 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Deep Gaussian Processes
Oct 16, 2018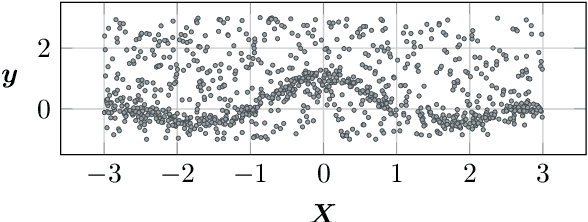
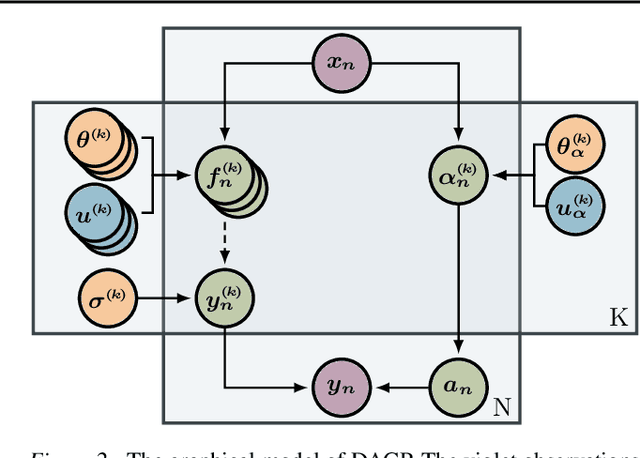
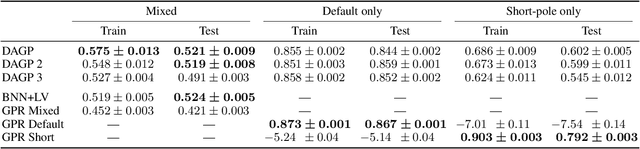
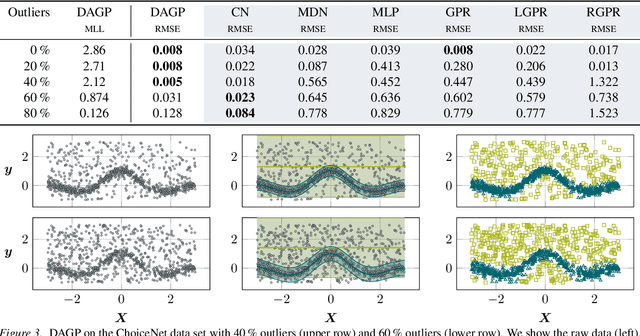
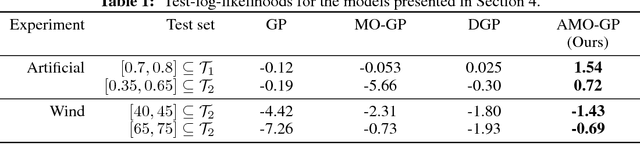
We propose a novel Bayesian approach to modelling multimodal data generated by multiple independent processes, simultaneously solving the data association and induced supervised learning problems. Underpinning our approach is the use of Gaussian process priors which encode structure both on the functions and the associations themselves. The association of samples and functions are determined by taking both inputs and outputs into account while also obtaining a posterior belief about the relevance of the global components throughout the input space. We present an efficient learning scheme based on doubly stochastic variational inference and discuss how it can be applied to deep Gaussian process priors. We show results for an artificial data set, a noise separation problem, and a multimodal regression problem based on the cart-pole benchmark.
