 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVG-TVP: Multimodal Procedural Planning via Visually Grounded Text-Video Prompting
Dec 16, 2024



Large Language Model (LLM)-based agents have shown promise in procedural tasks, but the potential of multimodal instructions augmented by texts and videos to assist users remains under-explored. To address this gap, we propose the Visually Grounded Text-Video Prompting (VG-TVP) method which is a novel LLM-empowered Multimodal Procedural Planning (MPP) framework. It generates cohesive text and video procedural plans given a specified high-level objective. The main challenges are achieving textual and visual informativeness, temporal coherence, and accuracy in procedural plans. VG-TVP leverages the zero-shot reasoning capability of LLMs, the video-to-text generation ability of the video captioning models, and the text-to-video generation ability of diffusion models. VG-TVP improves the interaction between modalities by proposing a novel Fusion of Captioning (FoC) method and using Text-to-Video Bridge (T2V-B) and Video-to-Text Bridge (V2T-B). They allow LLMs to guide the generation of visually-grounded text plans and textual-grounded video plans. To address the scarcity of datasets suitable for MPP, we have curated a new dataset called Daily-Life Task Procedural Plans (Daily-PP). We conduct comprehensive experiments and benchmarks to evaluate human preferences (regarding textual and visual informativeness, temporal coherence, and plan accuracy). Our VG-TVP method outperforms unimodal baselines on the Daily-PP dataset.
Towards Debiasing Frame Length Bias in Text-Video Retrieval via Causal Intervention
Sep 17, 2023



Many studies focus on improving pretraining or developing new backbones in text-video retrieval. However, existing methods may suffer from the learning and inference bias issue, as recent research suggests in other text-video-related tasks. For instance, spatial appearance features on action recognition or temporal object co-occurrences on video scene graph generation could induce spurious correlations. In this work, we present a unique and systematic study of a temporal bias due to frame length discrepancy between training and test sets of trimmed video clips, which is the first such attempt for a text-video retrieval task, to the best of our knowledge. We first hypothesise and verify the bias on how it would affect the model illustrated with a baseline study. Then, we propose a causal debiasing approach and perform extensive experiments and ablation studies on the Epic-Kitchens-100, YouCook2, and MSR-VTT datasets. Our model overpasses the baseline and SOTA on nDCG, a semantic-relevancy-focused evaluation metric which proves the bias is mitigated, as well as on the other conventional metrics.
An Overview of Challenges in Egocentric Text-Video Retrieval
Jun 07, 2023



Text-video retrieval contains various challenges, including biases coming from diverse sources. We highlight some of them supported by illustrations to open a discussion. Besides, we address one of the biases, frame length bias, with a simple method which brings a very incremental but promising increase. We conclude with future directions.
Exploiting Semantic Role Contextualized Video Features for Multi-Instance Text-Video Retrieval EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022
Jun 29, 2022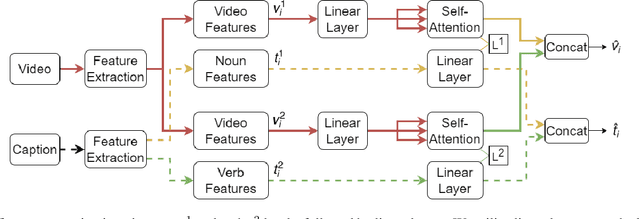
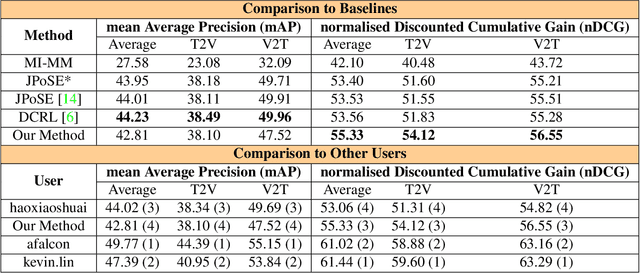
In this report, we present our approach for EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022. We first parse sentences into semantic roles corresponding to verbs and nouns; then utilize self-attentions to exploit semantic role contextualized video features along with textual features via triplet losses in multiple embedding spaces. Our method overpasses the strong baseline in normalized Discounted Cumulative Gain (nDCG), which is more valuable for semantic similarity. Our submission is ranked 3rd for nDCG and ranked 4th for mAP.
