 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Preferences: Learning Alignment Principles Grounded in Human Reasons and Values
Jan 26, 2026A crucial consideration when developing and deploying Large Language Models (LLMs) is the human values to which these models are aligned. In the constitutional framework of alignment models are aligned to a set of principles (the constitution) specified in natural language. However, it is unclear how to fairly determine this constitution with widespread stakeholder input. In this work we propose Grounded Constitutional AI (GCAI), a unified framework for generating constitutions of principles that are representative of both users' general expectations toward AI (general principles) and their interaction-time preferences (contextual principles). We extend the Inverse Constitutional AI (ICAI) approach to generate contextual principles from human preference annotation data by leveraging human-provided \textit{reasons} for their preferences. We supplement these contextual principles with general principles surfaced from user statements of \textit{values} regarding AI. We show that a constitution generated by GCAI is preferred by humans over one generated through ICAI both personally, and for widespread use in governing AI behavior. Additionally participants consider the GCAI constitution to be more morally grounded, coherent, and pluralistic.
Reflect: Transparent Principle-Guided Reasoning for Constitutional Alignment at Scale
Jan 26, 2026The constitutional framework of alignment aims to align large language models (LLMs) with value-laden principles written in natural language (such as to avoid using biased language). Prior work has focused on parameter fine-tuning techniques, such as reinforcement learning from human feedback (RLHF), to instill these principles. However, these approaches are computationally demanding, require careful engineering and tuning, and often require difficult-to-obtain human annotation data. We propose \textsc{reflect}, an inference-time framework for constitutional alignment that does not require any training or data, providing a plug-and-play approach for aligning an instruction-tuned model to a set of principles. \textsc{reflect} operates entirely in-context, combining a (i) constitution-conditioned base response with post-generation (ii) self-evaluation, (iii)(a) self-critique, and (iii)(b) final revision. \textsc{reflect}'s technique of explicit in-context reasoning over principles during post-generation outperforms standard few-shot prompting and provides transparent reasoning traces. Our results demonstrate that \textsc{reflect} significantly improves LLM conformance to diverse and complex principles, including principles quite distinct from those emphasized in the model's original parameter fine-tuning, without sacrificing factual reasoning. \textsc{reflect} is particularly effective at reducing the rate of rare but significant violations of principles, thereby improving safety and robustness in the tail end of the distribution of generations. Finally, we show that \textsc{reflect} naturally generates useful training data for traditional parameter fine-tuning techniques, allowing for efficient scaling and the reduction of inference-time computational overhead in long-term deployment scenarios.
Nonlinear Multi-objective Reinforcement Learning with Provable Guarantees
Nov 05, 2023


We describe RA-E3 (Reward-Aware Explicit Explore or Exploit), an algorithm with provable guarantees for solving a single or multi-objective Markov Decision Process (MDP) where we want to maximize the expected value of a nonlinear function over accumulated rewards. This allows us to model fairness-aware welfare optimization for multi-objective reinforcement learning as well as risk-aware reinforcement learning with nonlinear Von Neumann-Morgenstern utility functions in the single objective setting. RA-E3 extends the classic E3 algorithm that solves MDPs with scalar rewards and linear preferences. We first state a distinct reward-aware version of value iteration that calculates a non-stationary policy that is approximately optimal for a given model of the environment. This sub-procedure is based on an extended form of Bellman optimality for nonlinear optimization that explicitly considers time and current accumulated reward. We then describe how to use this optimization procedure in a larger algorithm that must simultaneously learn a model of the environment. The algorithm learns an approximately optimal policy in time that depends polynomially on the MDP size, desired approximation, and smoothness of the nonlinear function, and exponentially on the number of objectives.
Do Not Harm Protected Groups in Debiasing Language Representation Models
Oct 27, 2023Language Representation Models (LRMs) trained with real-world data may capture and exacerbate undesired bias and cause unfair treatment of people in various demographic groups. Several techniques have been investigated for applying interventions to LRMs to remove bias in benchmark evaluations on, for example, word embeddings. However, the negative side effects of debiasing interventions are usually not revealed in the downstream tasks. We propose xGAP-DEBIAS, a set of evaluations on assessing the fairness of debiasing. In this work, We examine four debiasing techniques on a real-world text classification task and show that reducing biasing is at the cost of degrading performance for all demographic groups, including those the debiasing techniques aim to protect. We advocate that a debiasing technique should have good downstream performance with the constraint of ensuring no harm to the protected group.
Welfare and Fairness in Multi-objective Reinforcement Learning
Dec 08, 2022



We study fair multi-objective reinforcement learning in which an agent must learn a policy that simultaneously achieves high reward on multiple dimensions of a vector-valued reward. Motivated by the fair resource allocation literature, we model this as an expected welfare maximization problem, for some non-linear fair welfare function of the vector of long-term cumulative rewards. One canonical example of such a function is the Nash Social Welfare, or geometric mean, the log transform of which is also known as the Proportional Fairness objective. We show that even approximately optimal optimization of the expected Nash Social Welfare is computationally intractable even in the tabular case. Nevertheless, we provide a novel adaptation of Q-learning that combines non-linear scalarized learning updates and non-stationary action selection to learn effective policies for optimizing nonlinear welfare functions. We show that our algorithm is provably convergent, and we demonstrate experimentally that our approach outperforms techniques based on linear scalarization, mixtures of optimal linear scalarizations, or stationary action selection for the Nash Social Welfare Objective.