DP-GP-LVM: A Bayesian Non-Parametric Model for Learning Multivariate Dependency Structures
Jul 12, 2018

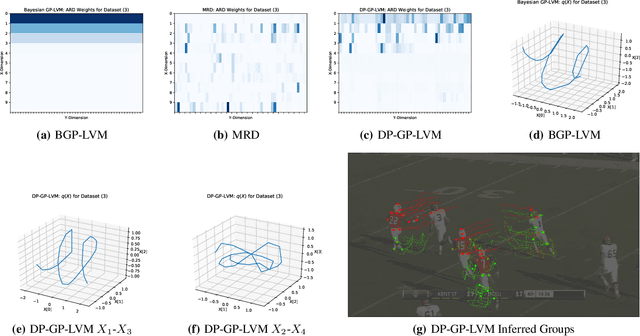
We present a non-parametric Bayesian latent variable model capable of learning dependency structures across dimensions in a multivariate setting. Our approach is based on flexible Gaussian process priors for the generative mappings and interchangeable Dirichlet process priors to learn the structure. The introduction of the Dirichlet process as a specific structural prior allows our model to circumvent issues associated with previous Gaussian process latent variable models. Inference is performed by deriving an efficient variational bound on the marginal log-likelihood on the model.
Gaussian Process Latent Variable Alignment Learning
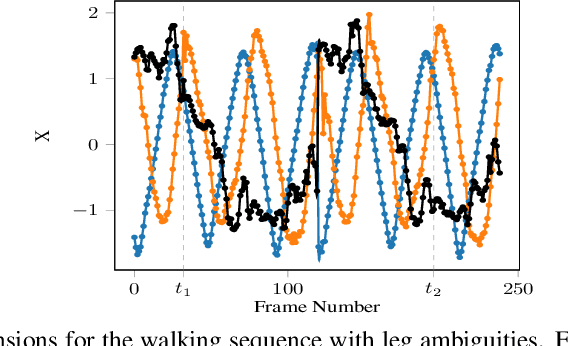
Jul 05, 2018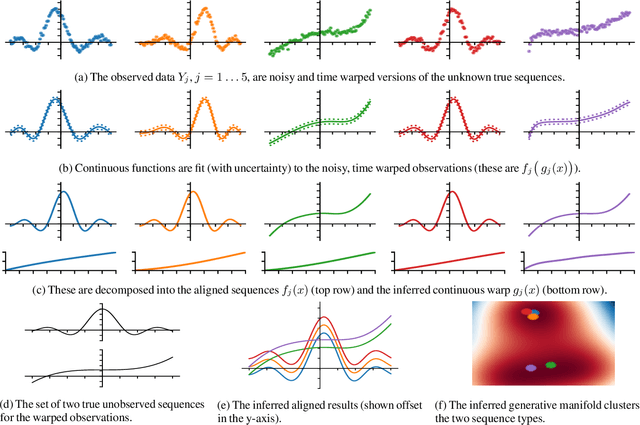

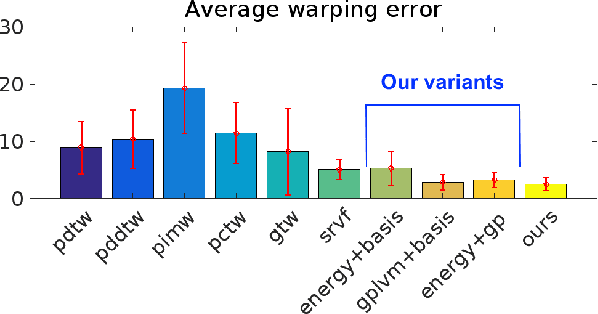
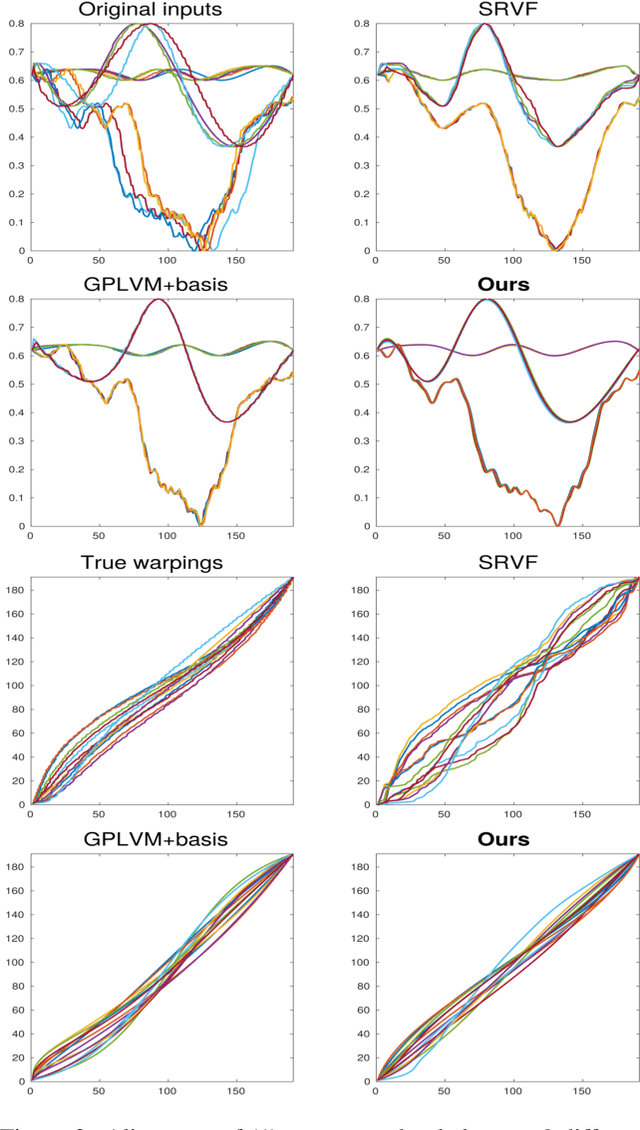
We present a model that can automatically learn alignments between high-dimensional data in an unsupervised manner. Our proposed method casts alignment learning in a framework where both alignment and data are modelled simultaneously. Further, we