 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching Normalizing Flows and Probability Paths on Manifolds
Jul 11, 2022
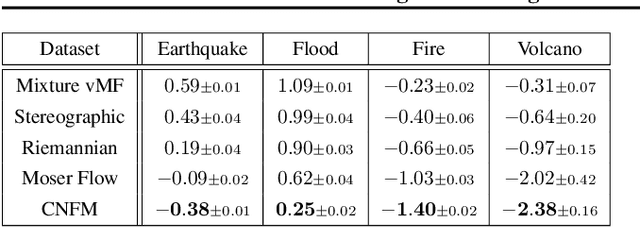
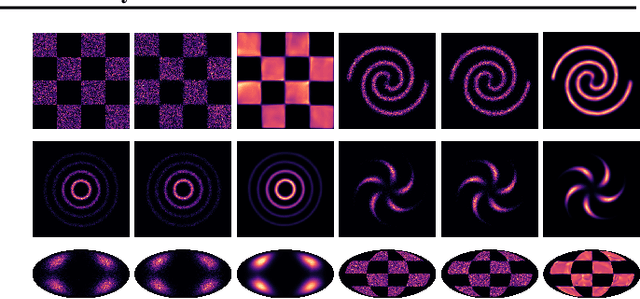
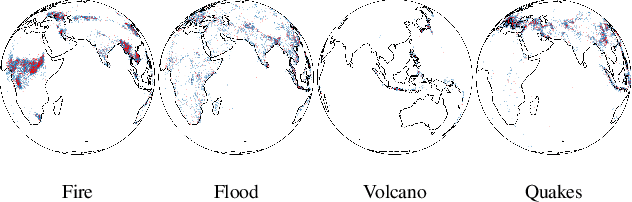
Continuous Normalizing Flows (CNFs) are a class of generative models that transform a prior distribution to a model distribution by solving an ordinary differential equation (ODE). We propose to train CNFs on manifolds by minimizing probability path divergence (PPD), a novel family of divergences between the probability density path generated by the CNF and a target probability density path. PPD is formulated using a logarithmic mass conservation formula which is a linear first order partial differential equation relating the log target probabilities and the CNF's defining vector field. PPD has several key benefits over existing methods: it sidesteps the need to solve an ODE per iteration, readily applies to manifold data, scales to high dimensions, and is compatible with a large family of target paths interpolating pure noise and data in finite time. Theoretically, PPD is shown to bound classical probability divergences. Empirically, we show that CNFs learned by minimizing PPD achieve state-of-the-art results in likelihoods and sample quality on existing low-dimensional manifold benchmarks, and is the first example of a generative model to scale to moderately high dimensional manifolds.
Nocturne: a scalable driving benchmark for bringing multi-agent learning one step closer to the real world
Jun 20, 2022
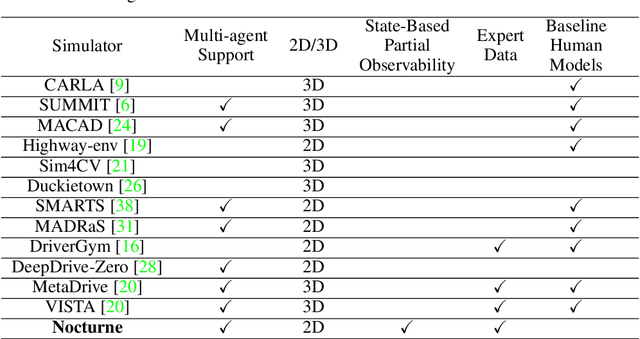
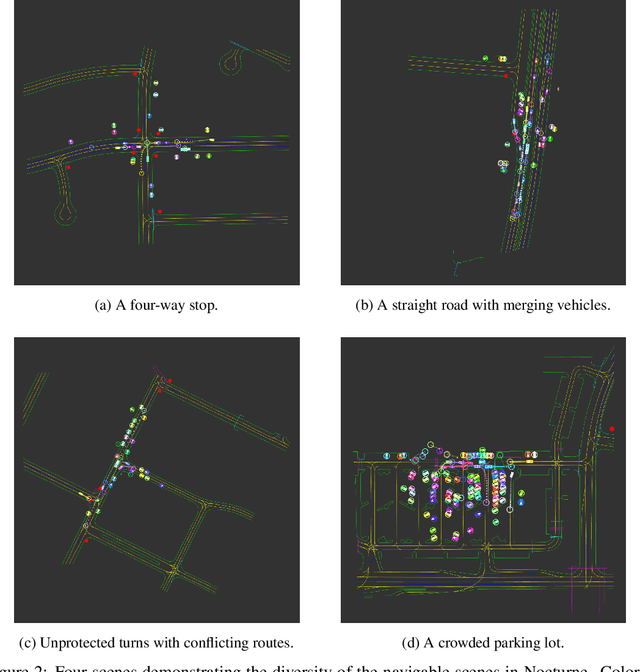