Proportionally Fair Clustering
May 10, 2019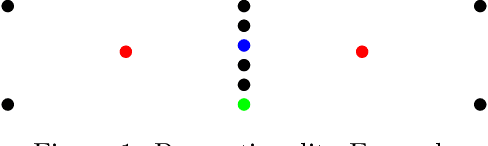
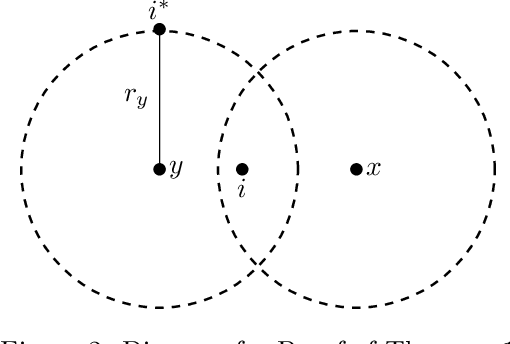
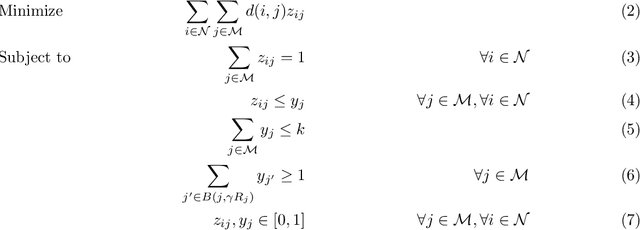
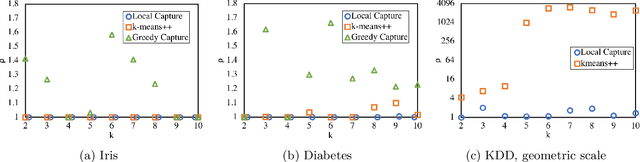
We extend the fair machine learning literature by considering the problem of proportional centroid clustering in a metric context. For clustering $n$ points with $k$ centers, we define fairness as proportionality to mean that any $n/k$ points are entitled to form their own cluster if there is another center that is closer in distance for all $n/k$ points. We seek clustering solutions to which there are no such justified complaints from any subsets of agents, without assuming any a priori notion of protected subsets. We present and analyze algorithms to efficiently compute, optimize, and audit proportional solutions. We conclude with an empirical examination of the tradeoff between proportional solutions and the $k$-means objective.
Random Dictators with a Random Referee: Constant Sample Complexity Mechanisms for Social Choice
Nov 13, 2018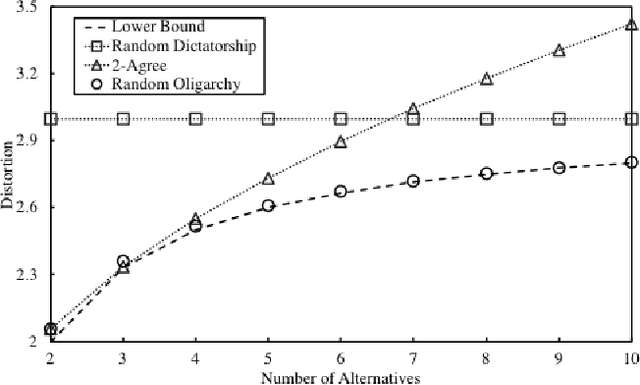
We study social choice mechanisms in an implicit utilitarian framework with a metric constraint, where the goal is to minimize \textit{Distortion}, the worst case social cost of an ordinal mechanism relative to underlying cardinal utilities. We consider two additional desiderata: Constant sample complexity and Squared Distortion. Constant sample complexity means that the mechanism (potentially randomized) only uses a constant number of ordinal queries regardless of the number of voters and alternatives. Squared Distortion is a measure of variance of the Distortion of a randomized mechanism. Our primary contribution is the first social choice mechanism with constant sample complexity \textit{and} constant Squared Distortion (which also implies constant Distortion). We call the mechanism Random Referee, because it uses a random agent to compare two alternatives that are the favorites of two other random agents. We prove that the use of a comparison query is necessary: no mechanism that only elicits the top-k preferred alternatives of voters (for constant k) can have Squared Distortion that is sublinear in the number of alternatives. We also prove that unlike any top-k only mechanism, the Distortion of Random Referee meaningfully improves on benign metric spaces, using the Euclidean plane as a canonical example. Finally, among top-1 only mechanisms, we introduce Random Oligarchy. The mechanism asks just 3 queries and is essentially optimal among the class of such mechanisms with respect to Distortion. In summary, we demonstrate the surprising power of constant sample complexity mechanisms generally, and just three random voters in particular, to provide some of the best known results in the implicit utilitarian framework.