 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Synchronization of Driving Data Using Vibration and Steering Events
Mar 01, 2016

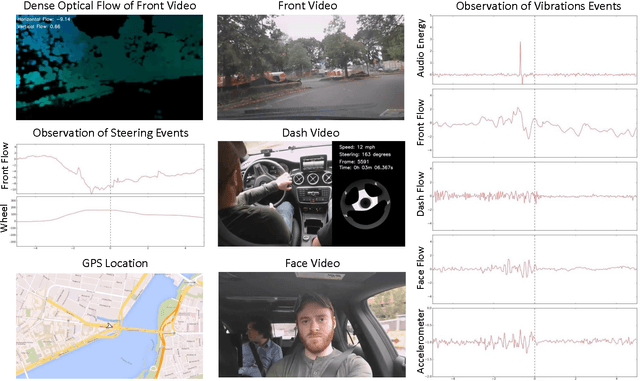
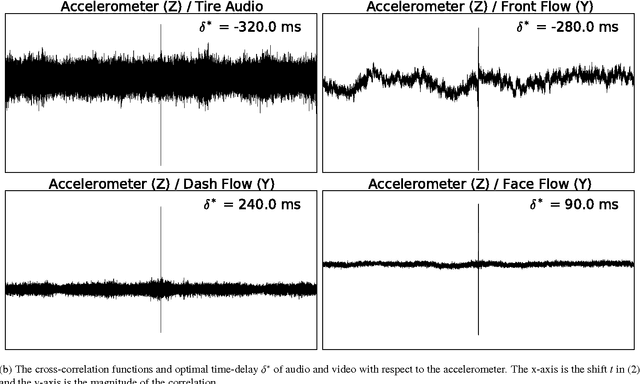
We propose a method for automated synchronization of vehicle sensors useful for the study of multi-modal driver behavior and for the design of advanced driver assistance systems. Multi-sensor decision fusion relies on synchronized data streams in (1) the offline supervised learning context and (2) the online prediction context. In practice, such data streams are often out of sync due to the absence of a real-time clock, use of multiple recording devices, or improper thread scheduling and data buffer management. Cross-correlation of accelerometer, telemetry, audio, and dense optical flow from three video sensors is used to achieve an average synchronization error of 13 milliseconds. The insight underlying the effectiveness of the proposed approach is that the described sensors capture overlapping aspects of vehicle vibrations and vehicle steering allowing the cross-correlation function to serve as a way to compute the delay shift in each sensor. Furthermore, we show the decrease in synchronization error as a function of the duration of the data stream.
Driver Gaze Region Estimation Without Using Eye Movement
Mar 01, 2016
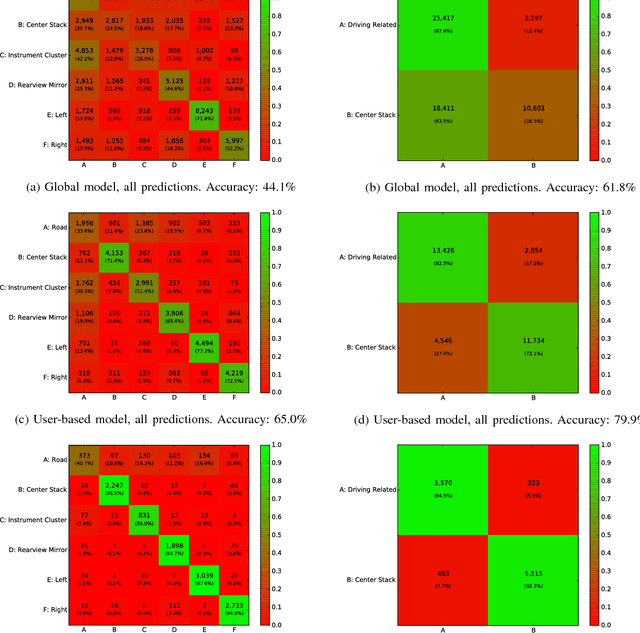
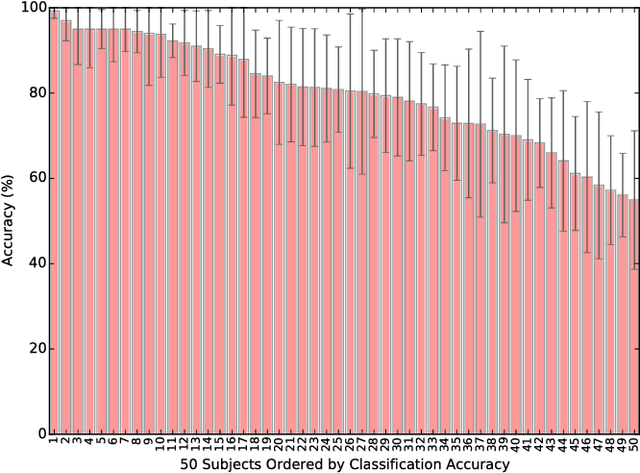
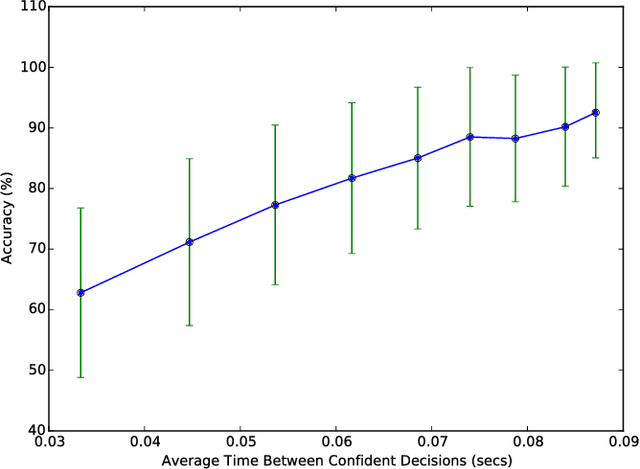
