 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining COVID-19 Forecasting using Spatio-Temporal Graph Neural Networks
Jul 06, 2020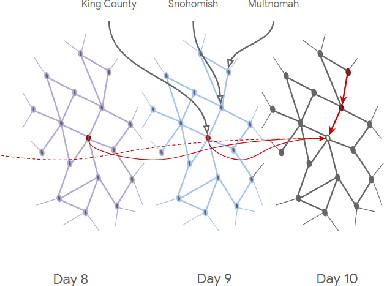
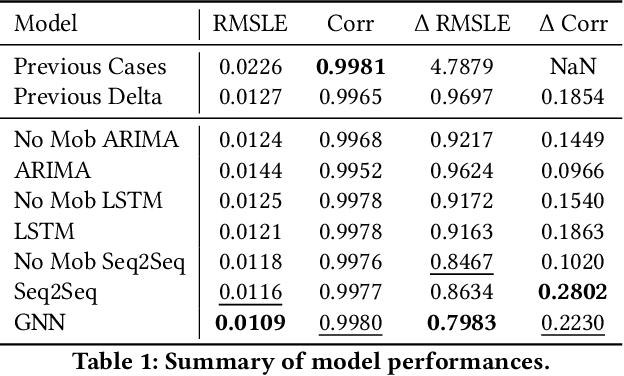
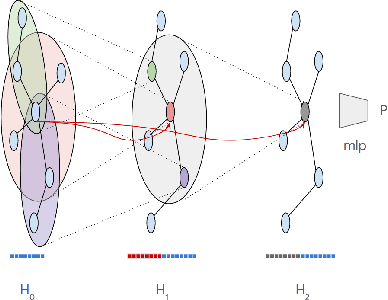
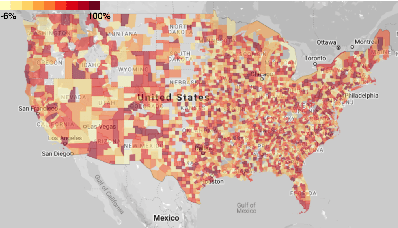
In this work, we examine a novel forecasting approach for COVID-19 case prediction that uses Graph Neural Networks and mobility data. In contrast to existing time series forecasting models, the proposed approach learns from a single large-scale spatio-temporal graph, where nodes represent the region-level human mobility, spatial edges represent the human mobility based inter-region connectivity, and temporal edges represent node features through time. We evaluate this approach on the US county level COVID-19 dataset, and demonstrate that the rich spatial and temporal information leveraged by the graph neural network allows the model to learn complex dynamics. We show a 6% reduction of RMSLE and an absolute Pearson Correlation improvement from 0.9978 to 0.998 compared to the best performing baseline models. This novel source of information combined with graph based deep learning approaches can be a powerful tool to understand the spread and evolution of COVID-19. We encourage others to further develop a novel modeling paradigm for infectious disease based on GNNs and high resolution mobility data.
