 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Predictive Control for Dynamic Cloth Manipulation: Parameter Learning and Experimental Validation
Sep 20, 2022
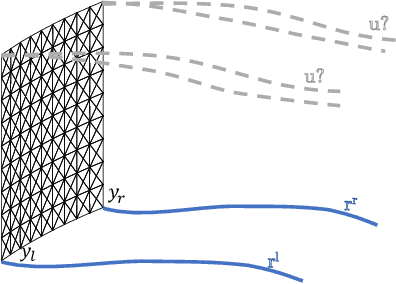
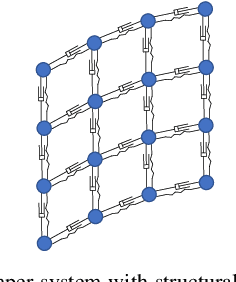
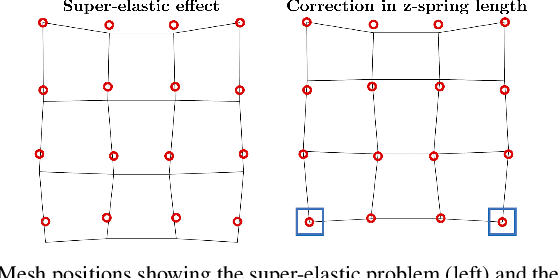
Robotic cloth manipulation is a relevant challenging problem for autonomous robotic systems. Highly deformable objects as textile items can adopt multiple configurations and shapes during their manipulation. Hence, robots should not only understand the current cloth configuration but also be able to predict the future possible behaviors of the cloth. This paper addresses the problem of indirectly controlling the configuration of certain points of a textile object, by applying actions on other parts of the object through the use of a Model Predictive Control (MPC) strategy, which also allows to foresee the behavior of indirectly controlled points. The designed controller finds the optimal control signals to attain the desired future target configuration. The explored scenario in this paper considers tracking a reference trajectory with the lower corners of a square piece of cloth by grasping its upper corners. To do so, we propose and validate a linear cloth model that allows solving the MPC-related optimization problem in real time. Reinforcement Learning (RL) techniques are used to learn the optimal parameters of the proposed cloth model and also to tune the resulting MPC. After obtaining accurate tracking results in simulation, the full control scheme was implemented and executed in a real robot, obtaining accurate tracking even in adverse conditions. While total observed errors reach the 5 cm mark, for a 30x30 cm cloth, an analysis shows the MPC contributes less than 30% to that value.
The dGLI Cloth Coordinates: A Topological Representation for Semantic Classification of Cloth States
Sep 14, 2022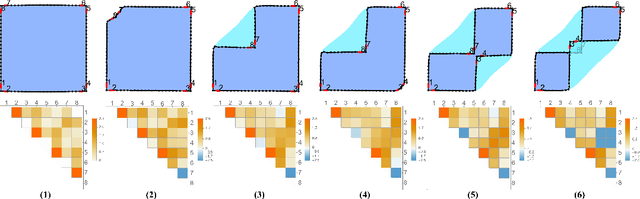
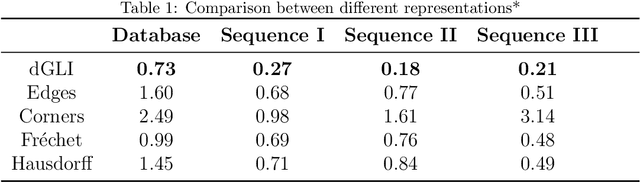

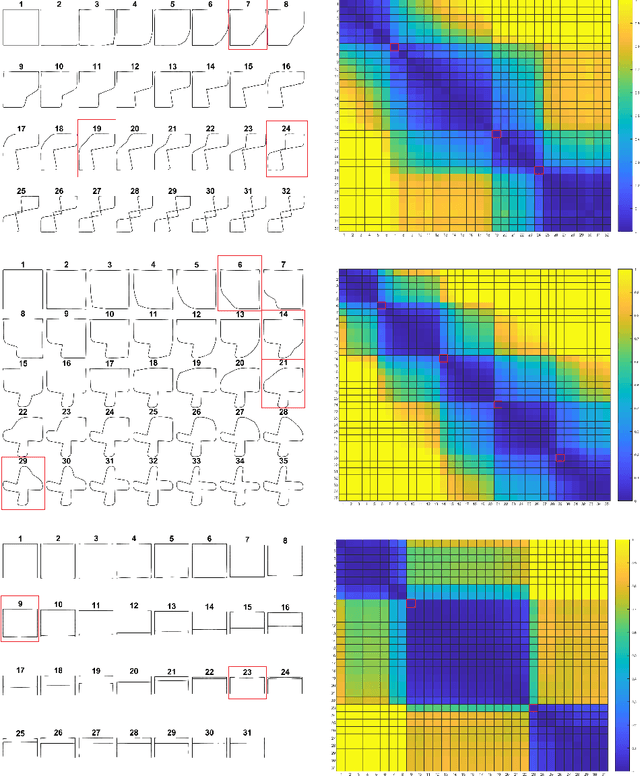
Robotic manipulation of cloth is a highly complex task because of its infinite-dimensional shape-state space that makes cloth state estimation very difficult. In this paper we introduce the dGLI Cloth Coordinates, a low-dimensional representation of the state of a rectangular piece of cloth that allows to efficiently distinguish key topological changes in a folding sequence, opening the door to efficient learning methods for cloth manipulation planning and control. Our representation is based on a directional