 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Learned Optimizers with Randomly Initialized Learned Optimizers
Jan 14, 2021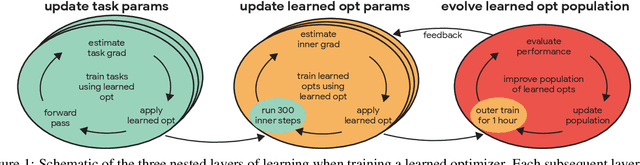
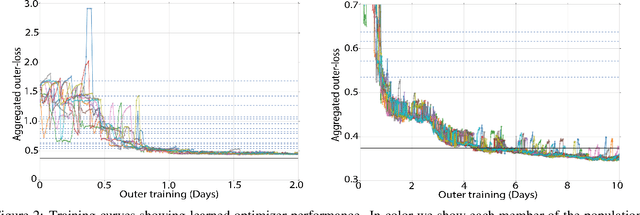
Learned optimizers are increasingly effective, with performance exceeding that of hand designed optimizers such as Adam~\citep{kingma2014adam} on specific tasks \citep{metz2019understanding}. Despite the potential gains available, in current work the meta-training (or `outer-training') of the learned optimizer is performed by a hand-designed optimizer, or by an optimizer trained by a hand-designed optimizer \citep{metz2020tasks}. We show that a population of randomly initialized learned optimizers can be used to train themselves from scratch in an online fashion, without resorting to a hand designed optimizer in any part of the process. A form of population based training is used to orchestrate this self-training. Although the randomly initialized optimizers initially make slow progress, as they improve they experience a positive feedback loop, and become rapidly more effective at training themselves. We believe feedback loops of this type, where an optimizer improves itself, will be important and powerful in the future of machine learning. These methods not only provide a path towards increased performance, but more importantly relieve research and engineering effort.
Tasks, stability, architecture, and compute: Training more effective learned optimizers, and using them to train themselves
Sep 23, 2020
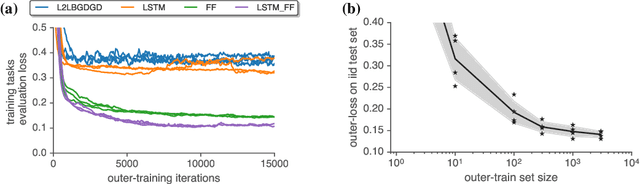
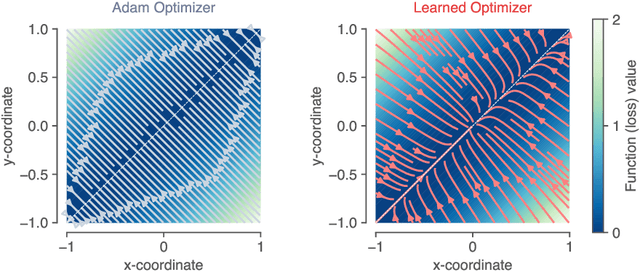
Much as replacing hand-designed features with learned functions has revolutionized how we solve perceptual tasks, we believe learned algorithms will transform how we train models. In this work we focus on general-purpose learned optimizers capable of training a wide variety of problems with no user-specified hyperparameters. We introduce a new, neural network parameterized, hierarchical optimizer with access to additional features such as validation loss to enable automatic regularization. Most learned optimizers have been trained on only a single task, or a small number of tasks. We train our optimizers on thousands of tasks, making use of orders of magnitude more compute, resulting in optimizers that generalize better to unseen tasks. The learned optimizers not only perform well, but learn behaviors that are distinct from existing first order optimizers. For instance, they generate update steps that have implicit regularization and adapt as the problem hyperparameters (e.g. batch size) or architecture (e.g. neural network width) change. Finally, these learned optimizers show evidence of being useful for out of distribution tasks such as training themselves from scratch.
