 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-Budget Best-Arm Identification with Heterogeneous Reward Variances
Jun 13, 2023We study the problem of best-arm identification (BAI) in the fixed-budget setting with heterogeneous reward variances. We propose two variance-adaptive BAI algorithms for this setting: SHVar for known reward variances and SHAdaVar for unknown reward variances. Our algorithms rely on non-uniform budget allocations among the arms where the arms with higher reward variances are pulled more often than those with lower variances. The main algorithmic novelty is in the design of SHAdaVar, which allocates budget greedily based on overestimating the unknown reward variances. We bound probabilities of misidentifying the best arms in both SHVar and SHAdaVar. Our analyses rely on novel lower bounds on the number of pulls of an arm that do not require closed-form solutions to the budget allocation problem. Since one of our budget allocation problems is analogous to the optimal experiment design with unknown variances, we believe that our results are of a broad interest. Our experiments validate our theory, and show that SHVar and SHAdaVar outperform algorithms from prior works with analytical guarantees.
Only Pay for What Is Uncertain: Variance-Adaptive Thompson Sampling
Mar 16, 2023Most bandit algorithms assume that the reward variance or its upper bound is known. While variance overestimation is usually safe and sound, it increases regret. On the other hand, an underestimated variance may lead to linear regret due to committing early to a suboptimal arm. This motivated prior works on variance-aware frequentist algorithms. We lay foundations for the Bayesian setting. In particular, we study multi-armed bandits with known and \emph{unknown heterogeneous reward variances}, and develop Thompson sampling algorithms for both and bound their Bayes regret. Our regret bounds decrease with lower reward variances, which make learning easier. The bound for unknown reward variances captures the effect of the prior on learning reward variances and is the first of its kind. Our experiments show the superiority of variance-aware Bayesian algorithms and also highlight their robustness.
Multiplier Bootstrap-based Exploration
Feb 03, 2023



Despite the great interest in the bandit problem, designing efficient algorithms for complex models remains challenging, as there is typically no analytical way to quantify uncertainty. In this paper, we propose Multiplier Bootstrap-based Exploration (MBE), a novel exploration strategy that is applicable to any reward model amenable to weighted loss minimization. We prove both instance-dependent and instance-independent rate-optimal regret bounds for MBE in sub-Gaussian multi-armed bandits. With extensive simulation and real data experiments, we show the generality and adaptivity of MBE.
Selective Uncertainty Propagation in Offline RL
Feb 01, 2023We study the finite-horizon offline reinforcement learning (RL) problem. Since actions at any state can affect next-state distributions, the related distributional shift challenges can make this problem far more statistically complex than offline policy learning for a finite sequence of stochastic contextual bandit environments. We formalize this insight by showing that the statistical hardness of offline RL instances can be measured by estimating the size of actions' impact on next-state distributions. Furthermore, this estimated impact allows us to propagate just enough value function uncertainty from future steps to avoid model exploitation, enabling us to develop algorithms that improve upon traditional pessimistic approaches for offline RL on statistically simple instances. Our approach is supported by theory and simulations.
Thompson Sampling with Diffusion Generative Prior
Jan 12, 2023



In this work, we initiate the idea of using denoising diffusion models to learn priors for online decision making problems. Our special focus is on the meta-learning for bandit framework, with the goal of learning a strategy that performs well across bandit tasks of a same class. To this end, we train a diffusion model that learns the underlying task distribution and combine Thompson sampling with the learned prior to deal with new tasks at test time. Our posterior sampling algorithm is designed to carefully balance between the learned prior and the noisy observations that come from the learner's interaction with the environment. To capture realistic bandit scenarios, we also propose a novel diffusion model training procedure that trains even from incomplete and/or noisy data, which could be of independent interest. Finally, our extensive experimental evaluations clearly demonstrate the potential of the proposed approach.
Multi-Task Off-Policy Learning from Bandit Feedback
Dec 09, 2022