Semantic Role Aware Correlation Transformer for Text to Video Retrieval
Jun 26, 2022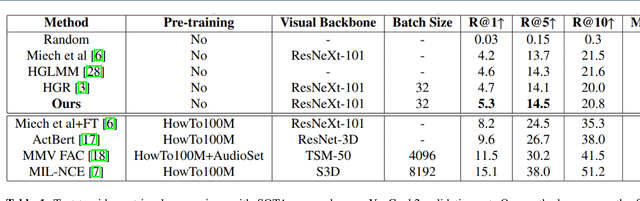

With the emergence of social media, voluminous video clips are uploaded every day, and retrieving the most relevant visual content with a language query becomes critical. Most approaches aim to learn a joint embedding space for plain textual and visual contents without adequately exploiting their intra-modality structures and inter-modality correlations. This paper proposes a novel transformer that explicitly disentangles the text and video into semantic roles of objects, spatial contexts and temporal contexts with an attention scheme to learn the intra- and inter-role correlations among the three roles to discover discriminative features for matching at different levels. The preliminary results on popular YouCook2 indicate that our approach surpasses a current state-of-the-art method, with a high margin in all metrics. It also overpasses two SOTA methods in terms of two metrics.
* Camera-ready for ICIP 2021
RoME: Role-aware Mixture-of-Expert Transformer for Text-to-Video Retrieval
Jun 26, 2022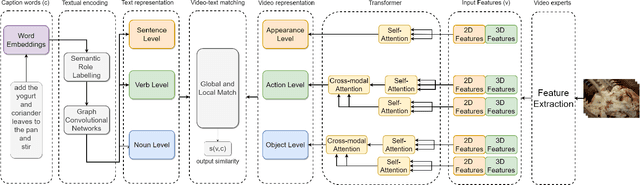
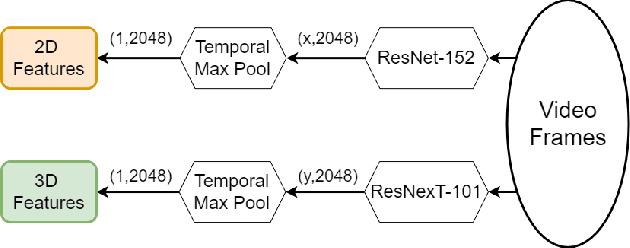
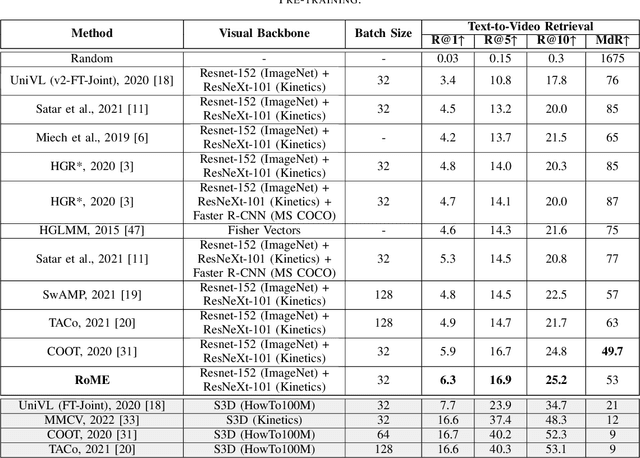
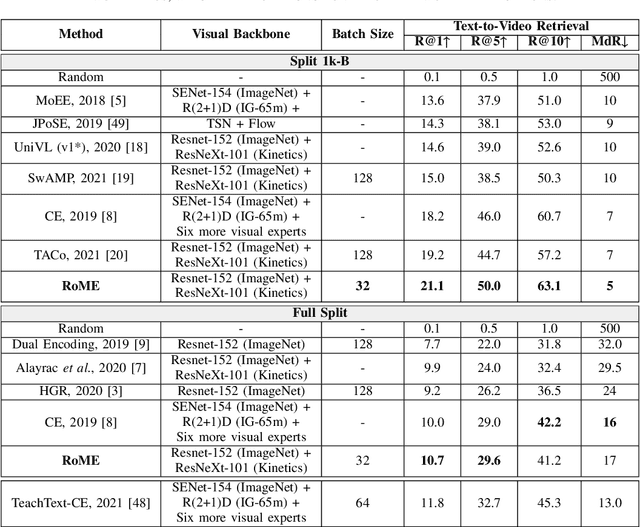
Seas of videos are uploaded daily with the popularity of social channels; thus, retrieving the most related video contents with user textual queries plays a more crucial role. Most methods consider only one joint embedding space between global visual and textual features without considering the local structures of each modality. Some other approaches consider multiple embedding spaces consisting of global and local features separately, ignoring rich inter-modality correlations. We propose a novel mixture-of-expert transformer RoME that disentangles the text and the video into three levels; the roles of spatial contexts, temporal contexts, and object contexts. We utilize a transformer-based attention mechanism to fully exploit visual and text embeddings at both global and local levels with mixture-of-experts for considering inter-modalities and structures' correlations. The results indicate that our method outperforms the state-of-the-art methods on the YouCook2 and MSR-VTT datasets, given the same visual backbone without pre-training. Finally, we conducted extensive ablation studies to elucidate our design choices.