Automated estimation of the allocation of a driver's visual attention may be a critical component of future Advanced Driver Assistance Systems. In theory, vision-based tracking of the eye can provide a good estimate of gaze location. In practice, eye tracking from video is challenging because of sunglasses, eyeglass reflections, lighting conditions, occlusions, motion blur, and other factors. Estimation of head pose, on the other hand, is robust to many of these effects, but cannot provide as fine-grained of a resolution in localizing the gaze. However, for the purpose of keeping the driver safe, it is sufficient to partition gaze into regions. In this effort, we propose a system that extracts facial features and classifies their spatial configuration into six regions in real-time. Our proposed method achieves an average accuracy of 91.4% at an average decision rate of 11 Hz on a dataset of 50 drivers from an on-road study.
Detecting Road Surface Wetness from Audio: A Deep Learning Approach
Dec 04, 2015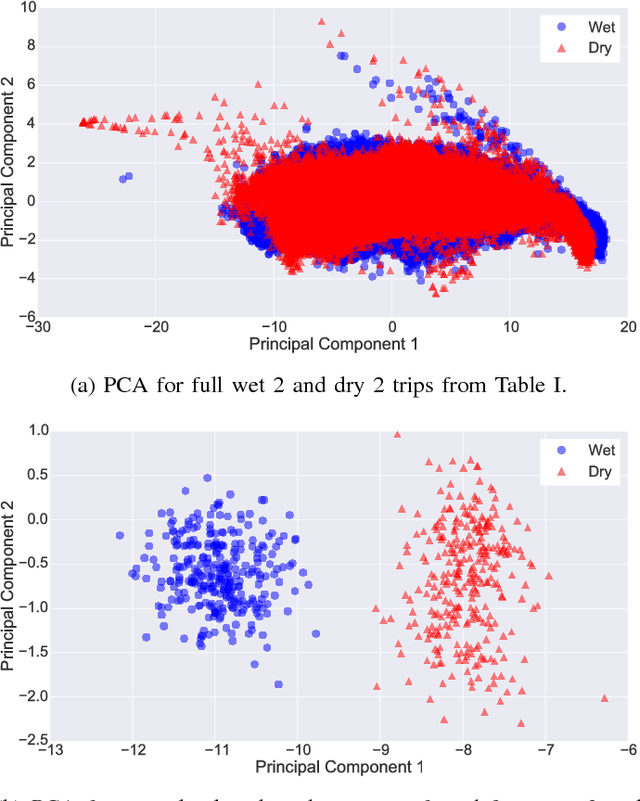


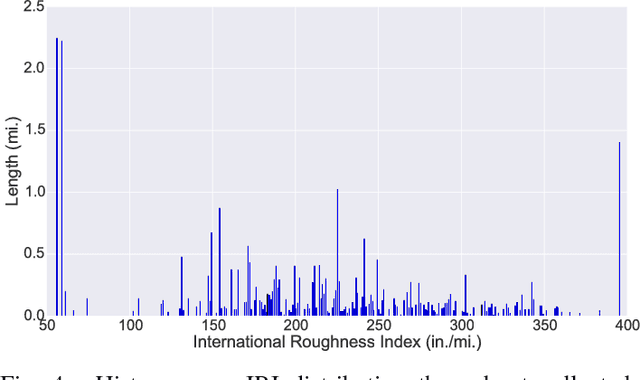
We introduce a recurrent neural network architecture for automated road surface wetness detection from audio of tire-surface interaction. The robustness of our approach is evaluated on 785,826 bins of audio that span an extensive range of vehicle speeds, noises from the environment, road surface types, and pavement conditions including international roughness index (IRI) values from 25 in/mi to 1400 in/mi. The training and evaluation of the model are performed on different roads to minimize the impact of environmental and other external factors on the accuracy of the classification. We achieve an unweighted average recall (UAR) of 93.2% across all vehicle speeds including 0 mph. The classifier still works at 0 mph because the discriminating signal is present in the sound of other vehicles driving by.