automatically infer groupings of different types of sequence within the same dataset. We derive a probabilistic model built on non-parametric priors that allows for flexible warps while at the same time providing means to specify interpretable constraints. We demonstrate the efficacy of our approach with superior quantitative performance to the state-of-the-art approaches and provide examples to illustrate the versatility of our model in automatic inference of sequence groupings, absent from previous approaches, as well as easy specification of high level priors for different modalities of data.
Bayesian Alignments of Warped Multi-Output Gaussian Processes
May 23, 2018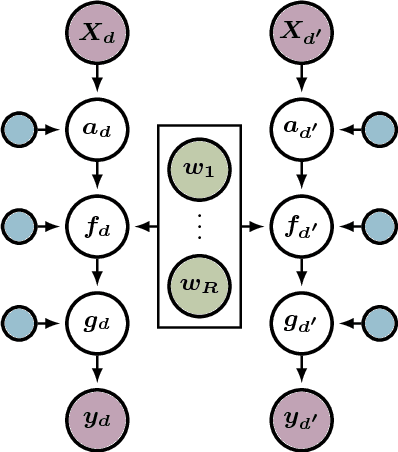
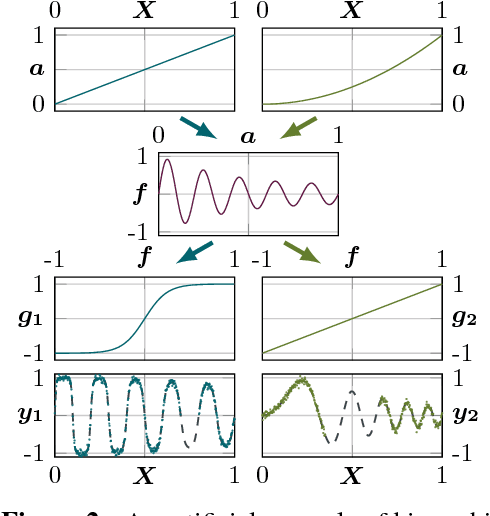
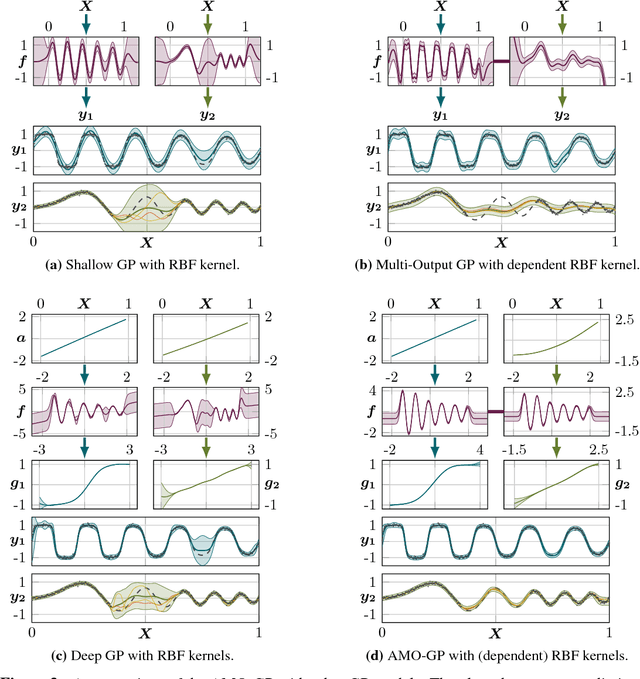
We propose a novel Bayesian approach to modelling nonlinear alignments of time series based on latent shared information. We apply the method to the real-world problem of finding common structure in the sensor data of wind turbines introduced by the underlying latent and turbulent wind field. The proposed model allows for both arbitrary alignments of the inputs and non-parametric output warpings to transform the