 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Contrastive Learning on Wearable Timeseries for Downstream Clinical Outcomes
Nov 13, 2021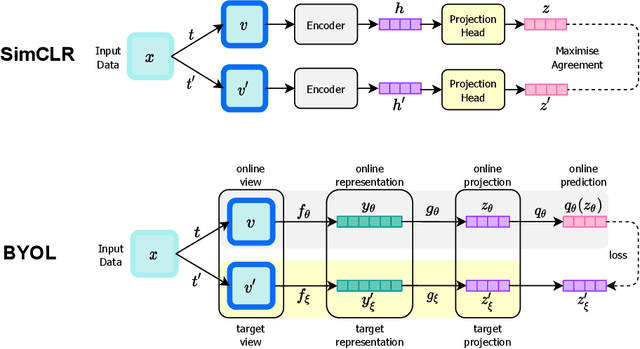
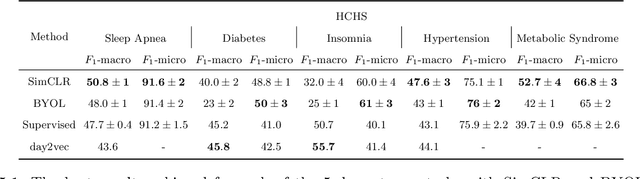
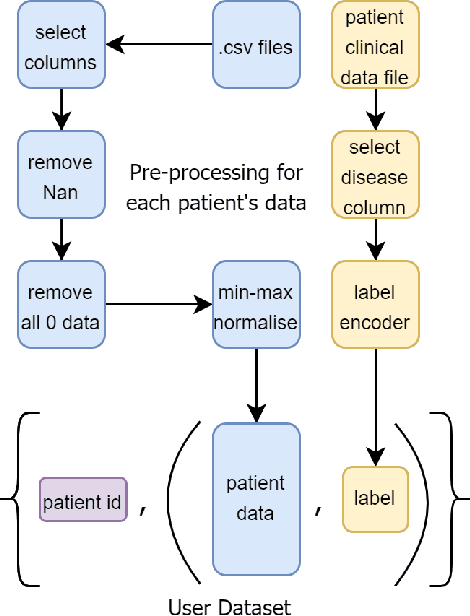
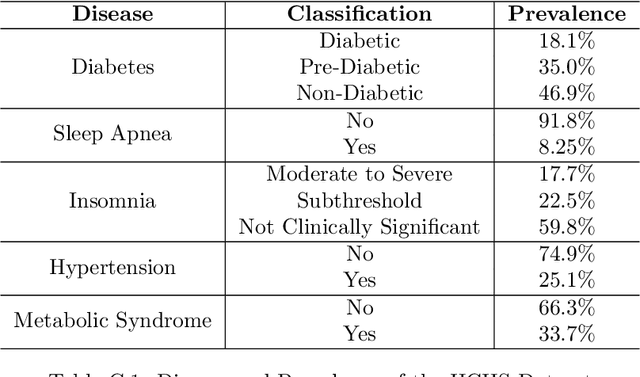
Vast quantities of person-generated health data (wearables) are collected but the process of annotating to feed to machine learning models is impractical. This paper discusses ways in which self-supervised approaches that use contrastive losses, such as SimCLR and BYOL, previously applied to the vision domain, can be applied to high-dimensional health signals for downstream classification tasks of various diseases spanning sleep, heart, and metabolic conditions. To this end, we adapt the data augmentation step and the overall architecture to suit the temporal nature of the data (wearable traces) and evaluate on 5 downstream tasks by comparing other state-of-the-art methods including supervised learning and an adversarial unsupervised representation learning method. We show that SimCLR outperforms the adversarial method and a fully-supervised method in the majority of the downstream evaluation tasks, and that all self-supervised methods outperform the fully-supervised methods. This work provides a comprehensive benchmark for contrastive methods applied to the wearable time-series domain, showing the promise of task-agnostic representations for downstream clinical outcomes.