Scaling Graph Neural Networks with Approximate PageRank
Jul 03, 2020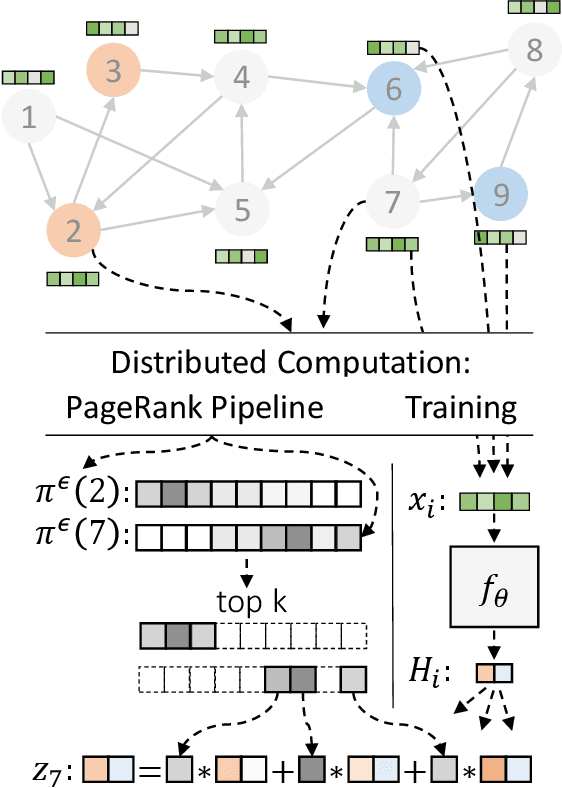



Graph neural networks (GNNs) have emerged as a powerful approach for solving many network mining tasks. However, learning on large graphs remains a challenge - many recently proposed scalable GNN approaches rely on an expensive message-passing procedure to propagate information through the graph. We present the PPRGo model which utilizes an efficient approximation of information diffusion in GNNs resulting in significant speed gains while maintaining state-of-the-art prediction performance. In addition to being faster, PPRGo is inherently scalable, and can be trivially parallelized for large datasets like those found in industry settings. We demonstrate that PPRGo outperforms baselines in both distributed and single-machine training environments on a number of commonly used academic graphs. To better analyze the scalability of large-scale graph learning methods, we introduce a novel benchmark graph with 12.4 million nodes, 173 million edges, and 2.8 million node features. We show that training PPRGo from scratch and predicting labels for all nodes in this graph takes under 2 minutes on a single machine, far outpacing other baselines on the same graph. We discuss the practical application of PPRGo to solve large-scale node classification problems at Google.
Graph Clustering with Graph Neural Networks
Jun 30, 2020
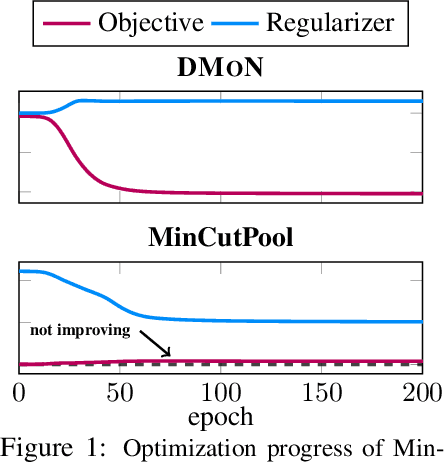
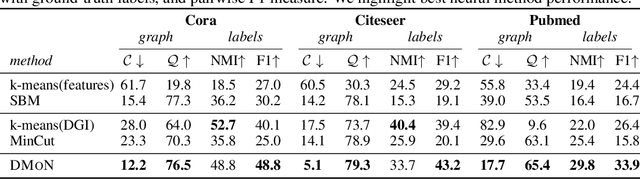
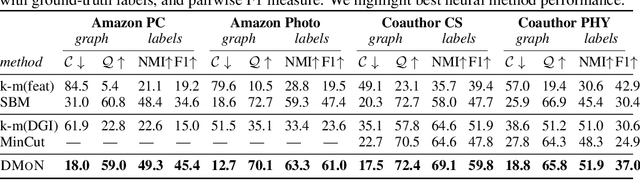
Graph Neural Networks (GNNs) have achieved state-of-the-art results on many graph analysis tasks such as node classification and link prediction. However, important unsupervised problems on graphs, such as graph clustering, have proved more resistant to advances in GNNs. In this paper, we study unsupervised training of GNN pooling in terms of their clustering capabilities. We start by drawing a connection between graph clustering and graph pooling: intuitively, a good graph clustering is what one would expect from a GNN pooling layer. Counterintuitively, we show that this is not true for state-of-the-art pooling methods, such as MinCut pooling. To address these deficiencies, we introduce Deep Modularity Networks (DMoN), an unsupervised pooling method inspired by the modularity measure of clustering quality, and show how it tackles recovery of the challenging clustering structure of real-world graphs. In order to clarify the regimes where existing methods fail, we carefully design a set of experiments on synthetic data which show that DMoN is able to jointly leverage the signal from the graph structure and node attributes. Similarly, on real-world data, we show that DMoN produces high quality clusters which correlate strongly with ground truth labels, achieving state-of-the-art results.