observations. This gives rise to multiple deep Gaussian process models connected via latent generating processes. We present an efficient variational approximation based on nested variational compression and show how the model can be used to extract shared information between dependent time series, recovering an interpretable functional decomposition of the learning problem. We show results for an artificial data set and real-world data of two wind turbines.
Model Inference with Stein Density Ratio Estimation
May 18, 2018
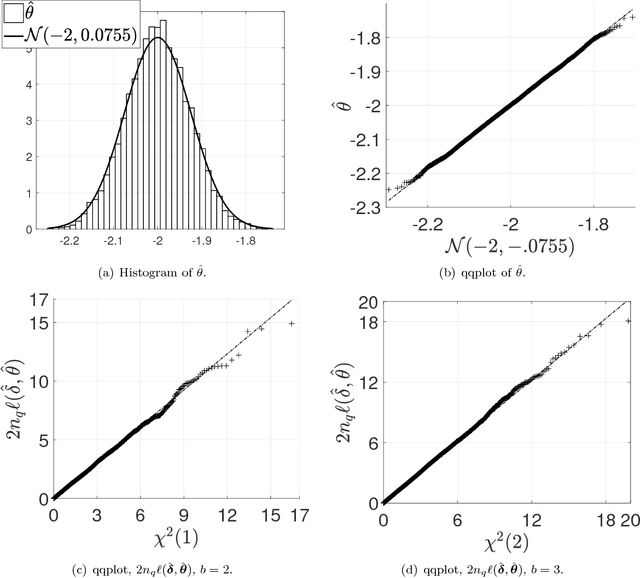
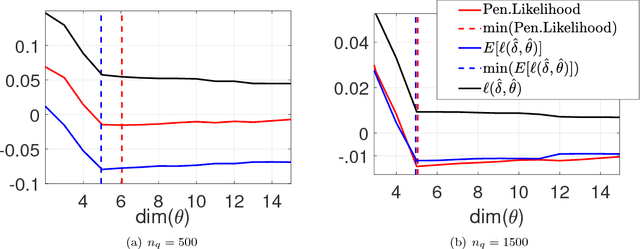
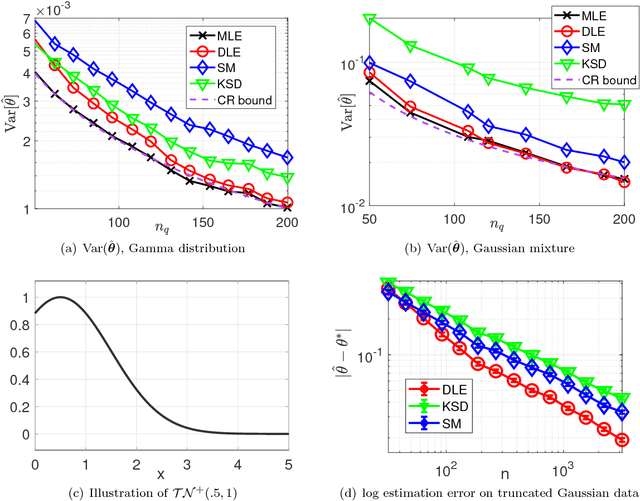
The Kullback-Leilber divergence from model to data is a classic goodness of fit measure but can be intractable in many cases. In this paper, we estimate the ratio function between a data density and a model density with the help of Stein operator. The estimated density ratio allows us to compute the likelihood ratio function which is a surrogate to the actual Kullback-Leibler divergence from model to data. By minimizing this surrogate, we can perform model fitting and inference from either frequentist or Bayesian point of view. This paper discusses methods, theories and algorithms for performing such tasks. Our theoretical claims are verified by experiments and examples are given demonstrating the usefulness of our methods.
