 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentRivet: an automated system for producing Rivet routines from journal publications
Jun 11, 2026Particle physics collider experiments provide Rivet routines as part of the analysis preservation strategy for model-independent measurements. Rivet is a C++ toolkit that allow new theoretical models to be compared to the measurements, thus aiding the development and tuning of Monte Carlo event generators as well as searches for physics beyond the Standard Model. However, analysis coverage is known to be incomplete, with only 39% of measurements having documented and publicly available Rivet routines. In this article, we design and implement an automated workflow based on Large Language Models with the goal of providing the missing routines. This multi-step workflow, referred to as AgentRivet, extracts the physics analysis information from published papers and writes the missing Rivet routines, with intermediate code- and physics- reviews as part of an autonomous quality control. We report the results obtained using commercial Large Language Models, provided by OpenAI, Anthropic, and Google, for two recent measurements from the ATLAS and CMS experiments. We find that AgentRivet produces competent Rivet routines with few syntax errors. The physics fidelity of the routines is reasonable and follows the explanations given in the relevant publications. Nevertheless, physics-implementation issues do arise and are investigated using the artefacts produced by AgentRivet. The majority of physics implementation issues arise from subtle-but-ambiguous definitions in the given publication, although some models struggle to implement complex observables even when clear definitions are given.
Knowledge is Overrated: A zero-knowledge machine learning and cryptographic hashing-based framework for verifiable, low latency inference at the LHC
Nov 16, 2025Low latency event-selection (trigger) algorithms are essential components of Large Hadron Collider (LHC) operation. Modern machine learning (ML) models have shown great offline performance as classifiers and could improve trigger performance, thereby improving downstream physics analyses. However, inference on such large models does not satisfy the $40\text{MHz}$ online latency constraint at the LHC. In this work, we propose \texttt{PHAZE}, a novel framework built on cryptographic techniques like hashing and zero-knowledge machine learning (zkML) to achieve low latency inference, via a certifiable, early-exit mechanism from an arbitrarily large baseline model. We lay the foundations for such a framework to achieve nanosecond-order latency and discuss its inherent advantages, such as built-in anomaly detection, within the scope of LHC triggers, as well as its potential to enable a dynamic low-level trigger in the future.
Strategic White Paper on AI Infrastructure for Particle, Nuclear, and Astroparticle Physics: Insights from JENA and EuCAIF
Mar 18, 2025



Artificial intelligence (AI) is transforming scientific research, with deep learning methods playing a central role in data analysis, simulations, and signal detection across particle, nuclear, and astroparticle physics. Within the JENA communities-ECFA, NuPECC, and APPEC-and as part of the EuCAIF initiative, AI integration is advancing steadily. However, broader adoption remains constrained by challenges such as limited computational resources, a lack of expertise, and difficulties in transitioning from research and development (R&D) to production. This white paper provides a strategic roadmap, informed by a community survey, to address these barriers. It outlines critical infrastructure requirements, prioritizes training initiatives, and proposes funding strategies to scale AI capabilities across fundamental physics over the next five years.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021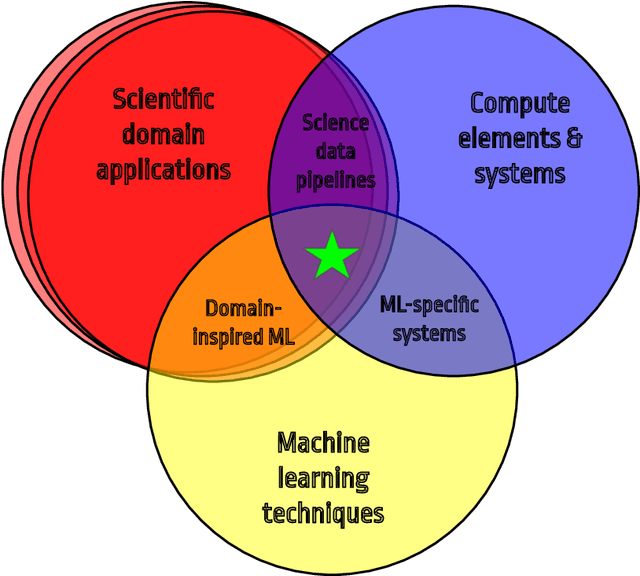
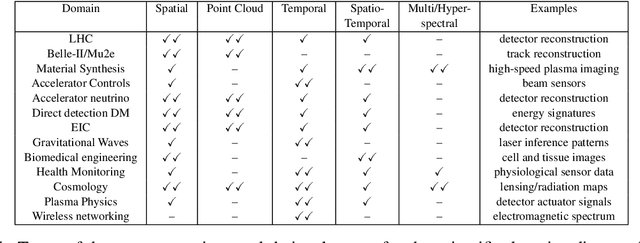
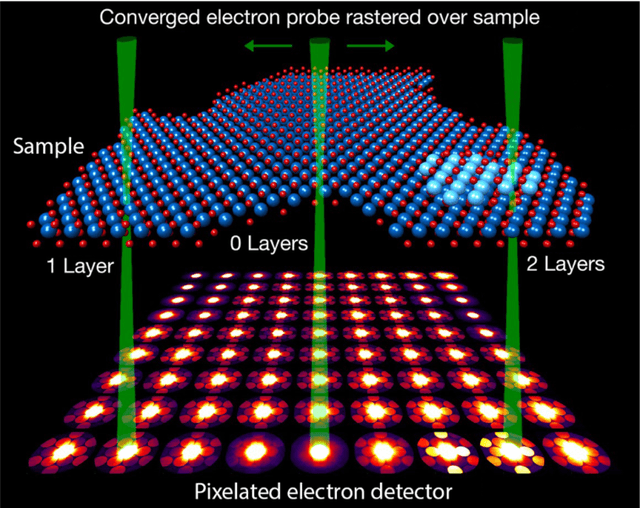
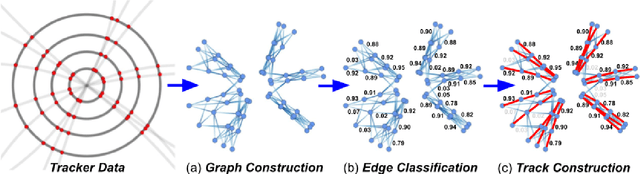
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.