derivative of the Gauss Linking Integral and allows us to represent both planar and spatial configurations in a consistent unified way. The proposed dGLI Cloth Coordinates are shown to be more accurate in the classification of cloth states and significantly more sensitive to changes in grasping affordances than other classic shape distance methods. Finally, we apply our representation to real images of a cloth, showing we can identify the different states using a simple distance-based classifier.
Ethics for social robotics: A critical analysis
Jul 25, 2022Social robotics development for the practice of care and European prospects to incorporate these AI-based systems in institutional healthcare contexts call for an urgent ethical reflection to (re)configurate our practical life according to human values and rights. Despite the growing attention to the ethical implications of social robotics, the current debate on one of its central branches, social assistive robotics (SAR), rests upon an impoverished ethical approach. This paper presents and examines some tendencies of this prevailing approach, which have been identified as a result of a critical literature review. Based on this analysis of a representative case of how ethical reflection is being led towards social robotics, some future research lines are outlined, which may help reframe and deepen in its ethical implications.
An Inextensible Model for Robotic Simulations of Textiles
Mar 17, 2021

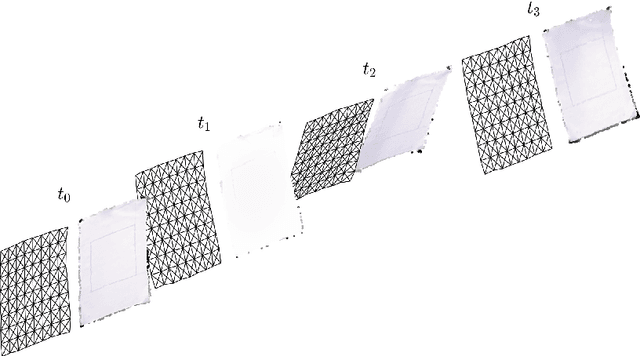

We introduce a new isometric strain model for the study of the dynamics of cloth garments in a moderate stress environment, such as robotic manipulation in the neighborhood of humans. This model treats textiles as surfaces which are inextensible, admitting only isometric motions. Inextensibility is imposed in a continuous setting, prior to any discretization, which gives consistency with respect to re-meshing and prevents the problem of locking even with coarse meshes. The simulations of robotic manipulation using the model are compared to the actual manipulation in the real world, finding that the error between the simulated and real position of each point in the garment is lower than 1cm in average, even when a coarse mesh is used. Aerodynamic contributions to motion are incorporated to the model through the virtual uncoupling of the inertial and gravitational mass of the garment. This approach results in an accurate, as compared to reality, description of cloth motion incorporating aerodynamic effects by using only two parameters.