Exploring System Performance of Continual Learning for Mobile and Embedded Sensing Applications
Oct 25, 2021
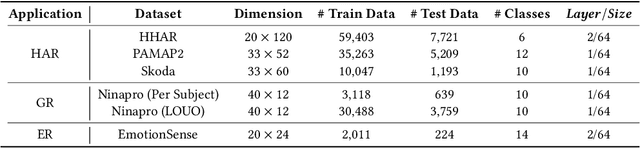
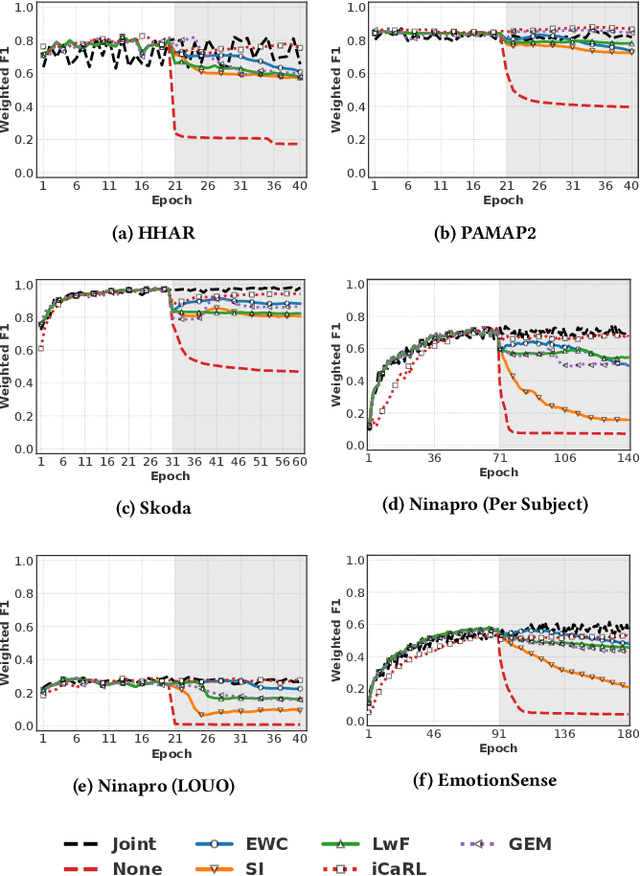
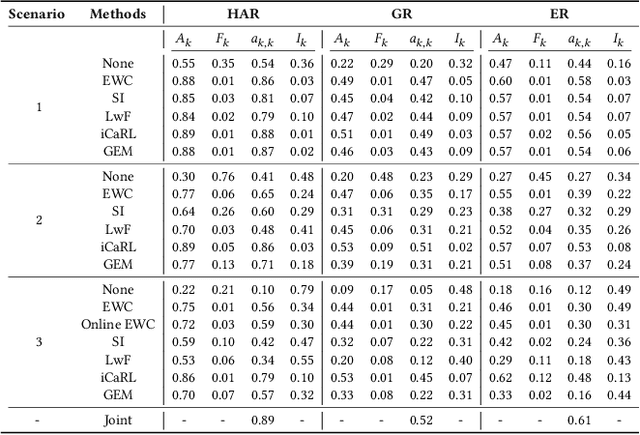
Continual learning approaches help deep neural network models adapt and learn incrementally by trying to solve catastrophic forgetting. However, whether these existing approaches, applied traditionally to image-based tasks, work with the same efficacy to the sequential time series data generated by mobile or embedded sensing systems remains an unanswered question. To address this void, we conduct the first comprehensive empirical study that quantifies the performance of three predominant continual learning schemes (i.e., regularization, replay, and replay with examples) on six datasets from three mobile and embedded sensing applications in a range of scenarios having different learning complexities. More specifically, we implement an end-to-end continual learning framework on edge devices. Then we investigate the generalizability, trade-offs between performance, storage, computational costs, and memory footprint of different continual learning methods. Our findings suggest that replay with exemplars-based schemes such as iCaRL has the best performance trade-offs, even in complex scenarios, at the expense of some storage space (few MBs) for training examples (1% to 5%). We also demonstrate for the first time that it is feasible and practical to run continual learning on-device with a limited memory budget. In particular, the latency on two types of mobile and embedded devices suggests that both incremental learning time (few seconds - 4 minutes) and training time (1 - 75 minutes) across datasets are acceptable, as training could happen on the device when the embedded device is charging thereby ensuring complete data privacy. Finally, we present some guidelines for practitioners who want to apply a continual learning paradigm for mobile sensing tasks.