We introduce \textit{Nocturne}, a new 2D driving simulator for investigating multi-agent coordination under partial observability. The focus of Nocturne is to enable research into inference and theory of mind in real-world multi-agent settings without the computational overhead of computer vision and feature extraction from images. Agents in this simulator only observe an obstructed view of the scene, mimicking human visual sensing constraints. Unlike existing benchmarks that are bottlenecked by rendering human-like observations directly using a camera input, Nocturne uses efficient intersection methods to compute a vectorized set of visible features in a C++ back-end, allowing the simulator to run at $2000+$ steps-per-second. Using open-source trajectory and map data, we construct a simulator to load and replay arbitrary trajectories and scenes from real-world driving data. Using this environment, we benchmark reinforcement-learning and imitation-learning agents and demonstrate that the agents are quite far from human-level coordination ability and deviate significantly from the expert trajectories.
Meta Optimal Transport
Jun 10, 2022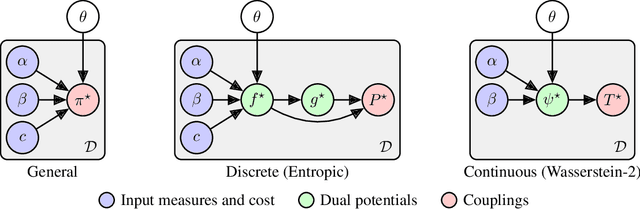


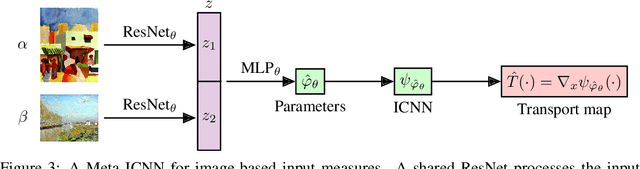
We study the use of amortized optimization to predict optimal transport (OT) maps from the input measures, which we call Meta OT. This helps repeatedly solve similar OT problems between different measures by leveraging the knowledge and information present from past problems to rapidly predict and solve new problems. Otherwise, standard methods ignore the knowledge of the past solutions and suboptimally re-solve each problem from scratch. Meta OT models surpass the standard convergence rates of log-Sinkhorn solvers in the discrete setting and convex potentials in the continuous setting. We improve the computational time of standard OT solvers by multiple orders of magnitude in discrete and continuous transport settings between images, spherical data, and color palettes. Our source code is available at http://github.com/facebookresearch/meta-ot.
Semi-Discrete Normalizing Flows through Differentiable Tessellation
Mar 14, 2022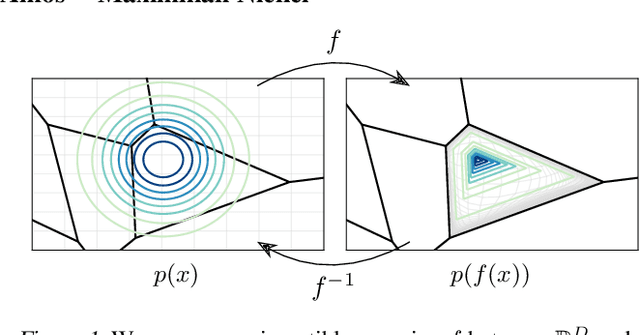
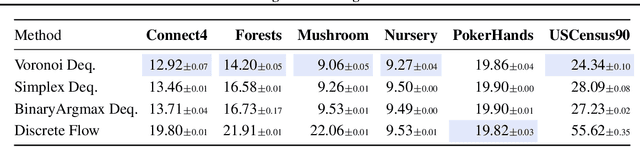
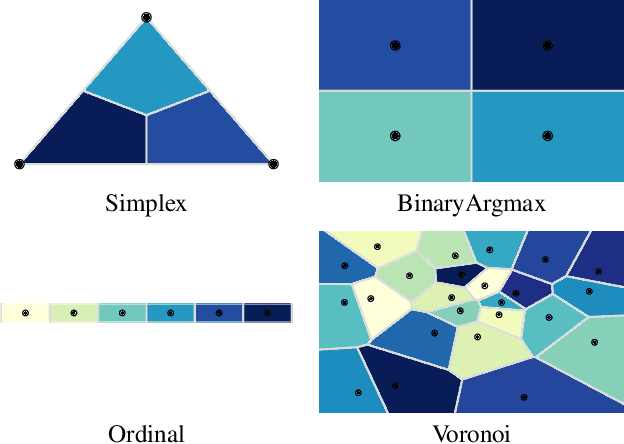

