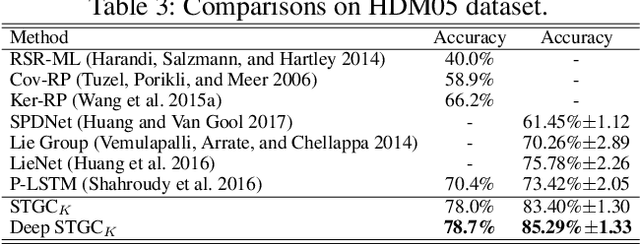
Variations of human body skeletons may be considered as dynamic graphs, which are generic data representation for numerous real-world applications. In this paper, we propose a spatio-temporal graph convolution (STGC) approach for assembling the successes of local convolutional filtering and sequence learning ability of autoregressive moving average. To encode dynamic graphs, the constructed multi-scale local graph convolution filters, consisting of matrices of local receptive fields and signal mappings, are recursively performed on structured graph data of temporal and spatial domain. The proposed model is generic and principled as it can be generalized into other dynamic models. We theoretically prove the stability of STGC and provide an upper-bound of the signal transformation to be learnt. Further, the proposed recursive model can be stacked into a multi-layer architecture. To evaluate our model, we conduct extensive experiments on four benchmark skeleton-based action datasets, including the large-scale challenging NTU RGB+D. The experimental results demonstrate the effectiveness of our proposed model and the improvement over the state-of-the-art.
Action-Attending Graphic Neural Network
Nov 17, 2017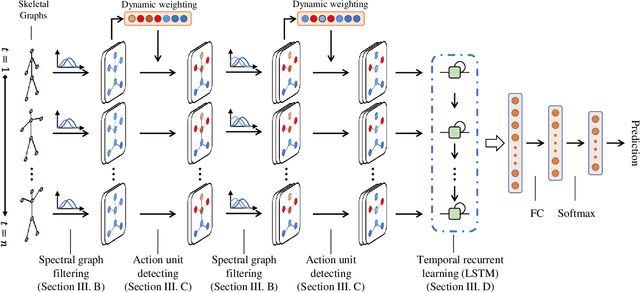
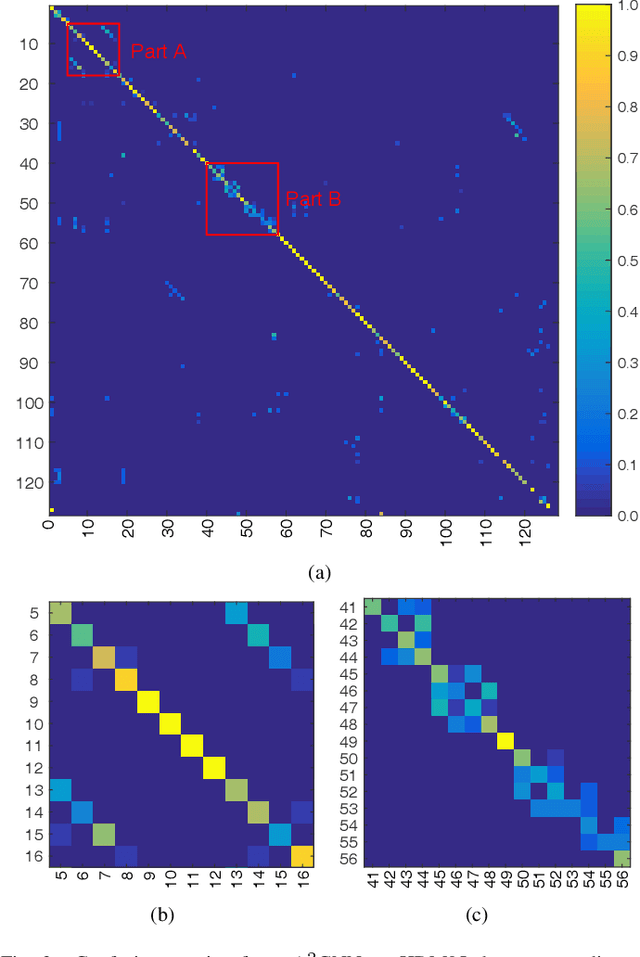
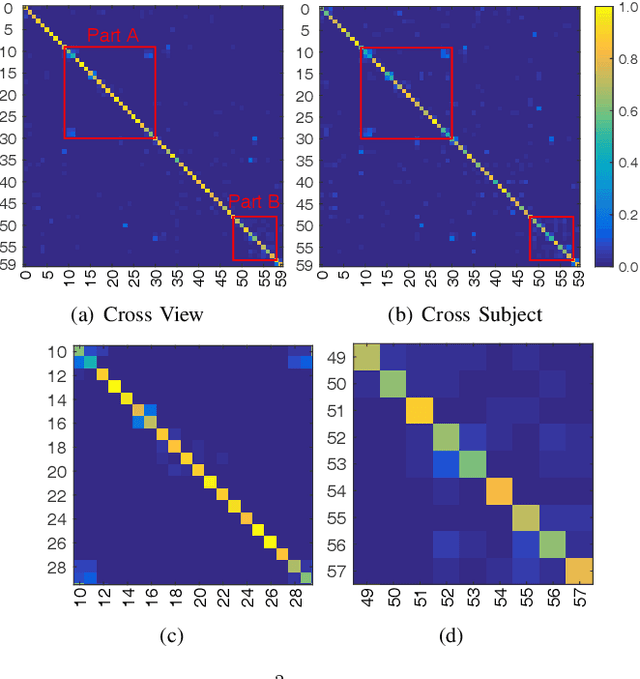
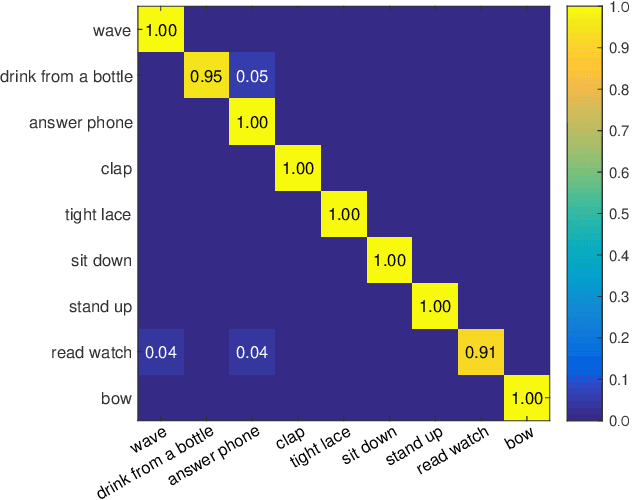
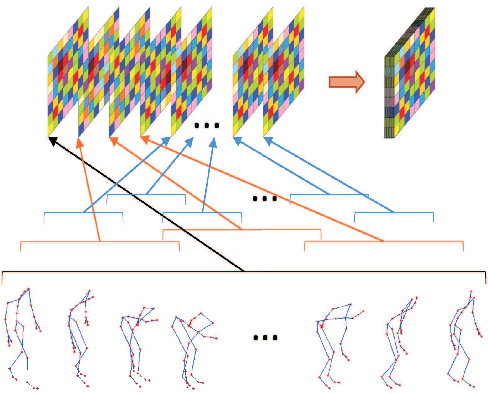
The motion analysis of human skeletons is crucial for human action recognition, which is one of the most active topics in computer vision. In this paper, we propose a fully end-to-end action-attending graphic neural network (A$^2$GNN) for skeleton-based action recognition, in which each irregular skeleton is structured as an undirected attribute graph. To extract high-level semantic representation from skeletons, we perform the local spectral graph filtering on the constructed attribute graphs like the standard image convolution operation. Considering not all joints are informative for action analysis, we design an action-attending layer to detect those salient action units (AUs) by adaptively weighting skeletal joints. Herein