Earables for Detection of Bruxism: a Feasibility Study
Aug 09, 2021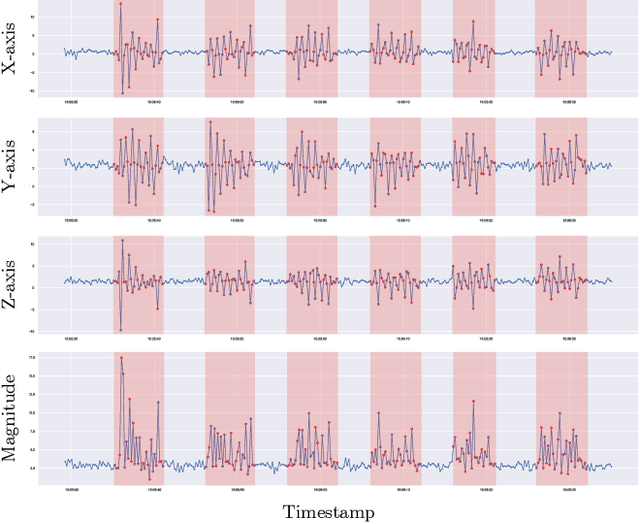
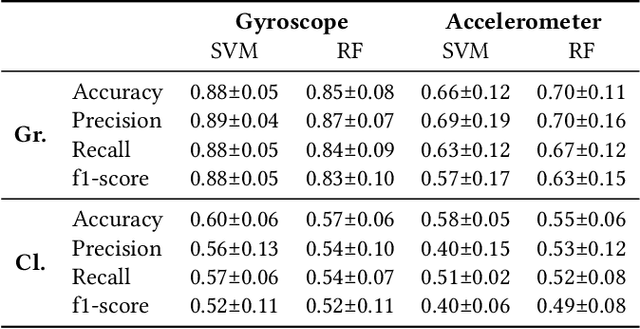
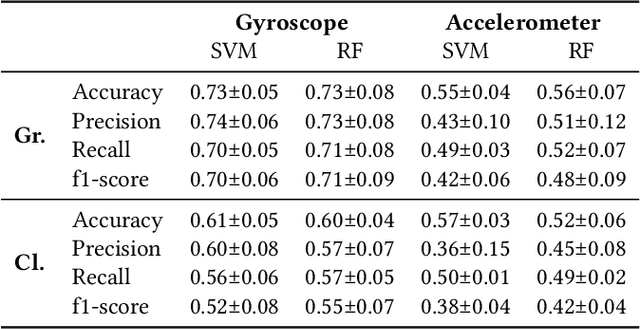
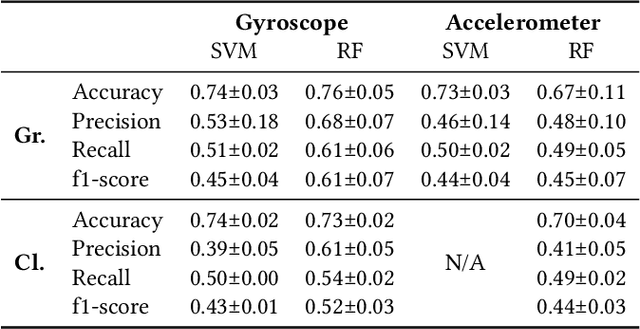
Bruxism is a disorder characterised by teeth grinding and clenching, and many bruxism sufferers are not aware of this disorder until their dental health professional notices permanent teeth wear. Stress and anxiety are often listed among contributing factors impacting bruxism exacerbation, which may explain why the COVID-19 pandemic gave rise to a bruxism epidemic. It is essential to develop tools allowing for the early diagnosis of bruxism in an unobtrusive manner. This work explores the feasibility of detecting bruxism-related events using earables in a mimicked in-the-wild setting. Using inertial measurement unit for data collection, we utilise traditional machine learning for teeth grinding and clenching detection. We observe superior performance of models based on gyroscope data, achieving an 88% and 66% accuracy on grinding and clenching activities, respectively, in a controlled environment, and 76% and 73% on grinding and clenching, respectively, in an in-the-wild environment.
Segmentation-free Heart Pathology Detection Using Deep Learning
Aug 09, 2021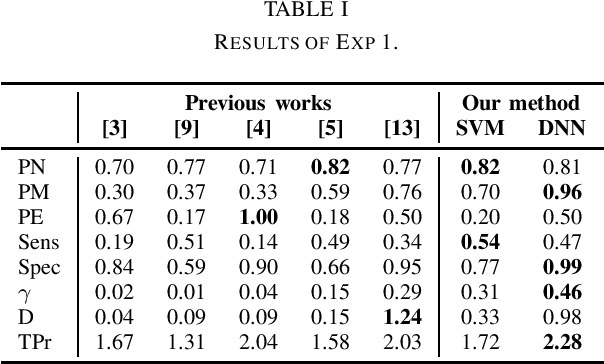
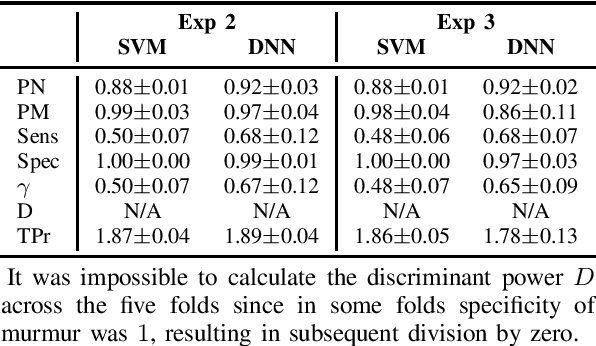
Cardiovascular (CV) diseases are the leading cause of death in the world, and auscultation is typically an essential part of a cardiovascular examination. The ability to diagnose a patient based on their heart sounds is a rather difficult skill to master. Thus, many approaches for automated heart auscultation have been explored. However, most of the previously proposed methods involve a segmentation step, the performance of which drops significantly for high pulse rates or noisy signals. In this work, we propose a novel segmentation-free heart sound classification method. Specifically, we apply discrete wavelet transform to denoise the signal, followed by feature extraction and feature reduction. Then, Support Vector Machines and Deep Neural Networks are utilised for classification. On the PASCAL heart sound dataset our approach showed superior performance compared to others, achieving 81% and 96% precision on normal and murmur classes, respectively. In addition, for the first time, the data were further explored under a user-independent setting, where the proposed method achieved 92% and 86% precision on normal and murmur, demonstrating the potential of enabling automatic murmur detection for practical use.