Using a thousand optimization tasks to learn hyperparameter search strategies
Mar 11, 2020
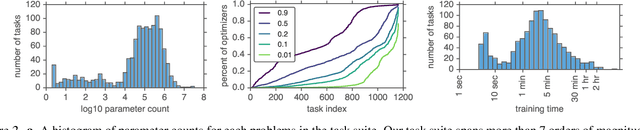
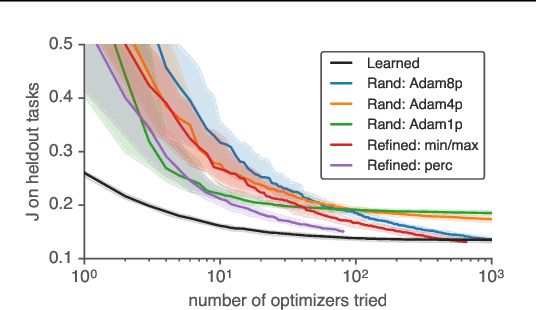
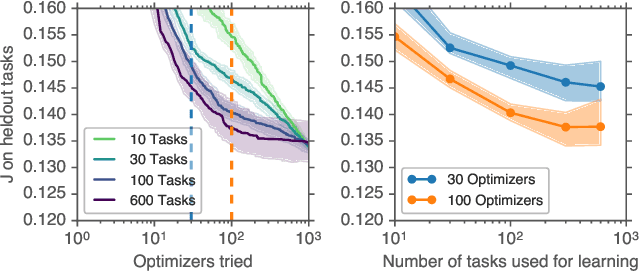
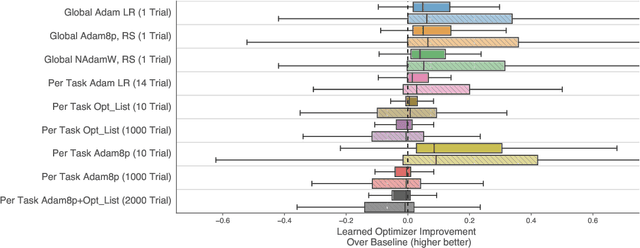
We present TaskSet, a dataset of tasks for use in training and evaluating optimizers. TaskSet is unique in its size and diversity, containing over a thousand tasks ranging from image classification with fully connected or convolutional neural networks, to variational autoencoders, to non-volume preserving flows on a variety of datasets. As an example application of such a dataset we explore meta-learning an ordered list of hyperparameters to try sequentially. By learning this hyperparameter list from data generated using TaskSet we achieve large speedups in sample efficiency over random search. Next we use the diversity of the TaskSet and our method for learning hyperparameter lists to empirically explore the generalization of these lists to new optimization tasks in a variety of settings including ImageNet classification with Resnet50 and LM1B language modeling with transformers. As part of this work we have opensourced code for all tasks, as well as ~29 million training curves for these problems and the corresponding hyperparameters.
Learning to Predict Without Looking Ahead: World Models Without Forward Prediction
Oct 31, 2019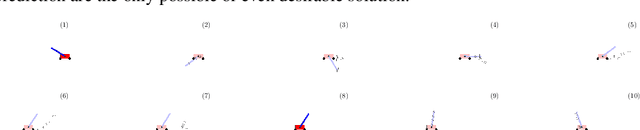
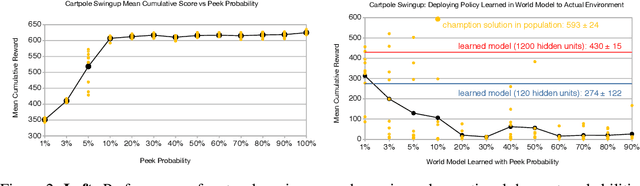

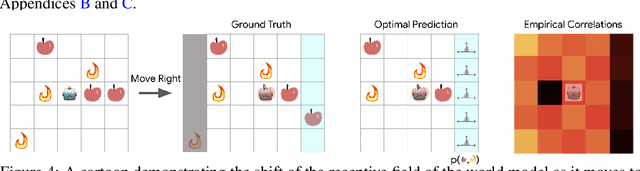
Much of model-based reinforcement learning involves learning a model of an agent's world, and training an agent to leverage this model to perform a task more efficiently. While these models are demonstrably useful for agents, every naturally occurring model of the world of which we are aware---e.g., a brain---arose as the byproduct of competing evolutionary pressures for survival, not minimization of a supervised forward-predictive loss via gradient descent. That useful models can arise out of the messy and slow optimization process of evolution suggests that forward-predictive modeling can arise as a side-effect of optimization under the right circumstances. Crucially, this optimization process need not explicitly