Controlled Gaussian Process Dynamical Models with Application to Robotic Cloth Manipulation
Mar 11, 2021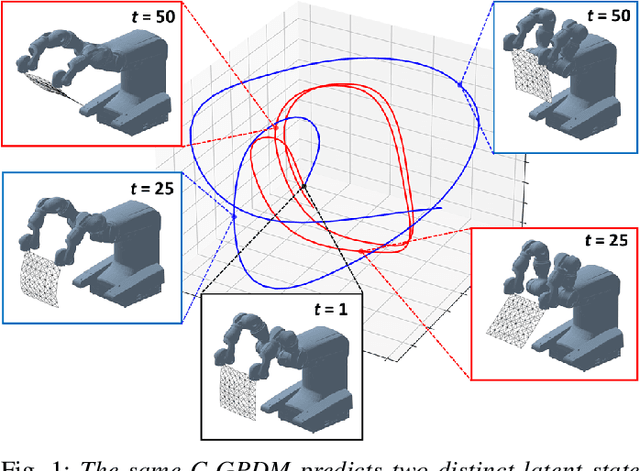
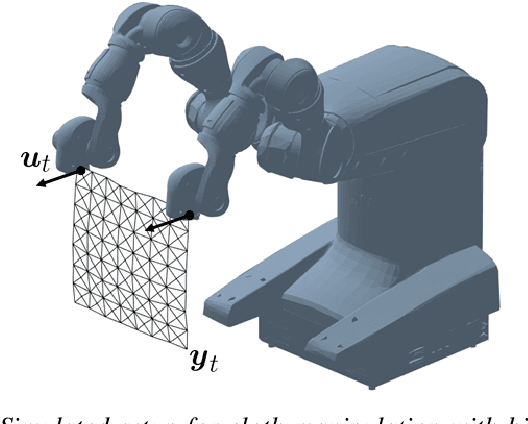
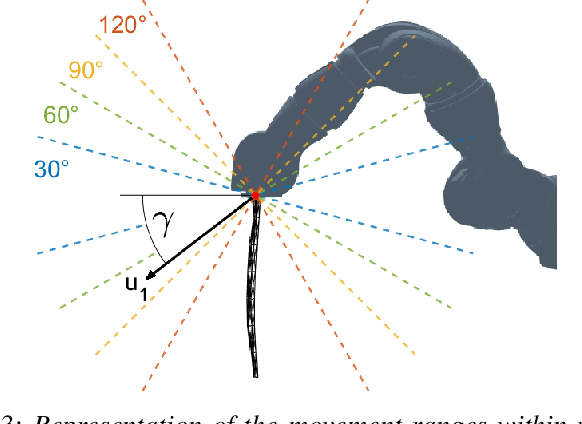
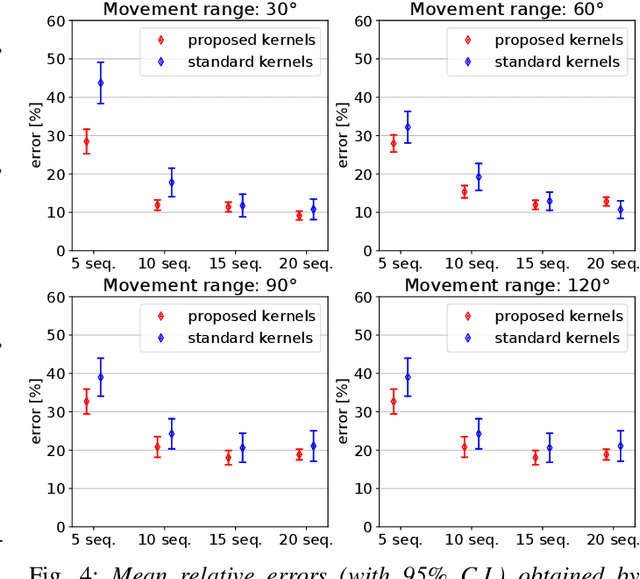
Over the last years, robotic cloth manipulation has gained relevance within the research community. While significant advances have been made in robotic manipulation of rigid objects, the manipulation of non-rigid objects such as cloth garments is still a challenging problem. The uncertainty on how cloth behaves often requires the use of model-based approaches. However, cloth models have a very high dimensionality. Therefore, it is difficult to find a middle point between providing a manipulator with a dynamics model of cloth and working with a state space of tractable dimensionality. For this reason, most cloth manipulation approaches in literature perform static or quasi-static manipulation. In this paper, we propose a variation of Gaussian Process Dynamical Models (GPDMs) to model cloth dynamics in a low-dimensional manifold. GPDMs project a high-dimensional state space into a smaller dimension latent space which is capable of keeping the dynamic properties. Using such approach, we add control variables to the original formulation. In this way, it is possible to take into account the robot commands exerted on the cloth dynamics. We call this new version Controlled Gaussian Process Dynamical Model (C-GPDM). Moreover, we propose an alternative kernel representation for the model, characterized by a richer parameterization than the one employed in the majority of previous GPDM realizations. The modeling capacity of our proposal has been tested in a simulated scenario, where C-GPDM proved to be capable of generalizing over a considerably wide range of movements and correctly predicting the cloth oscillations generated by previously unseen sequences of control actions.