Deep Learning Based Vehicle Make-Model Classification
Aug 23, 2018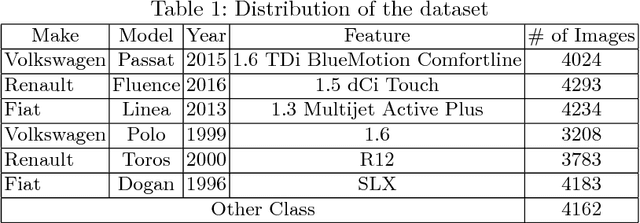
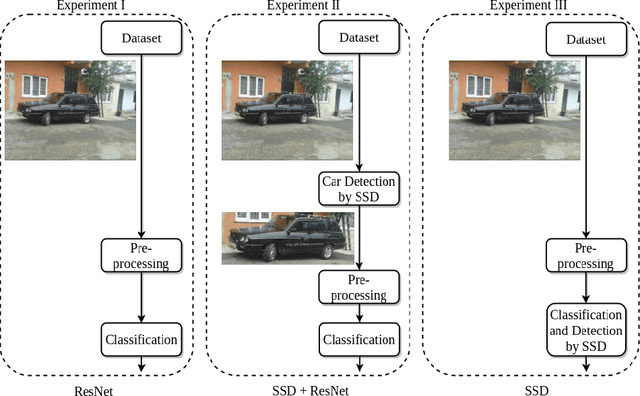
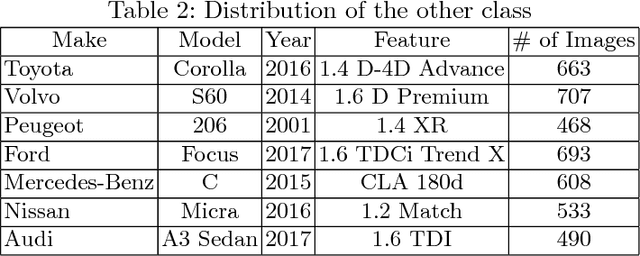
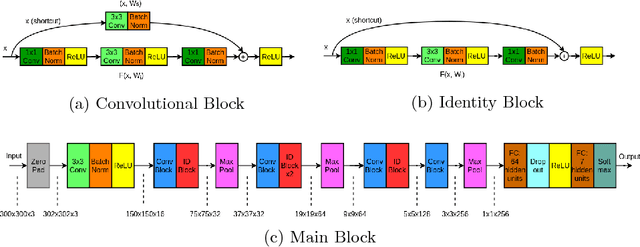
This paper studies the problems of vehicle make & model classification. Some of the main challenges are reaching high classification accuracy and reducing the annotation time of the images. To address these problems, we have created a fine-grained database using online vehicle marketplaces of Turkey. A pipeline is proposed to combine an SSD (Single Shot Multibox Detector) model with a CNN (Convolutional Neural Network) model to train on the database. In the pipeline, we first detect the vehicles by following an algorithm which reduces the time for annotation. Then, we feed them into the CNN model. It is reached approximately 4% better classification accuracy result than using a conventional CNN model. Next, we propose to use the detected vehicles as ground truth bounding box (GTBB) of the images and feed them into an SSD model in another pipeline. At this stage, it is reached reasonable classification accuracy result without using perfectly shaped GTBB. Lastly, an application is implemented in a use case by using our proposed pipelines. It detects the unauthorized vehicles by comparing their license plate numbers and make & models. It is assumed that license plates are readable.