Mapping between discrete and continuous distributions is a difficult task and many have had to resort to approximate or heuristical approaches. We propose a tessellation-based approach that directly learns quantization boundaries on a continuous space, complete with exact likelihood evaluations. This is done through constructing normalizing flows on convex polytopes parameterized through a differentiable Voronoi tessellation. Using a simple homeomorphism with an efficient log determinant Jacobian, we can then cheaply parameterize distributions on convex polytopes. We explore this approach in two application settings, mapping from discrete to continuous and vice versa. Firstly, a Voronoi dequantization allows automatically learning quantization boundaries in a multidimensional space. The location of boundaries and distances between regions can encode useful structural relations between the quantized discrete values. Secondly, a Voronoi mixture model has constant computation cost for likelihood evaluation regardless of the number of mixture components. Empirically, we show improvements over existing methods across a range of structured data modalities, and find that we can achieve a significant gain from just adding Voronoi mixtures to a baseline model.
Tutorial on amortized optimization for learning to optimize over continuous domains
Feb 01, 2022Optimization is a ubiquitous modeling tool that is often deployed in settings that repeatedly solve similar instances of the same problem. Amortized optimization methods use learning to predict the solutions to problems in these settings. This leverages the shared structure between similar problem instances. In this tutorial, we will discuss the key design choices behind amortized optimization, roughly categorizing 1) models into fully-amortized and semi-amortized approaches, and 2) learning methods into regression-based and objective-based. We then view existing applications through these foundations to draw connections between them, including for manifold optimization, variational inference, sparse coding, meta-learning, control, reinforcement learning, convex optimization, and deep equilibrium networks. This framing enables us easily see, for example, that the amortized inference in variational autoencoders is conceptually identical to value gradients in control and reinforcement learning as they both use fully-amortized models with a objective-based loss. The source code for this tutorial is available at https://www.github.com/facebookresearch/amortized-optimization-tutorial
Input Convex Gradient Networks
Nov 23, 2021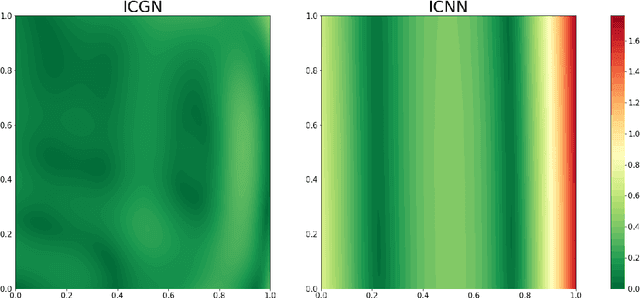
The gradients of convex functions are expressive models of non-trivial vector fields. For example, Brenier's theorem yields that the optimal transport map between any two measures on Euclidean space under the squared distance is realized as a convex gradient, which is a key insight used in recent generative flow models. In this paper, we study how to model convex gradients by integrating a Jacobian-vector product parameterized by a neural network, which we call the Input Convex Gradient Network (ICGN). We theoretically study ICGNs and compare them to taking the gradient of an Input-Convex Neural Network (ICNN), empirically demonstrating that a single layer ICGN can fit a toy example better than a single layer ICNN. Lastly, we explore extensions to deeper networks and connections to constructions from Riemannian geometry.
Cross-Domain Imitation Learning via Optimal Transport
Oct 14, 2021
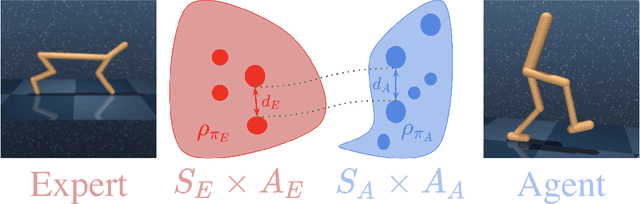
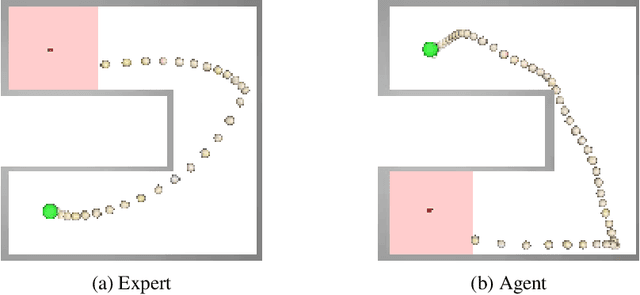