Online Action Recognition
Dec 14, 2020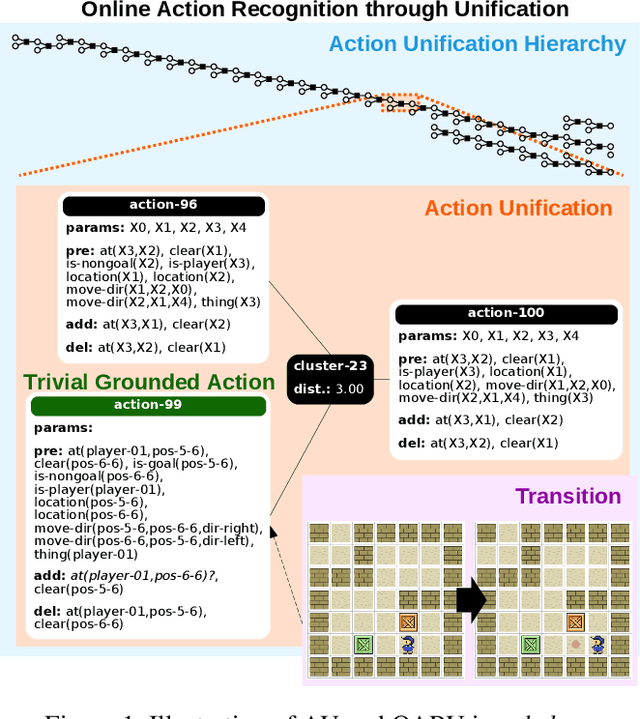
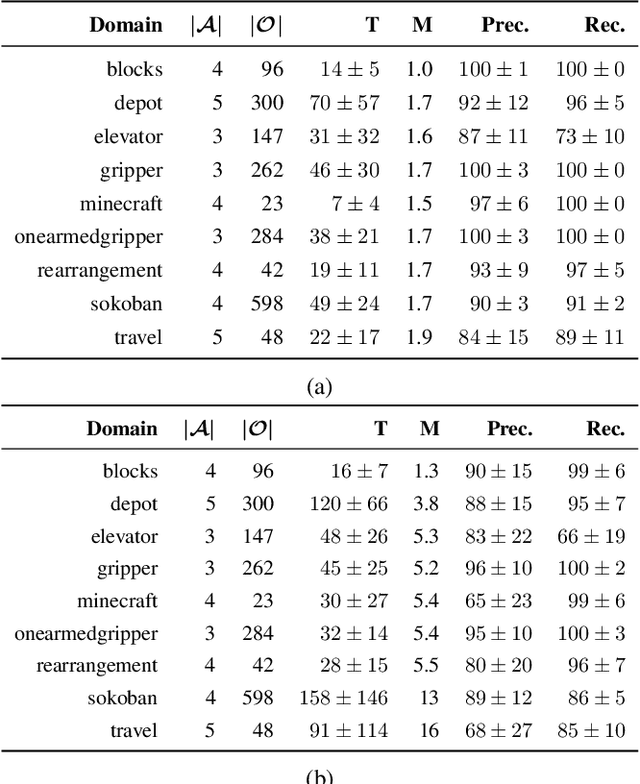
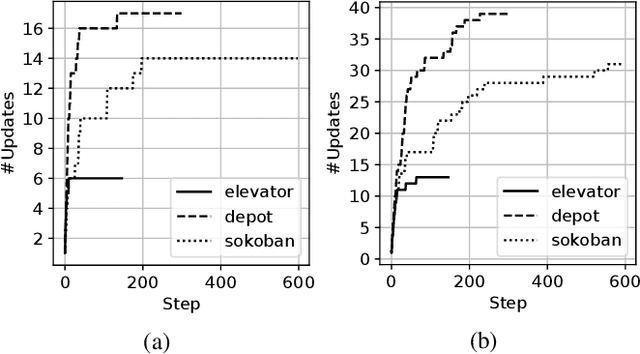
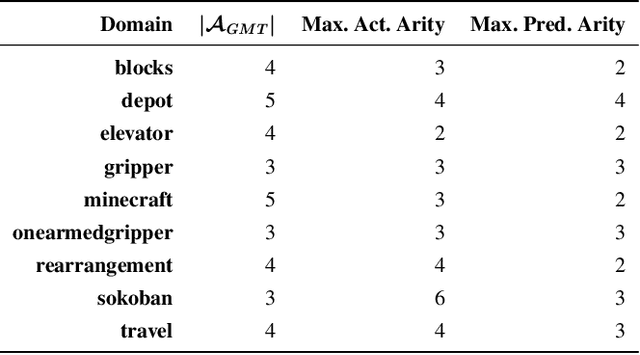
Recognition in planning seeks to find agent intentions, goals or activities given a set of observations and a knowledge library (e.g. goal states, plans or domain theories). In this work we introduce the problem of Online Action Recognition. It consists in recognizing, in an open world, the planning action that best explains a partially observable state transition from a knowledge library of first-order STRIPS actions, which is initially empty. We frame this as an optimization problem, and propose two algorithms to address it: Action Unification (AU) and Online Action Recognition through Unification (OARU). The former builds on logic unification and generalizes two input actions using weighted partial MaxSAT. The latter looks for an action within the library that explains an observed transition. If there is such action, it generalizes it making use of AU, building in this way an AU hierarchy. Otherwise, OARU inserts a Trivial Grounded Action (TGA) in the library that explains just that transition. We report results on benchmarks from the International Planning Competition and PDDLGym, where OARU recognizes actions accurately with respect to expert knowledge, and shows real-time performance.
