 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing RAG Rerankers with LLM Feedback via Reinforcement Learning
Apr 02, 2026Rerankers play a pivotal role in refining retrieval results for Retrieval-Augmented Generation. However, current reranking models are typically optimized on static human annotated relevance labels in isolation, decoupled from the downstream generation process. This isolation leads to a fundamental misalignment: documents identified as topically relevant by information retrieval metrics often fail to provide the actual utility required by the LLM for precise answer generation. To bridge this gap, we introduce ReRanking Preference Optimization (RRPO), a reinforcement learning framework that directly aligns reranking with the LLM's generation quality. By formulating reranking as a sequential decision-making process, RRPO optimizes for context utility using LLM feedback, thereby eliminating the need for expensive human annotations. To ensure training stability, we further introduce a reference-anchored deterministic baseline. Extensive experiments on knowledge-intensive benchmarks demonstrate that RRPO significantly outperforms strong baselines, including the powerful list-wise reranker RankZephyr. Further analysis highlights the versatility of our framework: it generalizes seamlessly to diverse readers (e.g., GPT-4o), integrates orthogonally with query expansion modules like Query2Doc, and remains robust even when trained with noisy supervisors.
Semi-Supervised Graph Embedding for Multi-Label Graph Node Classification
Jul 12, 2019

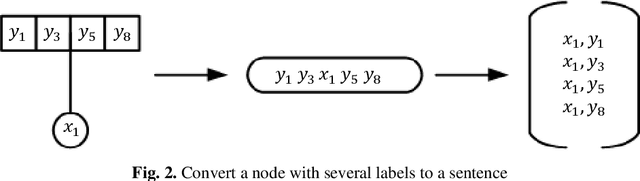

The graph convolution network (GCN) is a widely-used facility to realize graph-based semi-supervised learning, which usually integrates node features and graph topologic information to build learning models. However, as for multi-label learning tasks, the supervision part of GCN simply minimizes the cross-entropy loss between the last layer outputs and the ground-truth label distribution, which tends to lose some useful information such as label correlations, so that prevents from obtaining high performance. In this paper, we pro-pose a novel GCN-based semi-supervised learning approach for multi-label classification, namely ML-GCN. ML-GCN first uses a GCN to embed the node features and graph topologic information. Then, it randomly generates a label matrix, where each row (i.e., label vector) represents a kind of labels. The dimension of the label vector is the same as that of the node vector before the last convolution operation of GCN. That is, all labels and nodes are embedded in a uniform vector space. Finally, during the ML-GCN model training, label vectors and node vectors are concatenated to serve as the inputs of the relaxed skip-gram model to detect the node-label correlation as well as the label-label correlation. Experimental results on several graph classification datasets show that the proposed ML-GCN outperforms four state-of-the-art methods.