Cross-domain imitation learning studies how to leverage expert demonstrations of one agent to train an imitation agent with a different embodiment or morphology. Comparing trajectories and stationary distributions between the expert and imitation agents is challenging because they live on different systems that may not even have the same dimensionality. We propose Gromov-Wasserstein Imitation Learning (GWIL), a method for cross-domain imitation that uses the Gromov-Wasserstein distance to align and compare states between the different spaces of the agents. Our theory formally characterizes the scenarios where GWIL preserves optimality, revealing its possibilities and limitations. We demonstrate the effectiveness of GWIL in non-trivial continuous control domains ranging from simple rigid transformation of the expert domain to arbitrary transformation of the state-action space.
Scalable Online Planning via Reinforcement Learning Fine-Tuning
Sep 30, 2021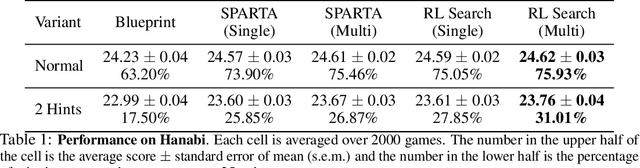
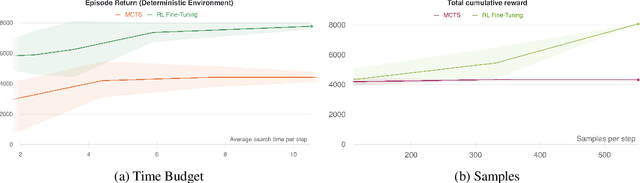


Lookahead search has been a critical component of recent AI successes, such as in the games of chess, go, and poker. However, the search methods used in these games, and in many other settings, are tabular. Tabular search methods do not scale well with the size of the search space, and this problem is exacerbated by stochasticity and partial observability. In this work we replace tabular search with online model-based fine-tuning of a policy neural network via reinforcement learning, and show that this approach outperforms state-of-the-art search algorithms in benchmark settings. In particular, we use our search algorithm to achieve a new state-of-the-art result in self-play Hanabi, and show the generality of our algorithm by also showing that it outperforms tabular search in the Atari game Ms. Pacman.
Neural Fixed-Point Acceleration for Convex Optimization
Jul 23, 2021

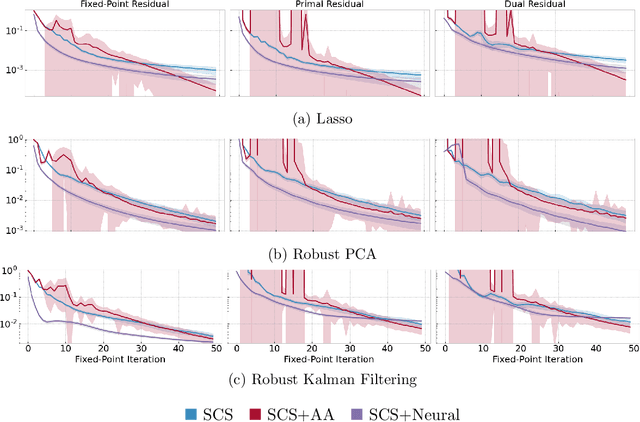

Fixed-point iterations are at the heart of numerical computing and are often a computational bottleneck in real-time applications that typically need a fast solution of moderate accuracy. We present neural fixed-point acceleration which combines ideas from meta-learning and classical acceleration methods to automatically learn to accelerate fixed-point problems that are drawn from a distribution. We apply our framework to SCS, the state-of-the-art solver for convex cone programming, and design models and loss functions to overcome the challenges of learning over unrolled optimization and acceleration instabilities. Our work brings neural acceleration into any optimization problem expressible with CVXPY. The source code behind this paper is available at https://github.com/facebookresearch/neural-scs
Riemannian Convex Potential Maps
Jun 18, 2021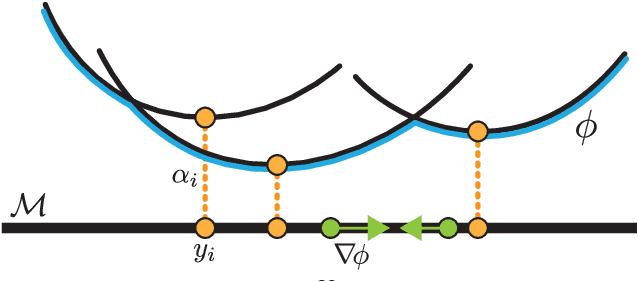



Modeling distributions on Riemannian manifolds is a crucial component in understanding non-Euclidean data that arises, e.g., in physics and geology. The budding approaches in this space are limited by representational and computational tradeoffs. We propose and study a class of flows that uses convex potentials from Riemannian optimal transport. These are universal and can model distributions on any compact Riemannian manifold without requiring domain knowledge of the manifold to be integrated into the architecture. We demonstrate that these flows can model standard distributions on spheres, and tori, on synthetic and geological data. Our source code is freely available online at http://github.com/facebookresearch/rcpm