Task-Adaptive Robot Learning from Demonstration under Replication with Gaussian Process Models
Oct 15, 2020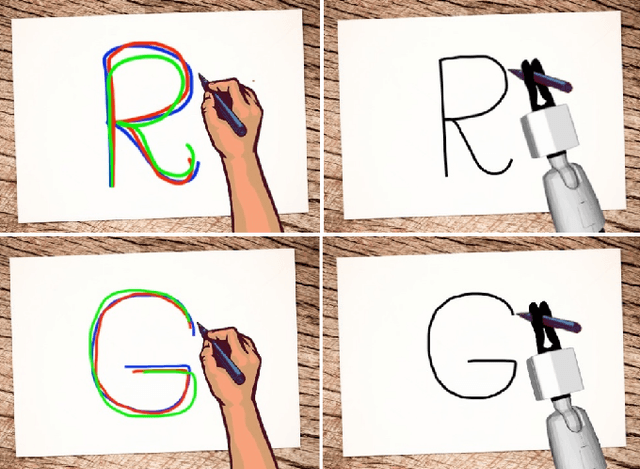
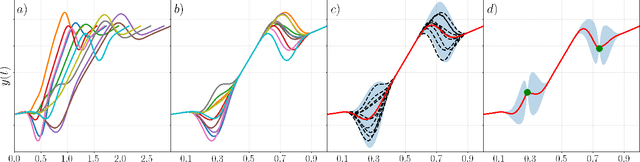
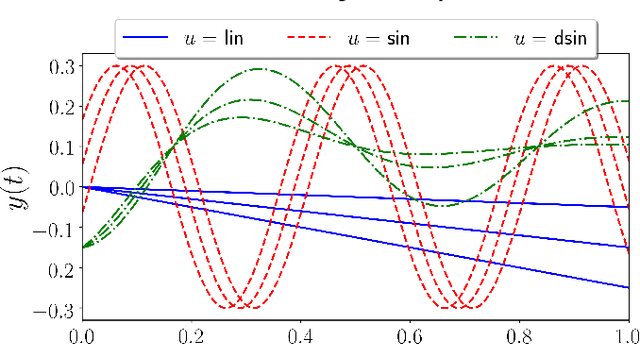
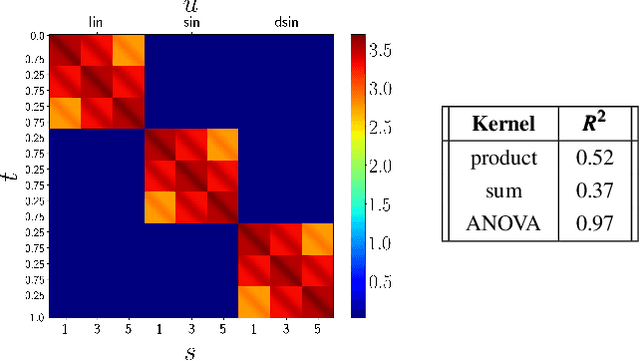
Learning from Demonstration (LfD) is a paradigm that allows robots to learn complex manipulation tasks that can not be easily scripted, but can be demonstrated by a human teacher. One of the challenges of LfD is to enable robots to acquire skills that can be adapted to different scenarios. In this paper, we propose to achieve this by exploiting the variations in the demonstrations to retrieve an adaptive and robust policy, using Gaussian Process (GP) models. Adaptability is enhanced by incorporating task parameters into the model, which encode different specifications within the same task. With our formulation, these parameters can either be real, integer, or categorical. Furthermore, we propose a GP design that exploits the structure of replications, i.e., repeated demonstrations at identical conditions within data. Our method significantly reduces the