High Frequency EEG Artifact Detection with Uncertainty via Early Exit Paradigm
Jul 21, 2021
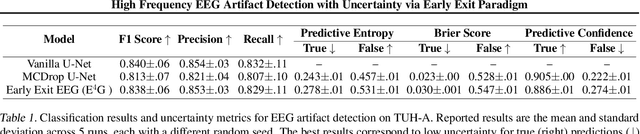
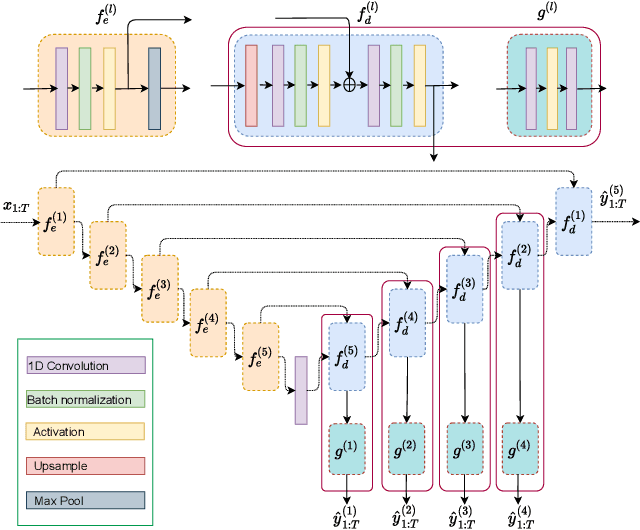
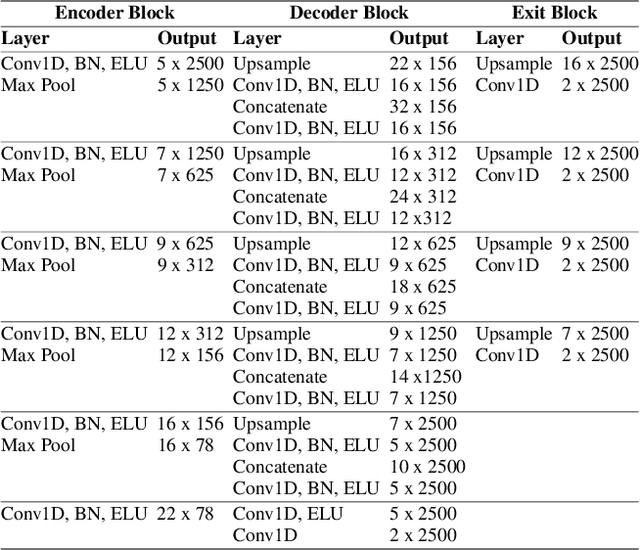
Electroencephalography (EEG) is crucial for the monitoring and diagnosis of brain disorders. However, EEG signals suffer from perturbations caused by non-cerebral artifacts limiting their efficacy. Current artifact detection pipelines are resource-hungry and rely heavily on hand-crafted features. Moreover, these pipelines are deterministic in nature, making them unable to capture predictive uncertainty. We propose E4G, a deep learning framework for high frequency EEG artifact detection. Our framework exploits the early exit paradigm, building an implicit ensemble of models capable of capturing uncertainty. We evaluate our approach on the Temple University Hospital EEG Artifact Corpus (v2.0) achieving state-of-the-art classification results. In addition, E4G provides well-calibrated uncertainty metrics comparable to sampling techniques like Monte Carlo dropout in just a single forward pass. E4G opens the door to uncertainty-aware artifact detection supporting clinicians-in-the-loop frameworks.
