 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Context-Aware Recommender Systems With Users in Mind
Jul 30, 2020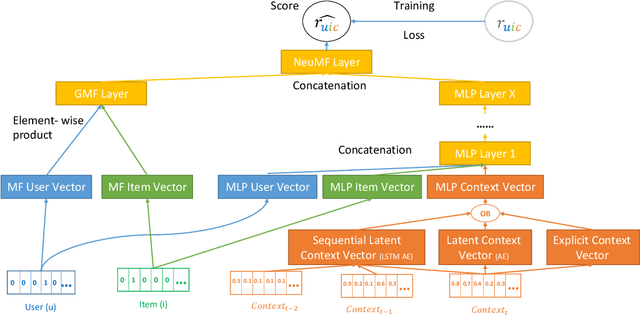

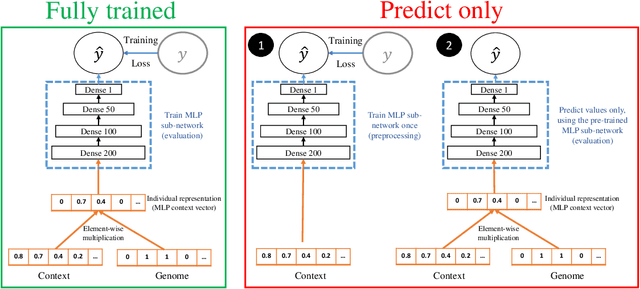
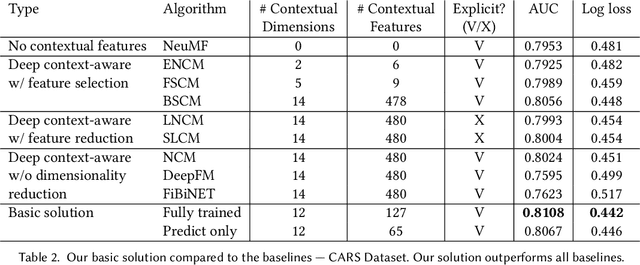
A context-aware recommender system (CARS) applies sensing and analysis of user context to provide personalized services. The contextual information can be driven from sensors in order to improve the accuracy of the recommendations. Yet, generating accurate recommendations is not enough to constitute a useful system from the users' perspective, since certain contextual information may cause different issues, such as draining the user's battery, privacy issues, and more. Adding high-dimensional contextual information may increase both the dimensionality and sparsity of the model. Previous studies suggest reducing the amount of contextual information by selecting the most suitable contextual information using a domain knowledge. Another solution is compressing it into a denser latent space, thus disrupting the ability to explain the recommendation item to the user, and damaging users' trust. In this paper we present an approach for selecting low-dimensional subsets of the contextual information and incorporating them explicitly within CARS. Specifically, we present a novel feature-selection algorithm, based on genetic algorithms (GA), that outperforms SOTA dimensional-reduction CARS algorithms, improves the accuracy and the explainability of the recommendations, and allows for controlling user aspects, such as privacy and battery consumption. Furthermore, we exploit the top subsets that are generated along the evolutionary process, by learning multiple deep context-aware models and applying a stacking technique on them, thus improving the accuracy while remaining at the explicit space. We evaluated our approach on two high-dimensional context-aware datasets driven from smartphones. An empirical analysis of our results validates that our proposed approach outperforms SOTA CARS models while improving transparency and explainability to the user.