computational cost of model fitting in complex tasks, where replications are essential to obtain a robust model. We illustrate our approach through several experiments on a handwritten letter demonstration dataset.
Encoding cloth manipulations using a graph of states and transitions
Sep 30, 2020
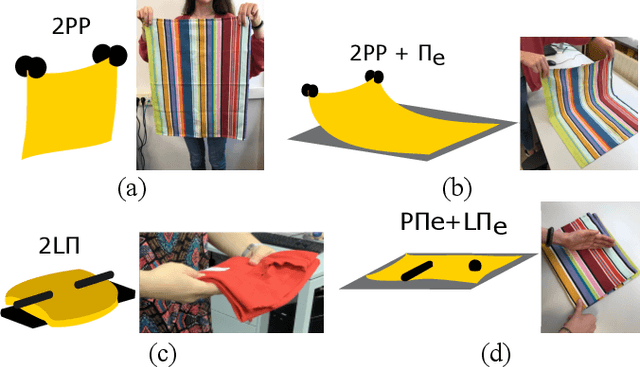
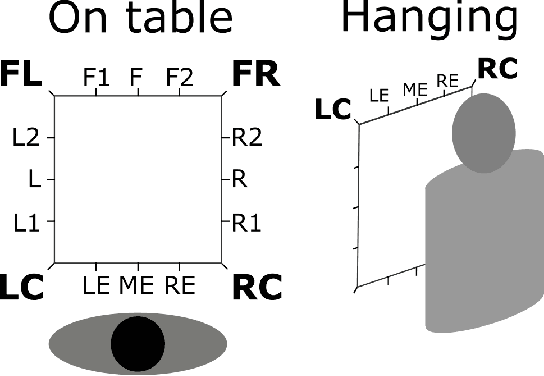

Cloth manipulation is very relevant for domestic robotic tasks, but it presents many challenges due to the complexity of representing, recognizing and predicting behaviour of cloth under manipulation. In this work, we propose a generic, compact and simplified representation of the states of cloth manipulation that allows for representing tasks as sequences of states and transitions. We also define a graph of manipulation primitives that encodes all the strategies to accomplish a task. Our novel representation is used to encode the task of folding a napkin, learned from an experiment with human subjects with video and motion data. We show how our simplified representation allows to obtain a map of meaningful motion primitives and to segment the motion data to obtain sets of trajectories, velocity and acceleration profiles corresponding to each manipulation primitive in the graph.