Machine Learning on Graphs: A Model and Comprehensive Taxonomy
May 07, 2020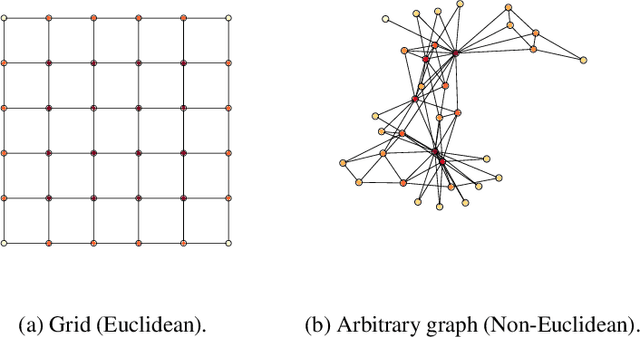
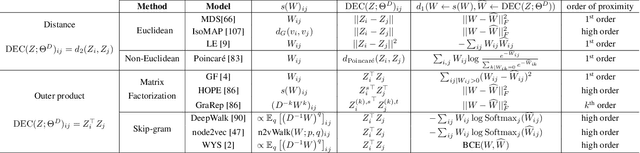
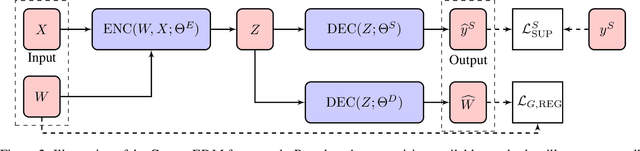

There has been a surge of recent interest in learning representations for graph-structured data. Graph representation learning methods have generally fallen into three main categories, based on the availability of labeled data. The first, network embedding (such as shallow graph embedding or graph auto-encoders), focuses on learning unsupervised representations of relational structure. The second, graph regularized neural networks, leverages graphs to augment neural network losses with a regularization objective for semi-supervised learning. The third, graph neural networks, aims to learn differentiable functions over discrete topologies with arbitrary structure. However, despite the popularity of these areas there has been surprisingly little work on unifying the three paradigms. Here, we aim to bridge the gap between graph neural networks, network embedding and graph regularization models. We propose a comprehensive taxonomy of representation learning methods for graph-structured data, aiming to unify several disparate bodies of work. Specifically, we propose a Graph Encoder Decoder Model (GRAPHEDM), which generalizes popular algorithms for semi-supervised learning on graphs (e.g. GraphSage, Graph Convolutional Networks, Graph Attention Networks), and unsupervised learning of graph representations (e.g. DeepWalk, node2vec, etc) into a single consistent approach. To illustrate the generality of this approach, we fit over thirty existing methods into this framework. We believe that this unifying view both provides a solid foundation for understanding the intuition behind these methods, and enables future research in the area.
Just SLaQ When You Approximate: Accurate Spectral Distances for Web-Scale Graphs
Mar 03, 2020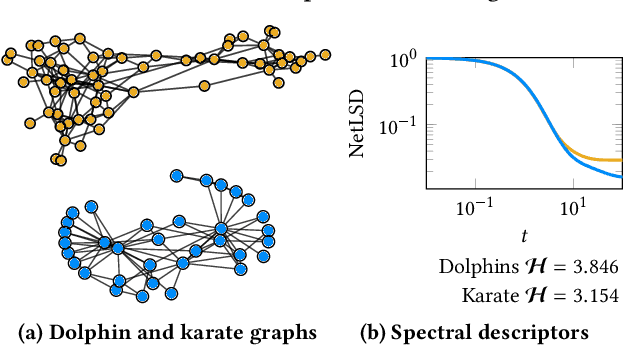

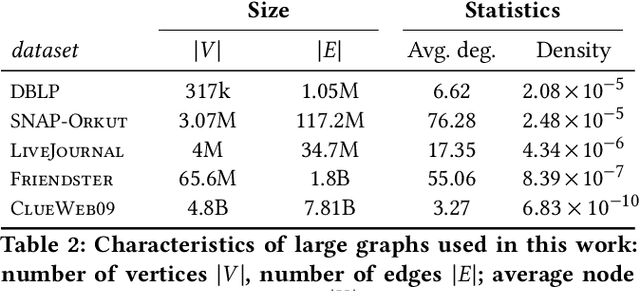

Graph comparison is a fundamental operation in data mining and information retrieval. Due to the combinatorial nature of graphs, it is hard to balance the expressiveness of the similarity measure and its scalability. Spectral analysis provides quintessential tools for studying the multi-scale structure of graphs and is a well-suited foundation for reasoning about differences between graphs. However, computing full spectrum of large graphs is computationally prohibitive; thus, spectral graph comparison methods often rely on rough approximation techniques with weak error guarantees. In this work, we propose SLaQ, an efficient and effective approximation technique for computing spectral distances between graphs with billions of nodes and edges. We derive the corresponding error bounds and demonstrate that accurate computation is possible in time linear in the number of graph edges. In a thorough experimental evaluation, we show that SLaQ outperforms existing methods, oftentimes by several orders of magnitude in approximation accuracy, and maintains comparable performance, allowing to compare million-scale graphs in a matter of minutes on a single machine.