Active Exploration Using Gaussian Random Fields and Gaussian Process Implicit Surfaces
Feb 13, 2018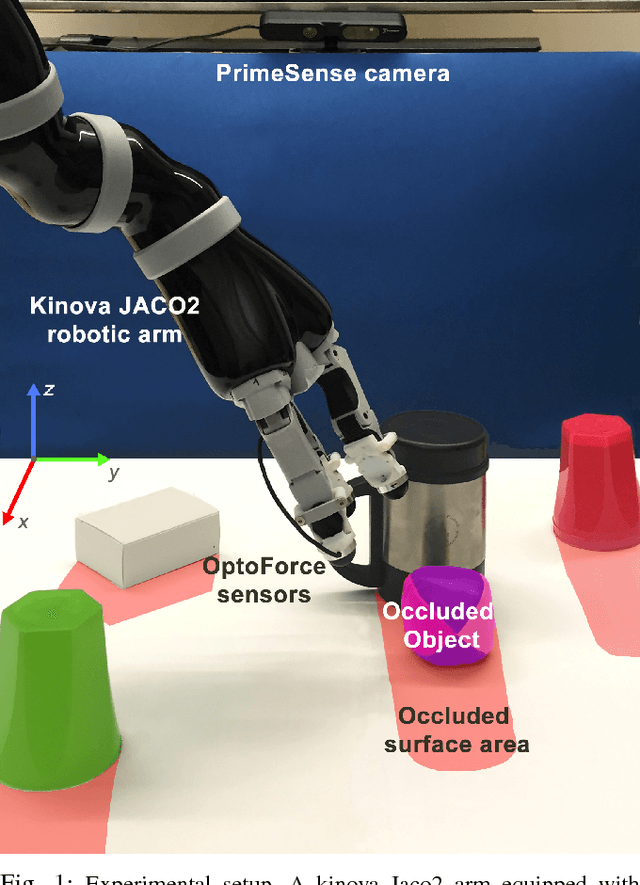
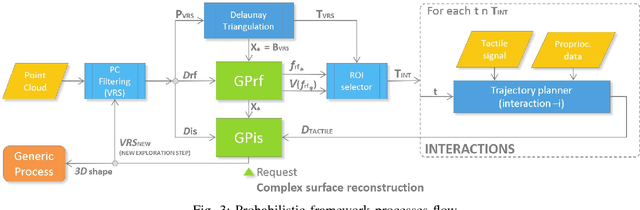
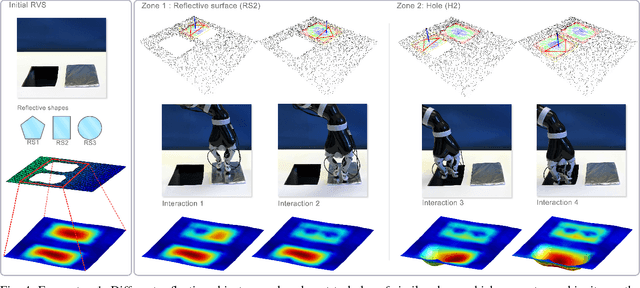
In this work we study the problem of exploring surfaces and building compact 3D representations of the environment surrounding a robot through active perception. We propose an online probabilistic framework that merges visual and tactile measurements using Gaussian Random Field and Gaussian Process Implicit Surfaces. The system investigates incomplete point clouds in order to find a small set of regions of interest which are then physically explored with a robotic arm equipped with tactile sensors. We show experimental results obtained using a PrimeSense camera, a Kinova Jaco2 robotic arm and Optoforce sensors on different scenarios. We then demonstrate how to use the online framework for object detection and terrain classification.
* 8 pages, 6 figures, external contents (https://youtu.be/0-UlFRQT0JI)