Sounds of COVID-19: exploring realistic performance of audio-based digital testing
Jun 29, 2021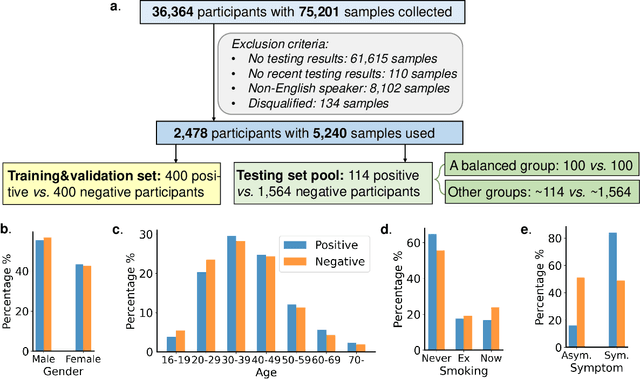
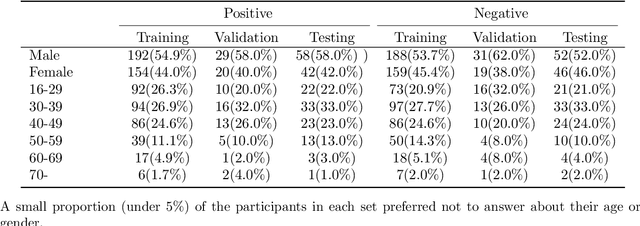
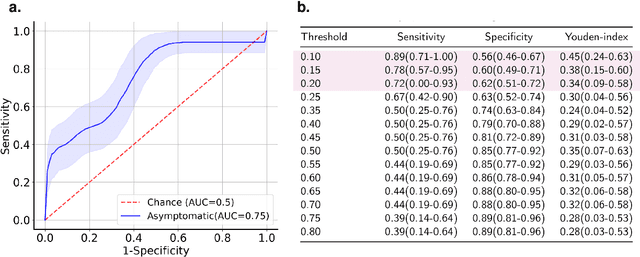
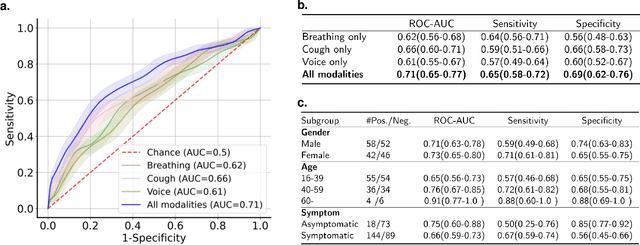
Researchers have been battling with the question of how we can identify Coronavirus disease (COVID-19) cases efficiently, affordably and at scale. Recent work has shown how audio based approaches, which collect respiratory audio data (cough, breathing and voice) can be used for testing, however there is a lack of exploration of how biases and methodological decisions impact these tools' performance in practice. In this paper, we explore the realistic performance of audio-based digital testing of COVID-19. To investigate this, we collected a large crowdsourced respiratory audio dataset through a mobile app, alongside recent COVID-19 test result and symptoms intended as a ground truth. Within the collected dataset, we selected 5,240 samples from 2,478 participants and split them into different participant-independent sets for model development and validation. Among these, we controlled for potential confounding factors (such as demographics and language). The unbiased model takes features extracted from breathing, coughs, and voice signals as predictors and yields an AUC-ROC of 0.71 (95\% CI: 0.65$-$0.77). We further explore different unbalanced distributions to show how biases and participant splits affect performance. Finally, we discuss how the realistic model presented could be integrated in clinical practice to realize continuous, ubiquitous, sustainable and affordable testing at population scale.