Leveraging Multiple Environments for Learning and Decision Making: a Dismantling Use Case
Sep 18, 2020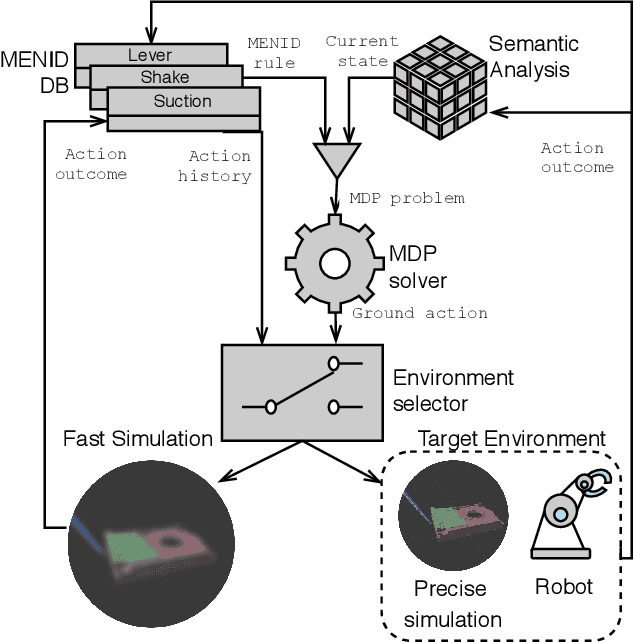
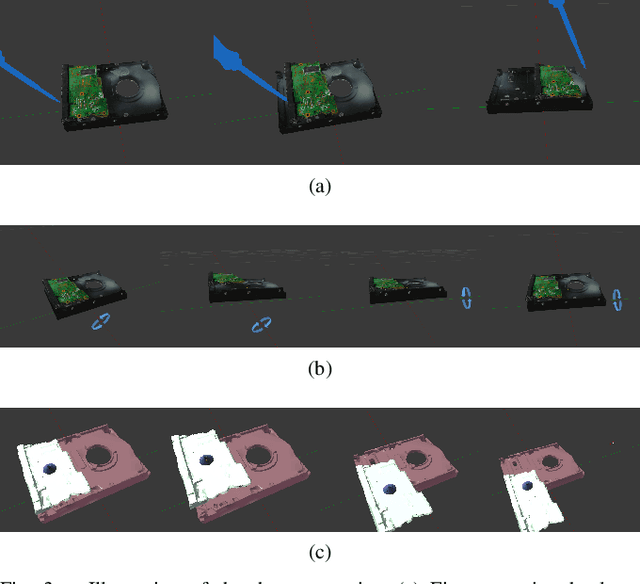
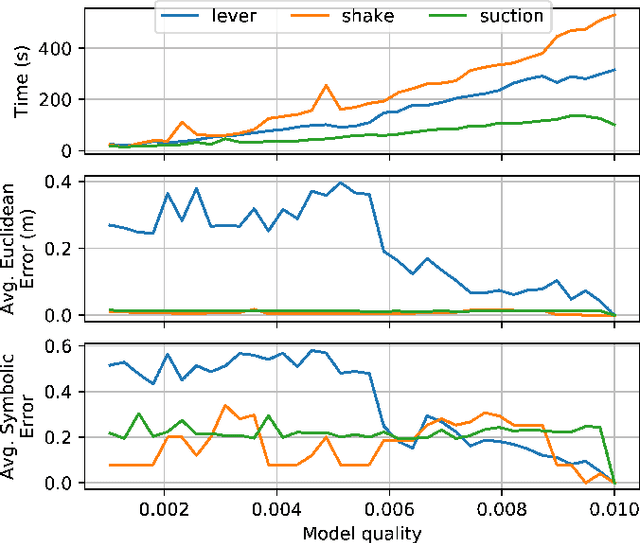
Learning is usually performed by observing real robot executions. Physics-based simulators are a good alternative for providing highly valuable information while avoiding costly and potentially destructive robot executions. We present a novel approach for learning the probabilities of symbolic robot action outcomes. This is done leveraging different environments, such as physics-based simulators, in execution time. To this end, we propose MENID (Multiple Environment Noise Indeterministic Deictic) rules, a novel representation able to cope with the inherent uncertainties present in robotic tasks. MENID rules explicitly represent each possible outcomes of an action, keep memory of the source of the experience, and maintain the probability of success of each outcome. We also introduce an algorithm to distribute actions among environments, based on previous experiences and expected gain. Before using physics-based simulations, we propose a methodology for evaluating different simulation settings and determining the least time-consuming model that could be used while still producing coherent results. We demonstrate the validity of the approach in a dismantling use case, using a simulation with reduced quality as simulated system, and a simulation with full resolution where we add noise to the trajectories and some physical parameters as a representation of the real system.