be a forward-predictive loss. In this work, we introduce a modification to traditional reinforcement learning which we call observational dropout, whereby we limit the agents ability to observe the real environment at each timestep. In doing so, we can coerce an agent into learning a world model to fill in the observation gaps during reinforcement learning. We show that the emerged world model, while not explicitly trained to predict the future, can help the agent learn key skills required to perform well in its environment. Videos of our results available at https://learningtopredict.github.io/
Learned optimizers that outperform SGD on wall-clock and test loss
Oct 26, 2018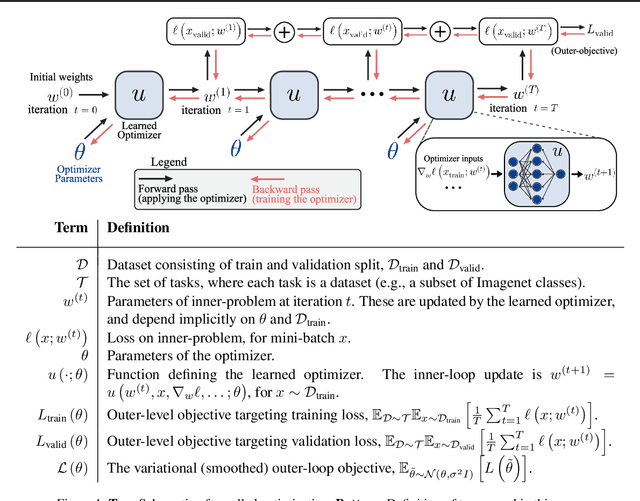
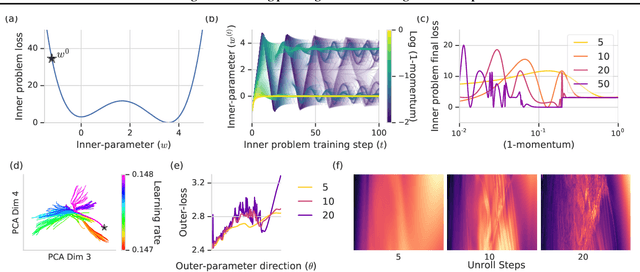
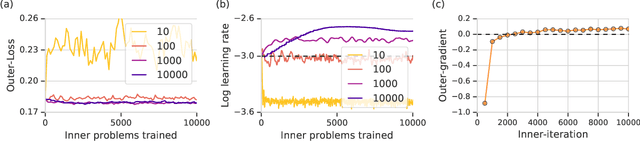
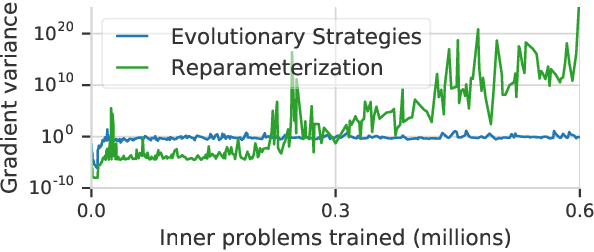
Deep learning has shown that learned functions can dramatically outperform hand-designed functions on perceptual tasks. Analogously, this suggests that learned optimizers may similarly outperform current hand-designed optimizers, especially for specific problems. However, learned optimizers are notoriously difficult to train and have yet to demonstrate wall-clock speedups over hand-designed optimizers, and thus are rarely used in practice. Typically, learned optimizers are trained by truncated backpropagation through an unrolled optimization process. The resulting gradients are either strongly biased (for short truncations) or have exploding norm (for long truncations). In this work we propose a training scheme which overcomes both of these difficulties, by dynamically weighting two unbiased gradient estimators for a variational loss on optimizer performance. This allows us to train neural networks to perform optimization of a specific task faster than well tuned first-order methods. Moreover, by training the optimizer against validation loss (as opposed to training loss), we are able to learn optimizers that train networks to better generalization than first order methods. We demonstrate these results on problems where our learned optimizer trains convolutional networks in a fifth of the wall-clock time compared to tuned first-order methods, and with an improvement in test loss.