Nonparametric Inference for Auto-Encoding Variational Bayes
Dec 18, 2017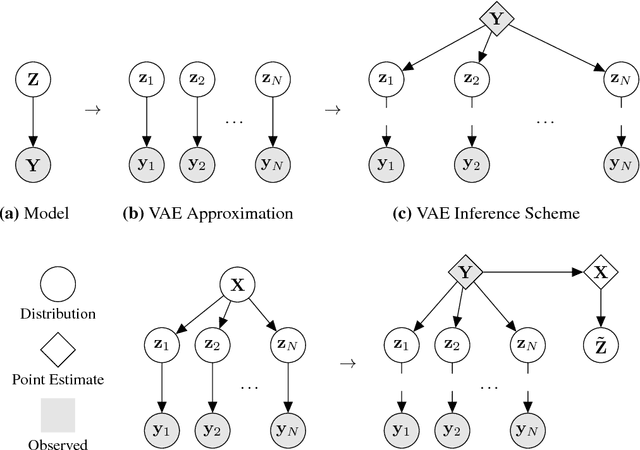
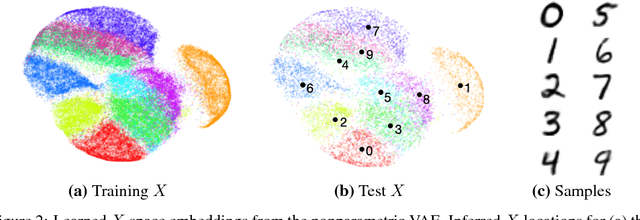
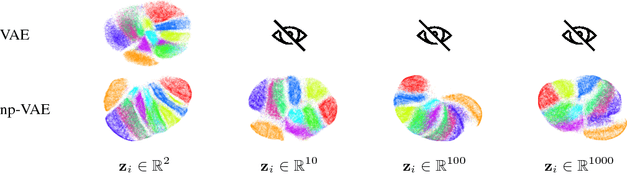

We would like to learn latent representations that are low-dimensional and highly interpretable. A model that has these characteristics is the Gaussian Process Latent Variable Model. The benefits and negative of the GP-LVM are complementary to the Variational Autoencoder, the former provides interpretable low-dimensional latent representations while the latter is able to handle large amounts of data and can use non-Gaussian likelihoods. Our inspiration for this paper is to marry these two approaches and reap the benefits of both. In order to do so we will introduce a novel approximate inference scheme inspired by the GP-LVM and the VAE. We show experimentally that the approximation allows the capacity of the generative bottle-neck (Z) of the VAE to be arbitrarily large without losing a highly interpretable representation, allowing reconstruction quality to be unlimited by Z at the same time as a low-dimensional space can be used to perform ancestral sampling from as well as a means to reason about the embedded data.