the filtering responses are parameterized into a weighting function irrelevant to the order of input nodes. To further encode continuous motion variations, the deep features learnt from skeletal graphs are gathered along consecutive temporal slices and then fed into a recurrent gated network. Finally, the spectral graph filtering, action-attending and recurrent temporal encoding are integrated together to jointly train for the sake of robust action recognition as well as the intelligibility of human actions. To evaluate our A$^2$GNN, we conduct extensive experiments on four benchmark skeleton-based action datasets, including the large-scale challenging NTU RGB+D dataset. The experimental results demonstrate that our network achieves the state-of-the-art performances.
Deep manifold-to-manifold transforming network for action recognition
Sep 30, 2017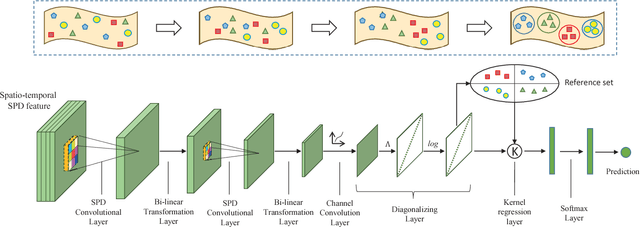

Symmetric positive definite (SPD) matrices (e.g., covariances, graph Laplacians, etc.) are widely used to model the relationship of spatial or temporal domain. Nevertheless, SPD matrices are theoretically embedded on Riemannian manifolds. In this paper, we propose an end-to-end deep manifold-to-manifold transforming network (DMT-Net) which can make SPD matrices flow from one Riemannian manifold to another more discriminative one. To learn discriminative SPD features characterizing both spatial and temporal dependencies, we specifically develop three novel layers on manifolds: (i) the local SPD convolutional layer, (ii) the non-linear SPD activation layer, and (iii) the Riemannian-preserved recursive layer. The SPD property is preserved through all layers without any requirement of singular value decomposition (SVD), which is often used in the existing methods with expensive computation cost. Furthermore, a diagonalizing SPD layer is designed to efficiently calculate the final metric for the classification task. To evaluate our proposed method, we conduct extensive experiments on the task of action recognition, where input signals are popularly modeled as SPD matrices. The experimental results demonstrate that our DMT-Net is much more competitive over state-of-the-art.