A framework for optimizing COVID-19 testing policy using a Multi Armed Bandit approach
Jul 28, 2020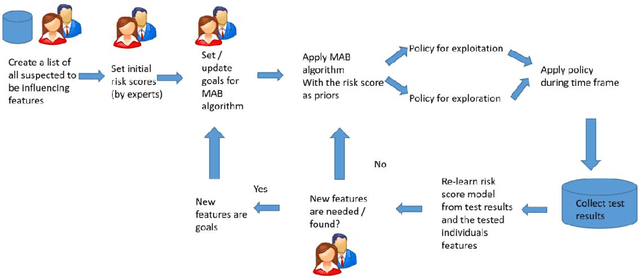
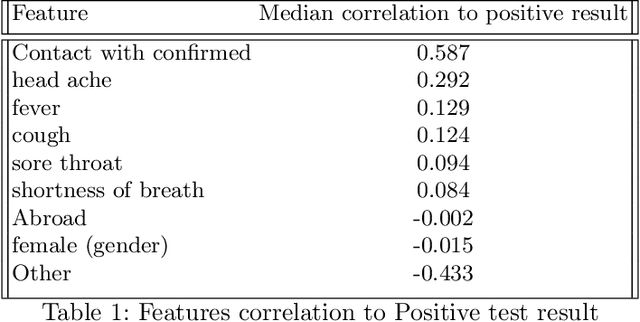
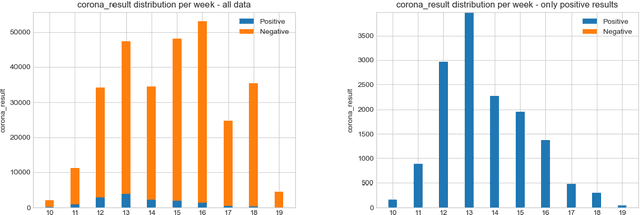
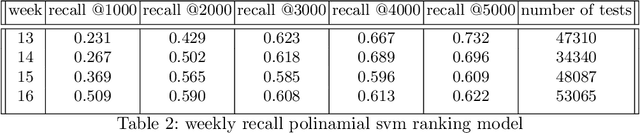
Testing is an important part of tackling the COVID-19 pandemic. Availability of testing is a bottleneck due to constrained resources and effective prioritization of individuals is necessary. Here, we discuss the impact of different prioritization policies on COVID-19 patient discovery and the ability of governments and health organizations to use the results for effective decision making. We suggest a framework for testing that balances the maximal discovery of positive individuals with the need for population-based surveillance aimed at understanding disease spread and characteristics. This framework draws from similar approaches to prioritization in the domain of cyber-security based on ranking individuals using a risk score and then reserving a portion of the capacity for random sampling. This approach is an application of Multi-Armed-Bandits maximizing exploration/exploitation of the underlying distribution. We find that individuals can be ranked for effective testing using a few simple features, and that ranking them using such models we can capture 65% (CI: 64.7%-68.3%) of the positive individuals using less than 20% of the testing capacity or 92.1% (CI: 91.1%-93.2%) of positives individuals using 70% of the capacity, allowing reserving a significant portion of the tests for population studies. Our approach allows experts and decision-makers to tailor the resulting policies as needed allowing transparency into the ranking policy and the ability to understand the disease spread in the population and react quickly and in an informed manner.
Iterative Boosting Deep Neural Networks for Predicting Click-Through Rate
Jul 26, 2020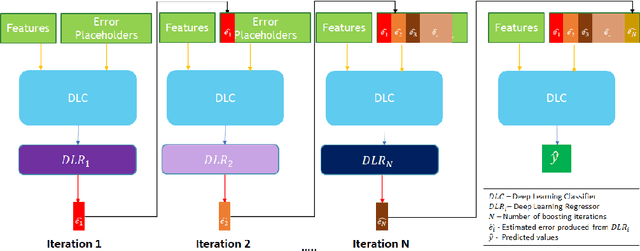


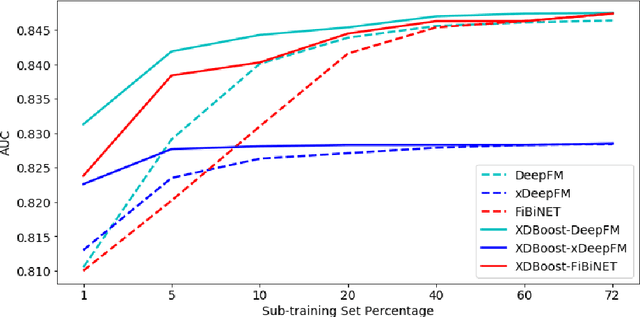
The click-through rate (CTR) reflects the ratio of clicks on a specific item to its total number of views. It has significant impact on websites' advertising revenue. Learning sophisticated models to understand and predict user behavior is essential for maximizing the CTR in recommendation systems. Recent works have suggested new methods that replace the expensive and time-consuming feature engineering process with a variety of deep learning (DL) classifiers capable of capturing complicated patterns from raw data; these methods have shown significant improvement on the CTR prediction task. While DL techniques can learn intricate user behavior patterns, it relies on a vast amount of data and does not perform as well when there is a limited amount of data. We propose XDBoost, a new DL method for capturing complex patterns that requires just a limited amount of raw data. XDBoost is an iterative three-stage neural network model influenced by the traditional machine learning boosting mechanism. XDBoost's components operate sequentially similar to boosting; However, unlike conventional boosting, XDBoost does not sum the predictions generated by its components. Instead, it utilizes these predictions as new artificial features and enhances CTR prediction by retraining the model using these features. Comprehensive experiments conducted to illustrate the effectiveness of XDBoost on two datasets demonstrated its ability to outperform existing state-of-the-art (SOTA) models for CTR prediction.