FastICARL: Fast Incremental Classifier and Representation Learning with Efficient Budget Allocation in Audio Sensing Applications
Jun 24, 2021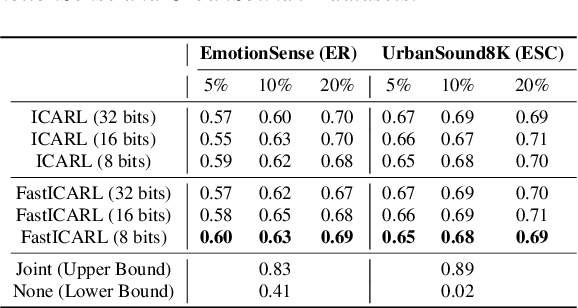
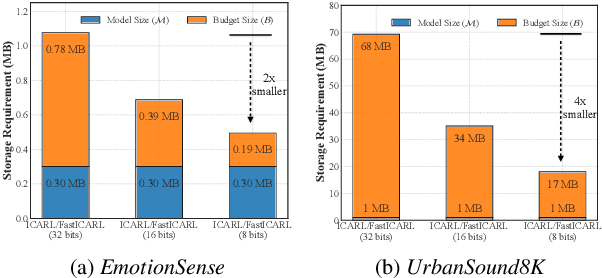
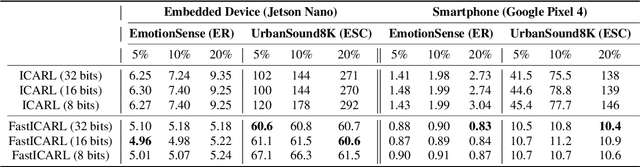
Various incremental learning (IL) approaches have been proposed to help deep learning models learn new tasks/classes continuously without forgetting what was learned previously (i.e., avoid catastrophic forgetting). With the growing number of deployed audio sensing applications that need to dynamically incorporate new tasks and changing input distribution from users, the ability of IL on-device becomes essential for both efficiency and user privacy. However, prior works suffer from high computational costs and storage demands which hinders the deployment of IL on-device. In this work, to overcome these limitations, we develop an end-to-end and on-device IL framework, FastICARL, that incorporates an exemplar-based IL and quantization in the context of audio-based applications. We first employ k-nearest-neighbor to reduce the latency of IL. Then, we jointly utilize a quantization technique to decrease the storage requirements of IL. We implement FastICARL on two types of mobile devices and demonstrate that FastICARL remarkably decreases the IL time up to 78-92% and the storage requirements by 2-4 times without sacrificing its performance. FastICARL enables complete on-device IL, ensuring user privacy as the user data does not need to leave the device.
Anticipatory Detection of Compulsive Body-focused Repetitive Behaviors with Wearables
Jun 21, 2021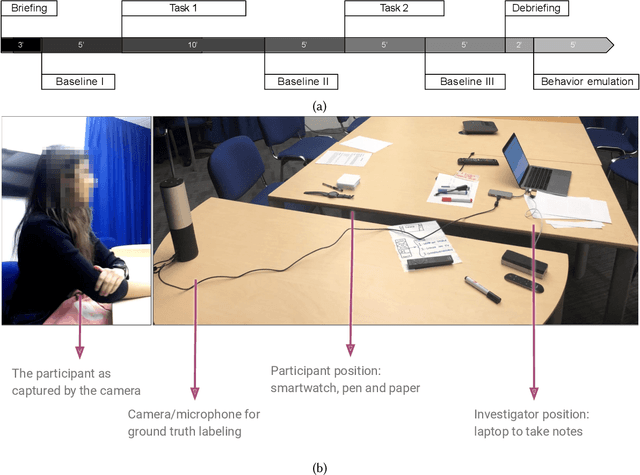

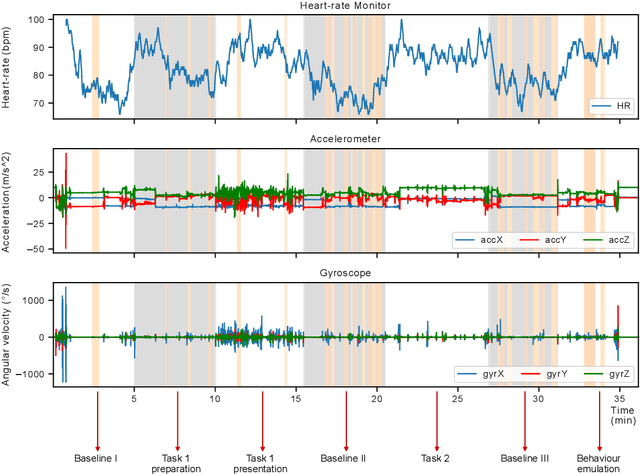
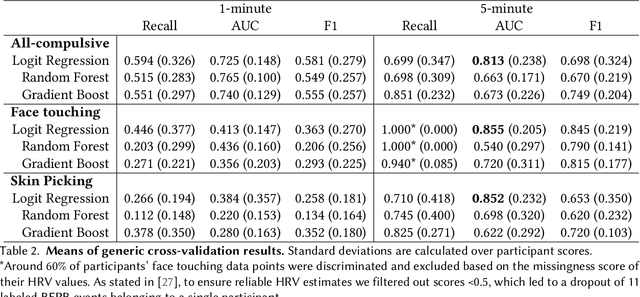
Body-focused repetitive behaviors (BFRBs), like face-touching or skin-picking, are hand-driven behaviors which can damage one's appearance, if not identified early and treated. Technology for automatic detection is still under-explored, with few previous works being limited to wearables with single modalities (e.g., motion). Here, we propose a multi-sensory approach combining motion, orientation, and heart rate sensors to detect BFRBs. We conducted a feasibility study in which participants (N=10) were exposed to BFRBs-inducing tasks, and analyzed 380 mins of signals under an extensive evaluation of sensing modalities, cross-validation methods, and observation windows. Our models achieved an AUC > 0.90 in distinguishing BFRBs, which were more evident in observation windows 5 mins prior to the behavior as opposed to 1-min ones. In a follow-up qualitative survey, we found that not only the timing of detection matters but also models need to be context-aware, when designing just-in-time interventions to prevent BFRBs.