MONET: Debiasing Graph Embeddings via the Metadata-Orthogonal Training Unit
Sep 25, 2019
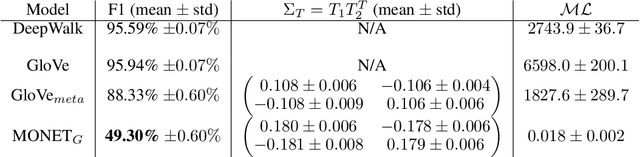
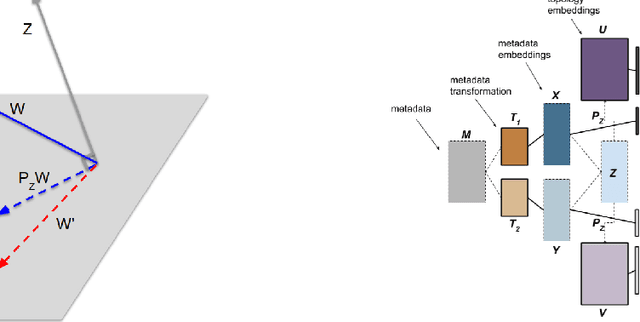

Are Graph Neural Networks (GNNs) fair? In many real world graphs, the formation of edges is related to certain node attributes (e.g. gender, community, reputation). In this case, standard GNNs using these edges will be biased by this information, as it is encoded in the structure of the adjacency matrix itself. In this paper, we show that when metadata is correlated with the formation of node neighborhoods, unsupervised node embedding dimensions learn this metadata. This bias implies an inability to control for important covariates in real-world applications, such as recommendation systems. To solve these issues, we introduce the Metadata-Orthogonal Node Embedding Training (MONET) unit, a general model for debiasing embeddings of nodes in a graph. MONET achieves this by ensuring that the node embeddings are trained on a hyperplane orthogonal to that of the node metadata. This effectively organizes unstructured embedding dimensions into an interpretable topology-only, metadata-only division with no linear interactions. We illustrate the effectiveness of MONET though our experiments on a variety of real world graphs, which shows that our method can learn and remove the effect of arbitrary covariates in tasks such as preventing the leakage of political party affiliation in a blog network, and thwarting the gaming of embedding-based recommendation systems.
MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing
May 28, 2019
Existing popular methods for semi-supervised learning with Graph Neural Networks (such as the Graph Convolutional Network) provably cannot learn a general class of neighborhood mixing relationships. To address this weakness, we propose a new model, MixHop, that can learn these relationships, including difference operators, by repeatedly mixing feature representations of neighbors at various distances. Mixhop requires no additional memory or computational complexity, and outperforms on challenging baselines. In addition, we propose sparsity regularization that allows us to visualize how the network prioritizes neighborhood information across different graph datasets. Our analysis of the learned architectures reveals that neighborhood mixing varies per datasets.