Latent Gaussian Process Regression
Sep 16, 2017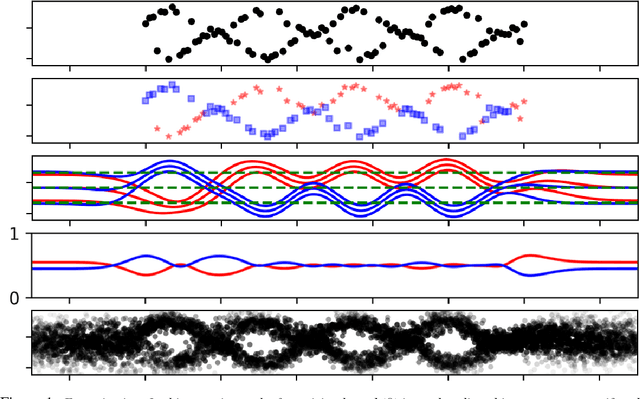
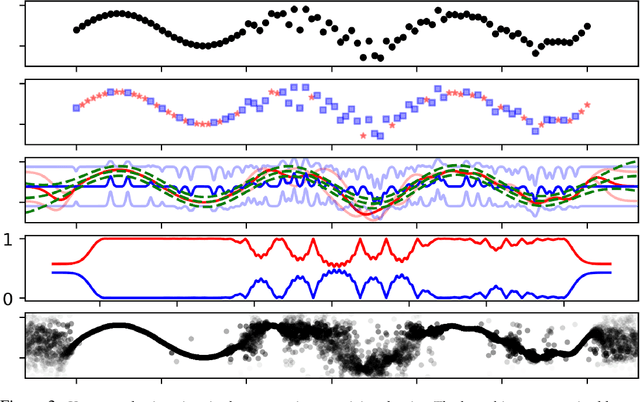
We introduce Latent Gaussian Process Regression which is a latent variable extension allowing modelling of non-stationary multi-modal processes using GPs. The approach is built on extending the input space of a regression problem with a latent variable that is used to modulate the covariance function over the training data. We show how our approach can be used to model multi-modal and non-stationary processes. We exemplify the approach on a set of synthetic data and provide results on real data from motion capture and geostatistics.
Neural Translation of Musical Style
Aug 11, 2017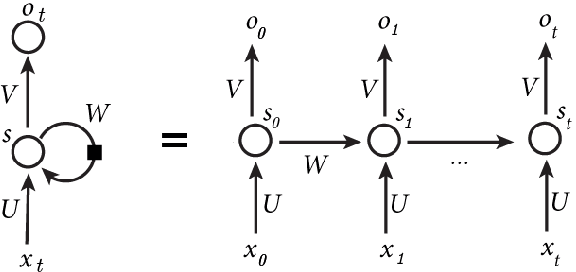
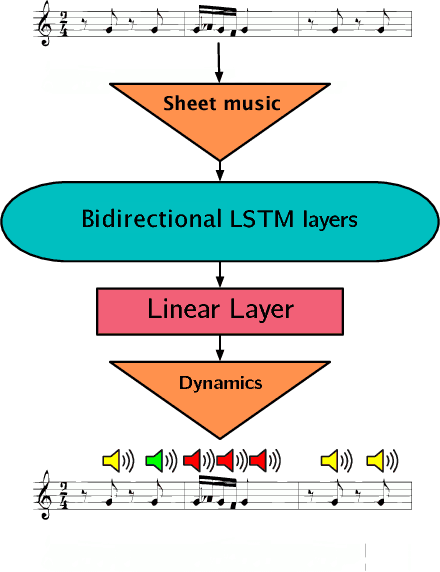
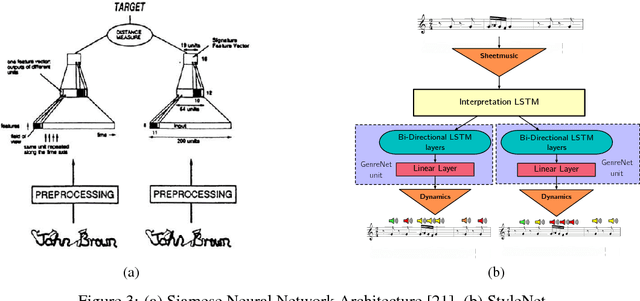
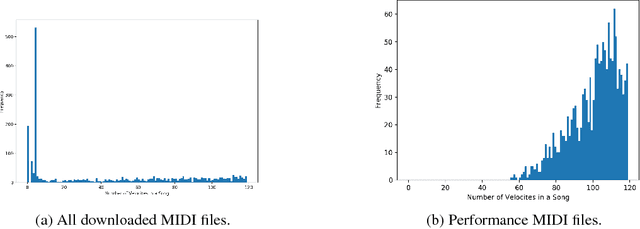
Music is an expressive form of communication often used to convey emotion in scenarios where "words are not enough". Part of this information lies in the musical composition where well-defined language exists. However, a significant amount of information is added during a performance as the musician interprets the composition. The