Knowing when we do not know: Bayesian continual learning for sensing-based analysis tasks
Jun 06, 2021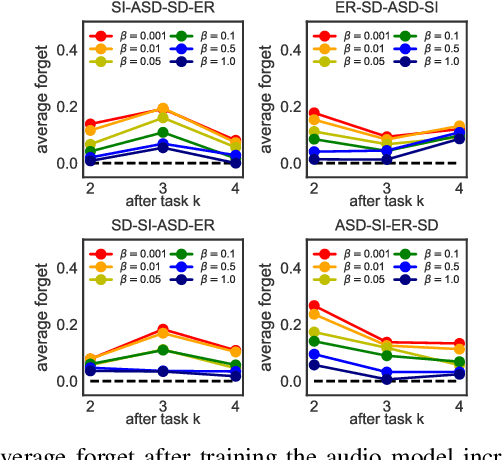
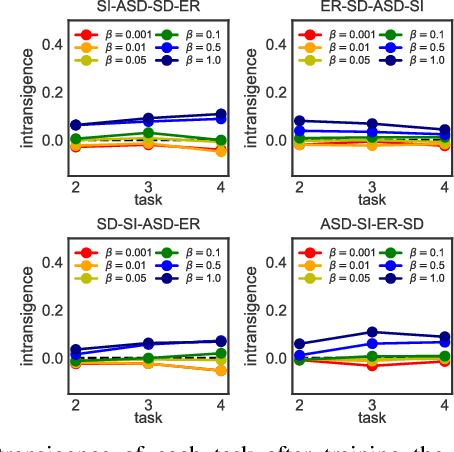
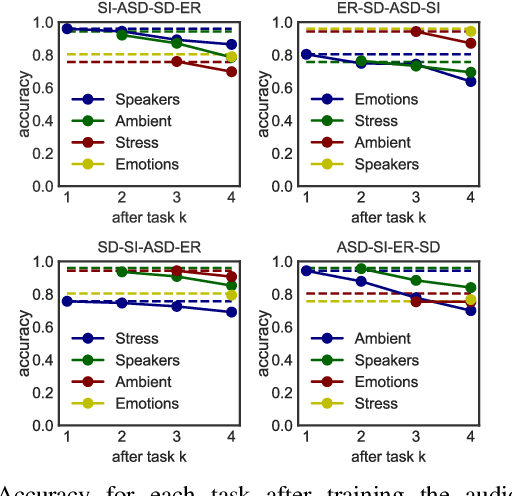
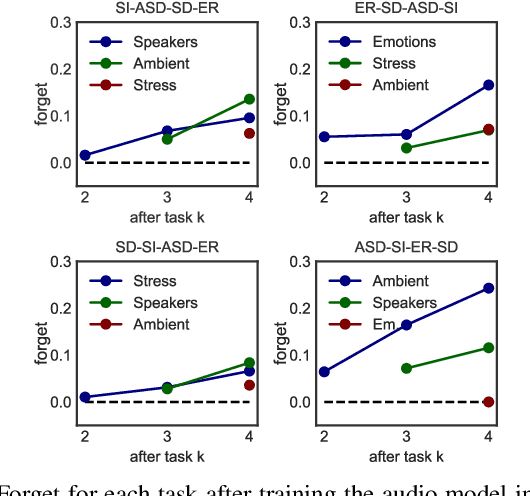
Despite much research targeted at enabling conventional machine learning models to continually learn tasks and data distributions sequentially without forgetting the knowledge acquired, little effort has been devoted to account for more realistic situations where learning some tasks accurately might be more critical than forgetting previous ones. In this paper we propose a Bayesian inference based framework to continually learn a set of real-world, sensing-based analysis tasks that can be tuned to prioritize the remembering of previously learned tasks or the learning of new ones. Our experiments prove the robustness and reliability of the learned models to adapt to the changing sensing environment, and show the suitability of using uncertainty of the predictions to assess their reliability.