Many practical applications, such as recommender systems and learning to rank, involve solving multiple similar tasks. One example is learning of recommendation policies for users with similar movie preferences, where the users may still rank the individual movies slightly differently. Such tasks can be organized in a hierarchy, where similar tasks are related through a shared structure. In this work, we formulate this problem as a contextual off-policy optimization in a hierarchical graphical model from logged bandit feedback. To solve the problem, we propose a hierarchical off-policy optimization algorithm (HierOPO), which estimates the parameters of the hierarchical model and then acts pessimistically with respect to them. We instantiate HierOPO in linear Gaussian models, for which we also provide an efficient implementation and analysis. We prove per-task bounds on the suboptimality of the learned policies, which show a clear improvement over not using the hierarchical model. We also evaluate the policies empirically. Our theoretical and empirical results show a clear advantage of using the hierarchy over solving each task independently.
Bayesian Fixed-Budget Best-Arm Identification
Nov 15, 2022Fixed-budget best-arm identification (BAI) is a bandit problem where the learning agent maximizes the probability of identifying the optimal arm after a fixed number of observations. In this work, we initiate the study of this problem in the Bayesian setting. We propose a Bayesian elimination algorithm and derive an upper bound on the probability that it fails to identify the optimal arm. The bound reflects the quality of the prior and is the first such bound in this setting. We prove it using a frequentist-like argument, where we carry the prior through, and then integrate out the random bandit instance at the end. Our upper bound asymptotically matches a newly established lower bound for $2$ arms. Our experimental results show that Bayesian elimination is superior to frequentist methods and competitive with the state-of-the-art Bayesian algorithms that have no guarantees in our setting.
Robust Contextual Linear Bandits
Oct 26, 2022



