 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialysis Risk Prediction and Treatment Effect Estimation for AKI patients using Longitudinal Electronic Health Records
Apr 27, 2026Progression to dialysis or end-stage renal disease is a rare but clinically important outcome. Clinicians need evidence on how medication exposures influence downstream risk. We constructed a fixed-window EHR cohort (90-day observation, 730-day prediction; N=81401; dialysis/ESRD prevalence: 1.1%) and modeled sequences of diagnoses, procedures, and medications with kidney laboratory trends (creatinine, BUN, eGFR). A transformer-based causal multi-head model was trained to estimate drug- and ingredient-level average treatment effects (ATEs) using counterfactual exposure removal and insertion under a full medication history setup. On test set, predictive performance reached an AUC of 0.694 and PR-AUC of 0.094. At the selected decision threshold (0.883), the model achieved an F1 score of 0.201 with a Brier score of 0.018. Post-hoc causal analyses of lab changes (eGFR, creatinine, BUN) using IPTW, AIPW, naive, and covariate-adjusted OLS methods assessed clinical directionality. Results showed partial protective-direction support for ACE/ARB exposures and worsening-direction signals for loop diuretics.
LHAW: Controllable Underspecification for Long-Horizon Tasks
Feb 11, 2026Long-horizon workflow agents that operate effectively over extended periods are essential for truly autonomous systems. Their reliable execution critically depends on the ability to reason through ambiguous situations in which clarification seeking is necessary to ensure correct task execution. However, progress is limited by the lack of scalable, task-agnostic frameworks for systematically curating and measuring the impact of ambiguity across custom workflows. We address this gap by introducing LHAW (Long-Horizon Augmented Workflows), a modular, dataset-agnostic synthetic pipeline that transforms any well-specified task into controllable underspecified variants by systematically removing information across four dimensions - Goals, Constraints, Inputs, and Context - at configurable severity levels. Unlike approaches that rely on LLM predictions of ambiguity, LHAW validates variants through empirical agent trials, classifying them as outcome-critical, divergent, or benign based on observed terminal state divergence. We release 285 task variants from TheAgentCompany, SWE-Bench Pro and MCP-Atlas according to our taxonomy alongside formal analysis measuring how current agents detect, reason about, and resolve underspecification across ambiguous settings. LHAW provides the first systematic framework for cost-sensitive evaluation of agent clarification behavior in long-horizon settings, enabling development of reliable autonomous systems.
Exact Instance Compression for Convex Empirical Risk Minimization via Color Refinement
Jan 31, 2026Empirical risk minimization (ERM) can be computationally expensive, with standard solvers scaling poorly even in the convex setting. We propose a novel lossless compression framework for convex ERM based on color refinement, extending prior work from linear programs and convex quadratic programs to a broad class of differentiable convex optimization problems. We develop concrete algorithms for a range of models, including linear and polynomial regression, binary and multiclass logistic regression, regression with elastic-net regularization, and kernel methods such as kernel ridge regression and kernel logistic regression. Numerical experiments on representative datasets demonstrate the effectiveness of the proposed approach.
METER-ML: A Multi-sensor Earth Observation Benchmark for Automated Methane Source Mapping
Jul 22, 2022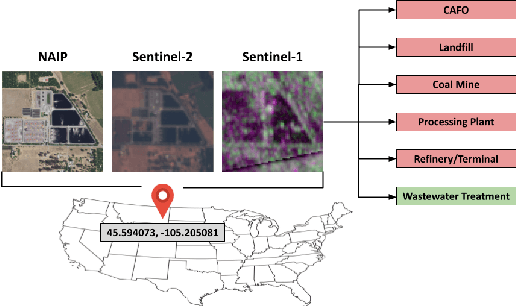
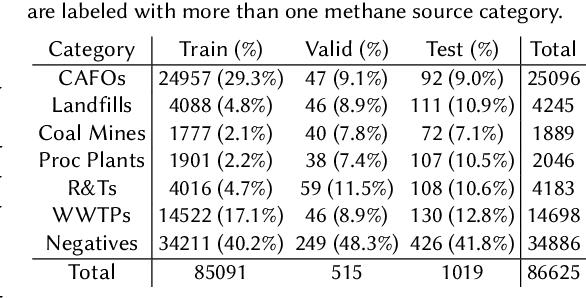


Reducing methane emissions is essential for mitigating global warming. To attribute methane emissions to their sources, a comprehensive dataset of methane source infrastructure is necessary. Recent advancements with deep learning on remotely sensed imagery have the potential to identify the locations and characteristics of methane sources, but there is a substantial lack of publicly available data to enable machine learning researchers and practitioners to build automated mapping approaches. To help fill this gap, we construct a multi-sensor dataset called METER-ML containing 86,625 georeferenced NAIP, Sentinel-1, and Sentinel-2 images in the U.S. labeled for the presence or absence of methane source facilities including concentrated animal feeding operations, coal mines, landfills, natural gas processing plants, oil refineries and petroleum terminals, and wastewater treatment plants. We experiment with a variety of models that leverage different spatial resolutions, spatial footprints, image products, and spectral bands. We find that our best model achieves an area under the precision recall curve of 0.915 for identifying concentrated animal feeding operations and 0.821 for oil refineries and petroleum terminals on an expert-labeled test set, suggesting the potential for large-scale mapping. We make METER-ML freely available at https://stanfordmlgroup.github.io/projects/meter-ml/ to support future work on automated methane source mapping.