Modelling Urban Dynamics with Multi-Modal Graph Convolutional Networks
Apr 29, 2021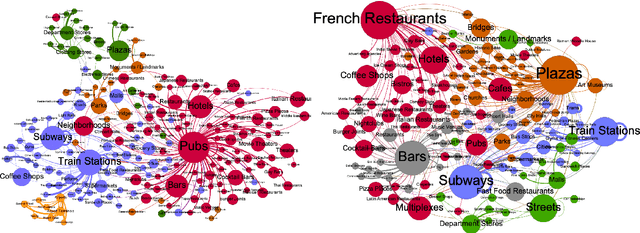
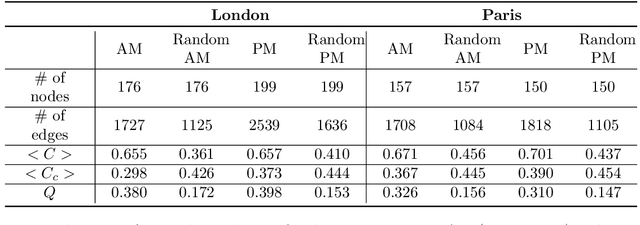
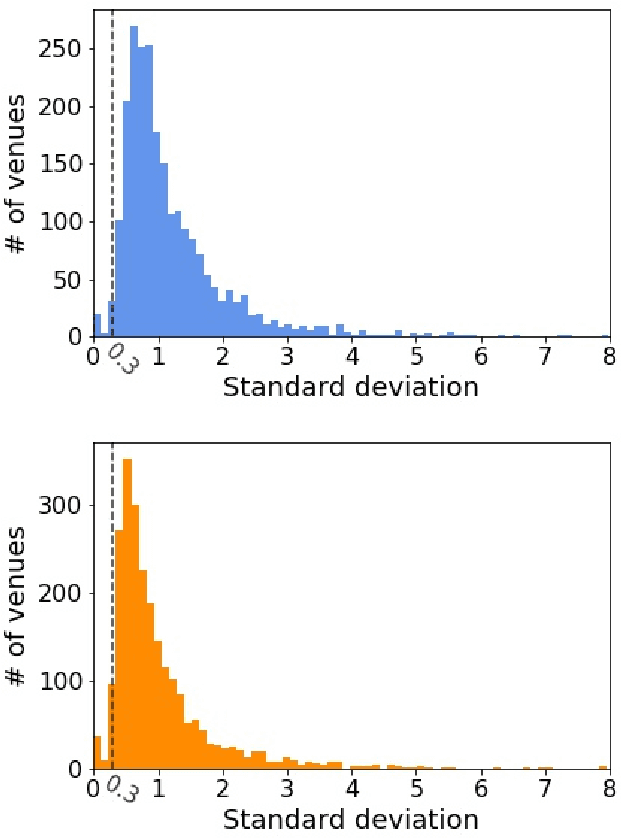
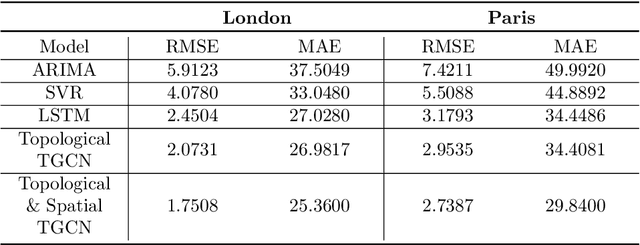
Modelling the dynamics of urban venues is a challenging task as it is multifaceted in nature. Demand is a function of many complex and nonlinear features such as neighborhood composition, real-time events, and seasonality. Recent advances in Graph Convolutional Networks (GCNs) have had promising results as they build a graphical representation of a system and harness the potential of deep learning architectures. However, there has been limited work using GCNs in a temporal setting to model dynamic dependencies of the network. Further, within the context of urban environments, there has been no prior work using dynamic GCNs to support venue demand analysis and prediction. In this paper, we propose a novel deep learning framework which aims to better model the popularity and growth of urban venues. Using a longitudinal dataset from location technology platform Foursquare, we model individual venues and venue types across London and Paris. First, representing cities as connected networks of venues, we quantify their structure and note a strong community structure in these retail networks, an observation that highlights the interplay of cooperative and competitive forces that emerge in local ecosystems of retail businesses. Next, we present our deep learning architecture which integrates both spatial and topological features into a temporal model which predicts the demand of a venue at the subsequent time-step. Our experiments demonstrate that our model can learn spatio-temporal trends of venue demand and consistently outperform baseline models. Relative to state-of-the-art deep learning models, our model reduces the RSME by ~ 28% in London and ~ 13% in Paris. Our approach highlights the power of complex network measures and GCNs in building prediction models for urban environments. The model could have numerous applications within the retail sector to better model venue demand and growth.