Topology and Geometry of Half-Rectified Network Optimization
Jun 01, 2017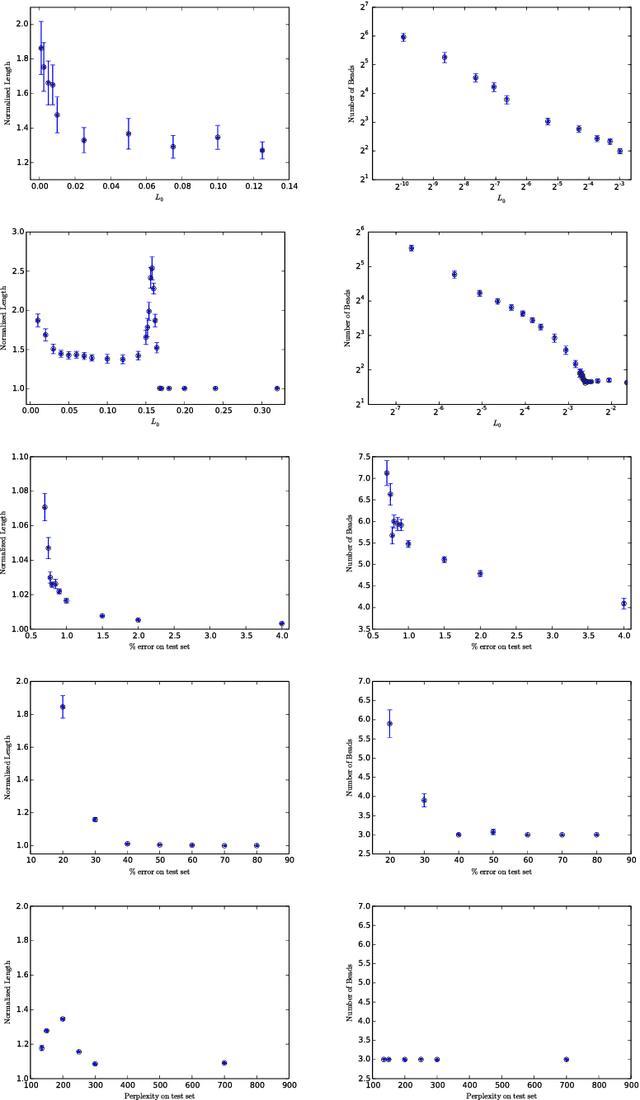
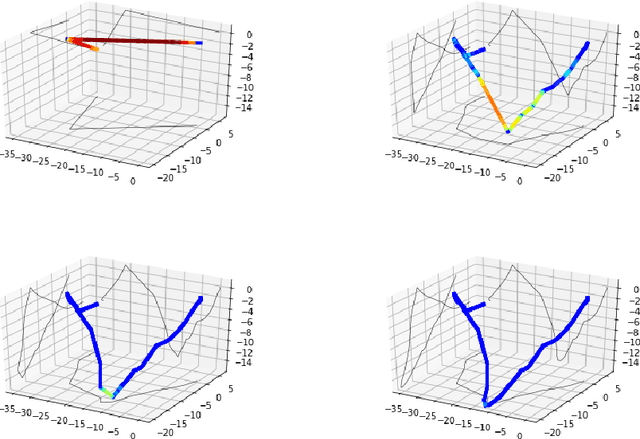
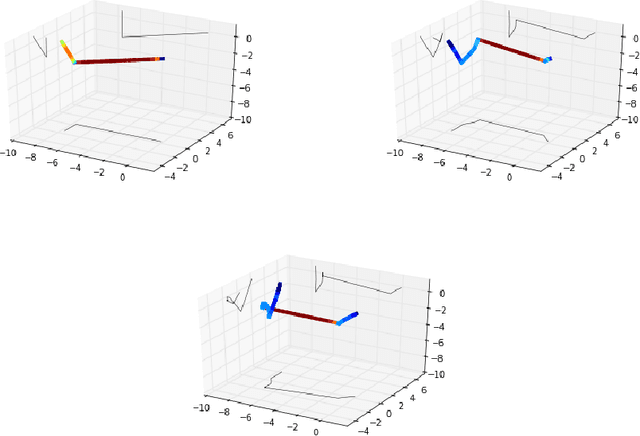
The loss surface of deep neural networks has recently attracted interest in the optimization and machine learning communities as a prime example of high-dimensional non-convex problem. Some insights were recently gained using spin glass models and mean-field approximations, but at the expense of strongly simplifying the nonlinear nature of the model. In this work, we do not make any such assumption and study conditions on the data distribution and model architecture that prevent the existence of bad local minima. Our theoretical work quantifies and formalizes two important \emph{folklore} facts: (i) the landscape of deep linear networks has a radically different topology from that of deep half-rectified ones, and (ii) that the energy landscape in the non-linear case is fundamentally controlled by the interplay between the smoothness of the data distribution and model over-parametrization. Our main theoretical contribution is to prove that half-rectified single layer networks are asymptotically connected, and we provide explicit bounds that reveal the aforementioned interplay. The conditioning of gradient descent is the next challenge we address. We study this question through the geometry of the level sets, and we introduce an algorithm to efficiently estimate the regularity of such sets on large-scale networks. Our empirical results show that these level sets remain connected throughout all the learning phase, suggesting a near convex behavior, but they become exponentially more curvy as the energy level decays, in accordance to what is observed in practice with very low curvature attractors.