Gaussian-Process-based Robot Learning from Demonstration
Feb 23, 2020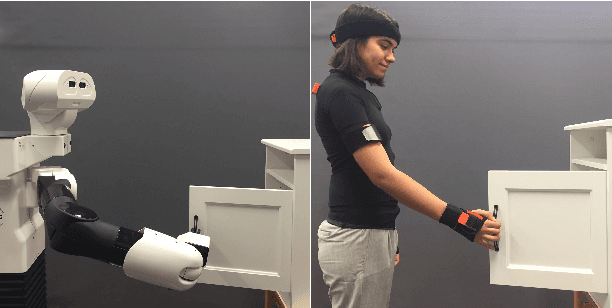

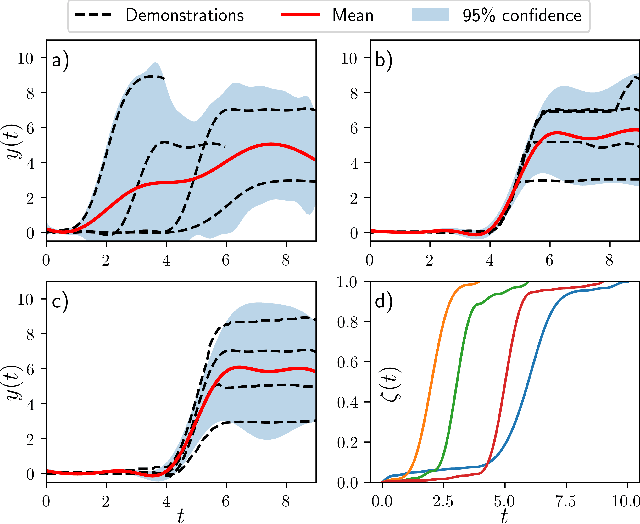
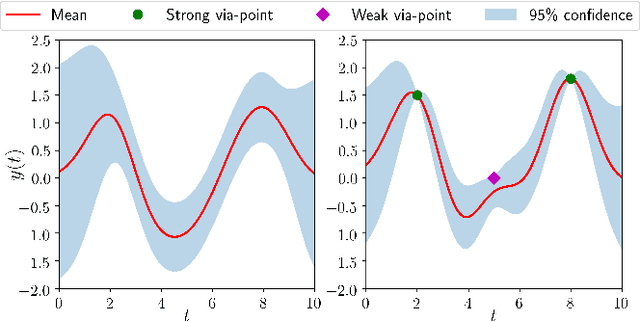
Endowed with higher levels of autonomy, robots are required to perform increasingly complex manipulation tasks. Learning from demonstration is arising as a promising paradigm for easily extending robot capabilities so that they adapt to unseen scenarios. We present a novel Gaussian-Process-based approach for learning manipulation skills from observations of a human teacher. This probabilistic representation allows to generalize over multiple demonstrations, and encode uncertainty variability along the different phases of the task. In this paper, we address how Gaussian Processes can be used to effectively learn a policy from trajectories in task space. We also present a method to efficiently adapt the policy to fulfill new requirements, and to modulate the robot behavior as a function of task uncertainty. This approach is illustrated through a real-world application using the TIAGo robot.