Is a Single Embedding Enough? Learning Node Representations that Capture Multiple Social Contexts
May 06, 2019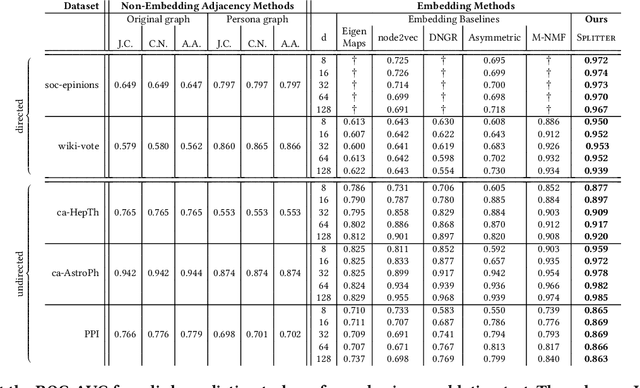
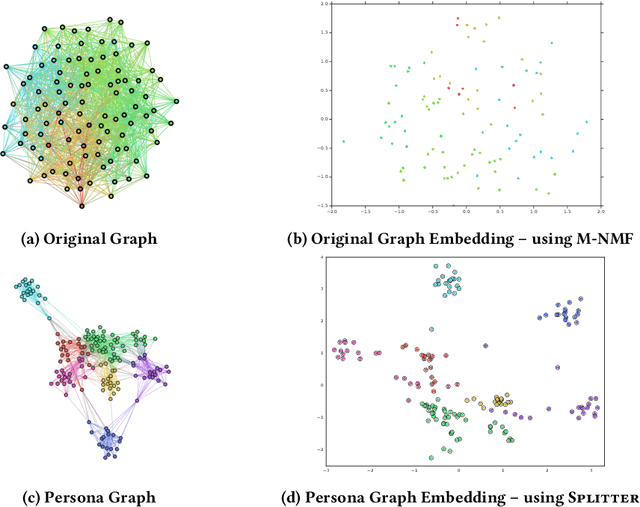

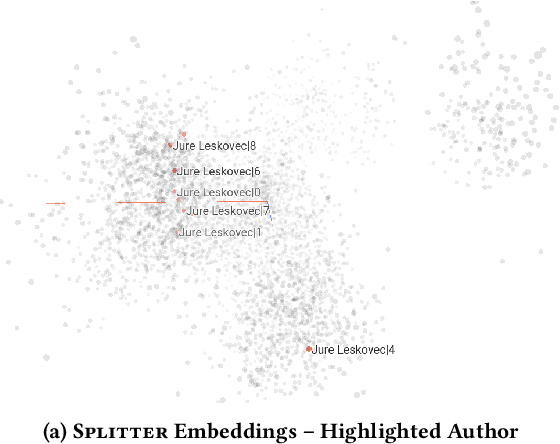
Recent interest in graph embedding methods has focused on learning a single representation for each node in the graph. But can nodes really be best described by a single vector representation? In this work, we propose a method for learning multiple representations of the nodes in a graph (e.g., the users of a social network). Based on a principled decomposition of the ego-network, each representation encodes the role of the node in a different local community in which the nodes participate. These representations allow for improved reconstruction of the nuanced relationships that occur in the graph -- a phenomenon that we illustrate through state-of-the-art results on link prediction tasks on a variety of graphs, reducing the error by up to $90\%$. In addition, we show that these embeddings allow for effective visual analysis of the learned community structure.