performer injects expressiveness into the written score through variations of different musical properties such as dynamics and tempo. In this paper, we describe a model that can learn to perform sheet music. Our research concludes that the generated performances are indistinguishable from a human performance, thereby passing a test in the spirit of a "musical Turing test".
Manifold Alignment Determination: finding correspondences across different data views
Jan 12, 2017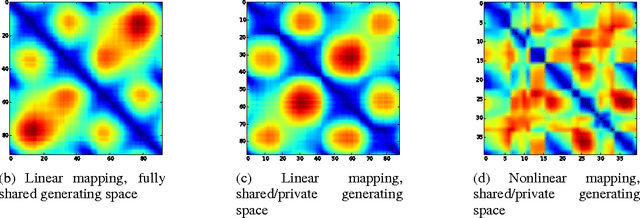
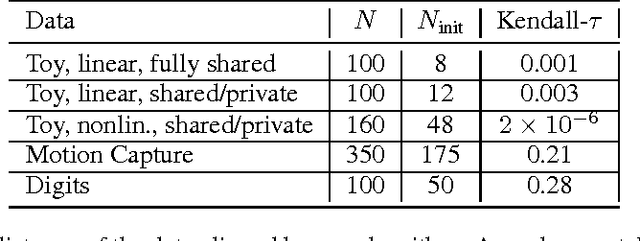
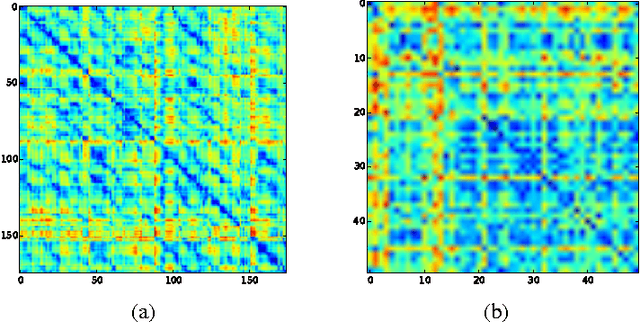

We present Manifold Alignment Determination (MAD), an algorithm for learning alignments between data points from multiple views or modalities. The approach is capable of learning correspondences between views as well as correspondences between individual data-points. The proposed method requires only a few aligned examples from which it is capable to recover a global alignment through a probabilistic model. The strong, yet flexible regularization provided by the generative model is sufficient to align the views. We provide experiments on both synthetic and real data to highlight the benefit of the proposed approach.