Model misspecification is a major consideration in applications of statistical methods and machine learning. However, it is often neglected in contextual bandits. This paper studies a common form of misspecification, an inter-arm heterogeneity that is not captured by context. To address this issue, we assume that the heterogeneity arises due to arm-specific random variables, which can be learned. We call this setting a robust contextual bandit. The arm-specific variables explain the unknown inter-arm heterogeneity, and we incorporate them in the robust contextual estimator of the mean reward and its uncertainty. We develop two efficient bandit algorithms for our setting: a UCB algorithm called RoLinUCB and a posterior-sampling algorithm called RoLinTS. We analyze both algorithms and bound their $n$-round Bayes regret. Our experiments show that RoLinTS is comparably statistically efficient to the classic methods when the misspecification is low, more robust when the misspecification is high, and significantly more computationally efficient than its naive implementation.
From Ranked Lists to Carousels: A Carousel Click Model
Sep 27, 2022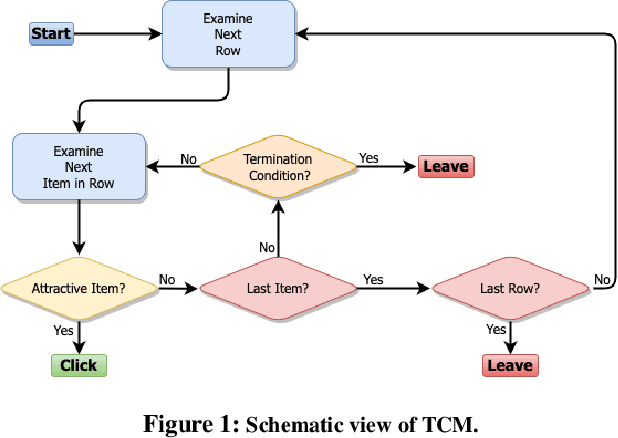
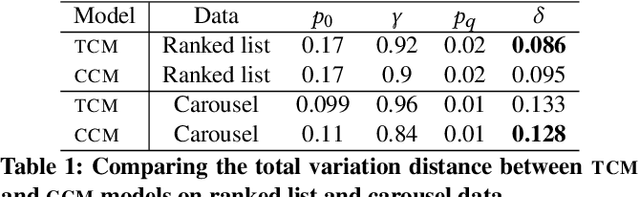
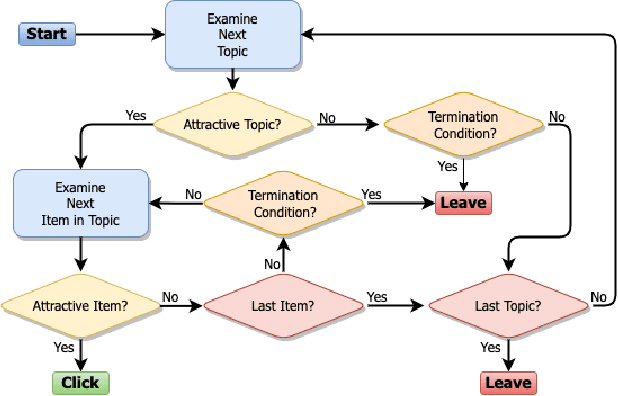
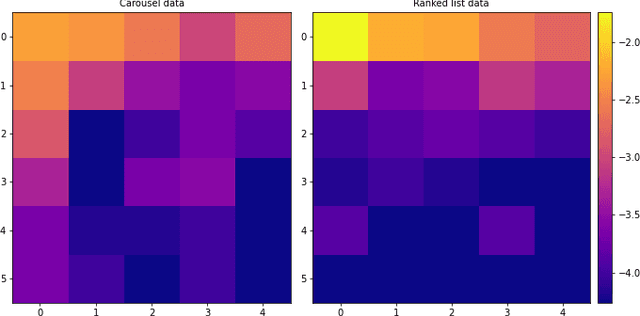
Carousel-based recommendation interfaces allow users to explore recommended items in a structured, efficient, and visually-appealing way. This made them a de-facto standard approach to recommending items to end users in many real-life recommenders. In this work, we try to explain the efficiency of carousel recommenders using a \emph{carousel click model}, a generative model of user interaction with carousel-based recommender interfaces. We study this model both analytically and empirically. Our analytical results show that the user can examine more items in the carousel click model than in a single ranked list, due to the structured way of browsing. These results are supported by a series of experiments, where we integrate the carousel click model with a recommender based on matrix factorization. We show that the combined recommender performs well on held-out test data, and leads to higher engagement with recommendations than a traditional single ranked list.
Uplifting Bandits
Jun 08, 2022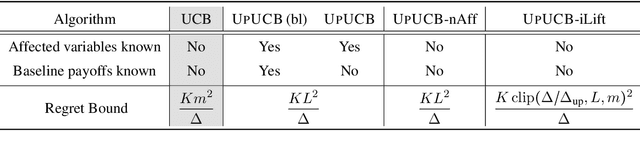
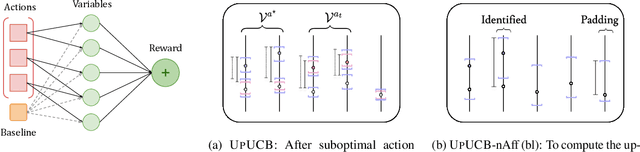

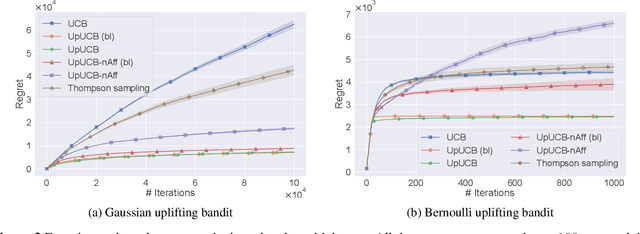
We introduce a multi-armed bandit model where the reward is a sum of multiple random variables, and each action only alters the distributions of some of them. After each action, the agent observes the realizations of all the variables. This model is motivated by marketing campaigns and recommender systems, where the variables represent outcomes on individual customers, such as clicks. We propose UCB-style algorithms that estimate the uplifts of the actions over a baseline. We study multiple variants of the problem, including when the baseline and affected variables are unknown, and prove sublinear regret bounds for all of these. We also provide lower bounds that justify the necessity of our modeling assumptions. Experiments on synthetic and real-world datasets show the benefit of methods that estimate the uplifts over policies that do not use this structure.