DDGK: Learning Graph Representations for Deep Divergence Graph Kernels
Apr 21, 2019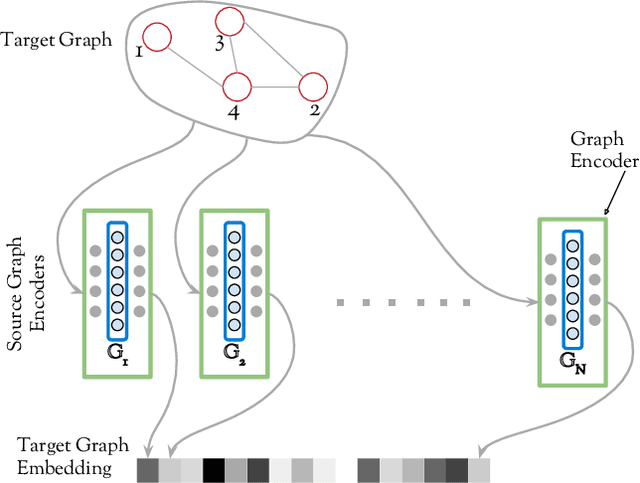

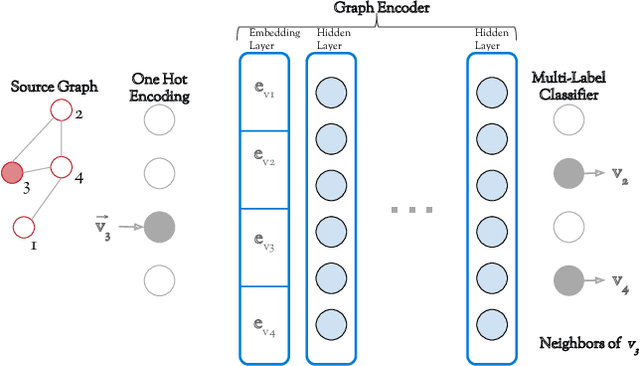
Can neural networks learn to compare graphs without feature engineering? In this paper, we show that it is possible to learn representations for graph similarity with neither domain knowledge nor supervision (i.e.\ feature engineering or labeled graphs). We propose Deep Divergence Graph Kernels, an unsupervised method for learning representations over graphs that encodes a relaxed notion of graph isomorphism. Our method consists of three parts. First, we learn an encoder for each anchor graph to capture its structure. Second, for each pair of graphs, we train a cross-graph attention network which uses the node representations of an anchor graph to reconstruct another graph. This approach, which we call isomorphism attention, captures how well the representations of one graph can encode another. We use the attention-augmented encoder's predictions to define a divergence score for each pair of graphs. Finally, we construct an embedding space for all graphs using these pair-wise divergence scores. Unlike previous work, much of which relies on 1) supervision, 2) domain specific knowledge (e.g. a reliance on Weisfeiler-Lehman kernels), and 3) known node alignment, our unsupervised method jointly learns node representations, graph representations, and an attention-based alignment between graphs. Our experimental results show that Deep Divergence Graph Kernels can learn an unsupervised alignment between graphs, and that the learned representations achieve competitive results when used as features on a number of challenging graph classification tasks. Furthermore, we illustrate how the learned attention allows insight into the the alignment of sub-structures across graphs.
* www '19
Watch Your Step: Learning Node Embeddings via Graph Attention
Sep 12, 2018
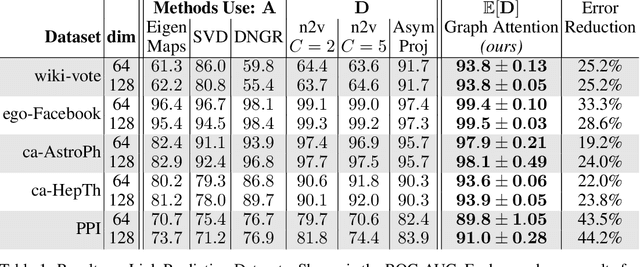
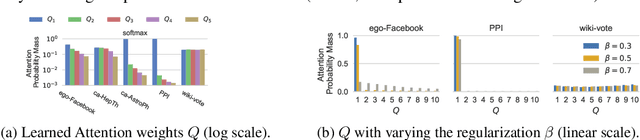

Graph embedding methods represent nodes in a continuous vector space, preserving information from the graph (e.g. by sampling random walks). There are many hyper-parameters to these methods (such as random walk length) which have to be manually tuned for every graph. In this paper, we replace random walk hyper-parameters with trainable parameters that we automatically learn via backpropagation. In particular, we learn a novel attention model on the power series of the transition matrix, which guides the random walk to optimize an upstream objective. Unlike previous approaches to attention models, the method that we propose utilizes attention parameters exclusively on the data (e.g. on the random walk), and not used by the model for inference. We experiment on link prediction tasks, as we aim to produce embeddings that best-preserve the graph structure, generalizing to unseen information. We improve state-of-the-art on a comprehensive suite of real world datasets including social, collaboration, and biological networks. Adding attention to random walks can reduce the error by 20% to 45% on datasets we attempted. Further, our learned attention parameters are different for every graph, and our automatically-found values agree with the optimal choice of hyper-parameter if we manually tune existing methods.