 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderwater Image Enhancement with Physical-based Denoising Diffusion Implicit Models
Sep 27, 2024



Underwater vision is crucial for autonomous underwater vehicles (AUVs), and enhancing degraded underwater images in real-time on a resource-constrained AUV is a key challenge due to factors like light absorption and scattering, or the sufficient model computational complexity to resolve such factors. Traditional image enhancement techniques lack adaptability to varying underwater conditions, while learning-based methods, particularly those using convolutional neural networks (CNNs) and generative adversarial networks (GANs), offer more robust solutions but face limitations such as inadequate enhancement, unstable training, or mode collapse. Denoising diffusion probabilistic models (DDPMs) have emerged as a state-of-the-art approach in image-to-image tasks but require intensive computational complexity to achieve the desired underwater image enhancement (UIE) using the recent UW-DDPM solution. To address these challenges, this paper introduces UW-DiffPhys, a novel physical-based and diffusion-based UIE approach. UW-DiffPhys combines light-computation physical-based UIE network components with a denoising U-Net to replace the computationally intensive distribution transformation U-Net in the existing UW-DDPM framework, reducing complexity while maintaining performance. Additionally, the Denoising Diffusion Implicit Model (DDIM) is employed to accelerate the inference process through non-Markovian sampling. Experimental results demonstrate that UW-DiffPhys achieved a substantial reduction in computational complexity and inference time compared to UW-DDPM, with competitive performance in key metrics such as PSNR, SSIM, UCIQE, and an improvement in the overall underwater image quality UIQM metric. The implementation code can be found at the following repository: https://github.com/bachzz/UW-DiffPhys
Attenuation-Aware Weighted Optical Flow with Medium Transmission Map for Learning-based Visual Odometry in Underwater terrain
Jul 18, 2024



This paper addresses the challenge of improving learning-based monocular visual odometry (VO) in underwater environments by integrating principles of underwater optical imaging to manipulate optical flow estimation. Leveraging the inherent properties of underwater imaging, the novel wflow-TartanVO is introduced, enhancing the accuracy of VO systems for autonomous underwater vehicles (AUVs). The proposed method utilizes a normalized medium transmission map as a weight map to adjust the estimated optical flow for emphasizing regions with lower degradation and suppressing uncertain regions affected by underwater light scattering and absorption. wflow-TartanVO does not require fine-tuning of pre-trained VO models, thus promoting its adaptability to different environments and camera models. Evaluation of different real-world underwater datasets demonstrates the outperformance of wflow-TartanVO over baseline VO methods, as evidenced by the considerably reduced Absolute Trajectory Error (ATE). The implementation code is available at: https://github.com/bachzz/wflow-TartanVO
Novel projection schemes for graph-based Light Field coding
Jun 09, 2022
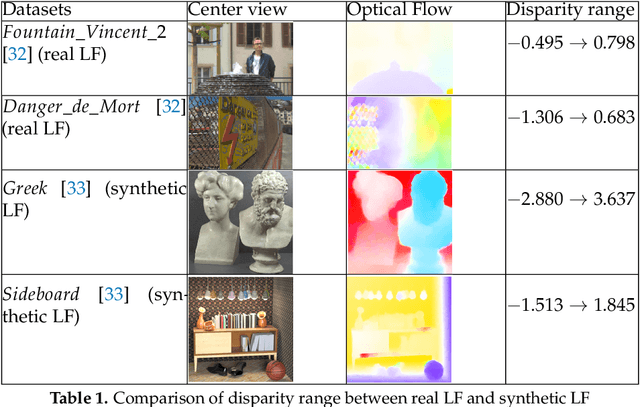


In Light Field compression, graph-based coding is powerful to exploit signal redundancy along irregular shapes and obtains good energy compaction. However, apart from high time complexity to process high dimensional graphs, their graph construction method is highly sensitive to the accuracy of disparity information between viewpoints. In real world Light Field or synthetic Light Field generated by computer software, the use of disparity information for super-rays projection might suffer from inaccuracy due to vignetting effect and large disparity between views in the two types of Light Fields respectively. This paper introduces two novel projection schemes resulting in less error in disparity information, in which one projection scheme can also significantly reduce time computation for both encoder and decoder. Experimental results show projection quality of super-pixels across views can be considerably enhanced using the proposals, along with rate-distortion performance when compared against original projection scheme and HEVC-based or JPEG Pleno-based coding approaches.