Automatic Machine Learning Derived from Scholarly Big Data
Mar 06, 2020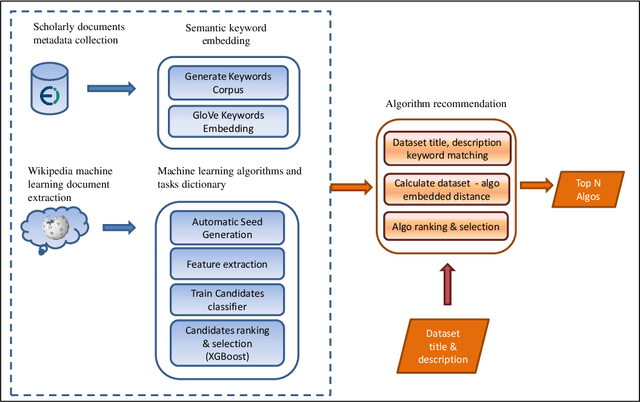
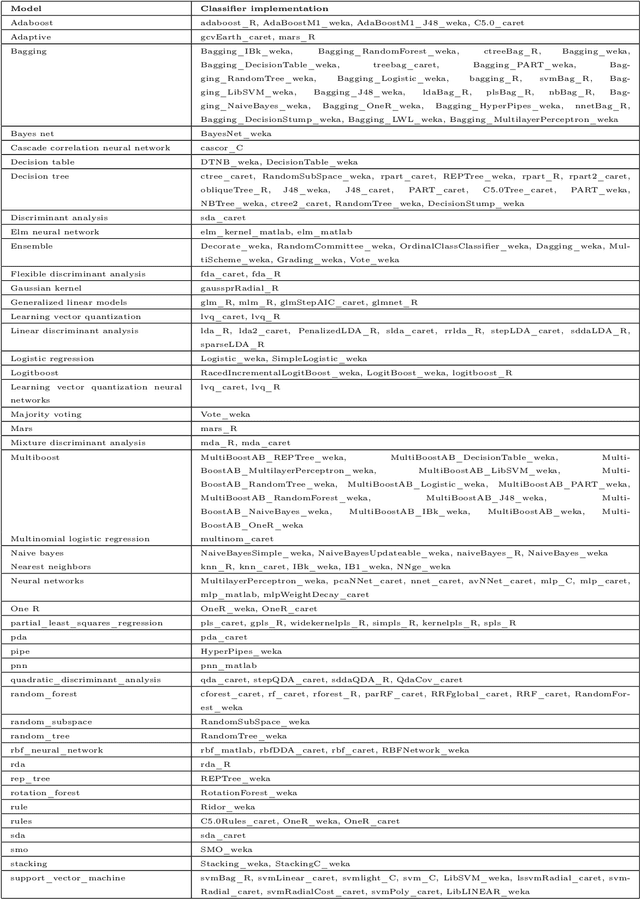
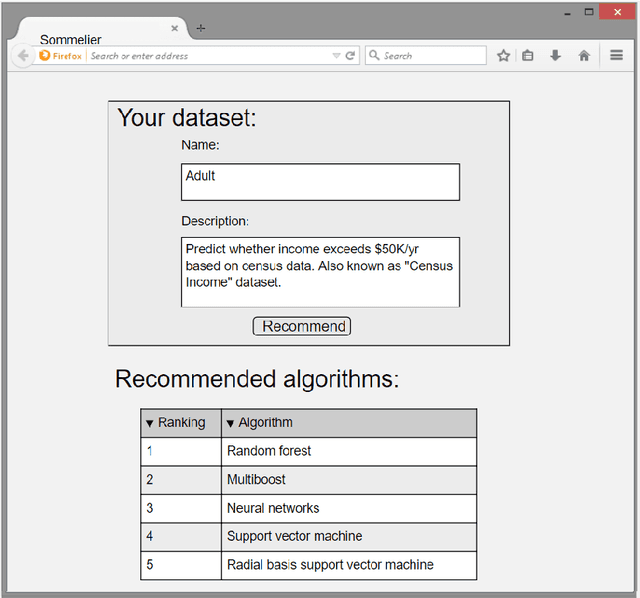

One of the challenging aspects of applying machine learning is the need to identify the algorithms that will perform best for a given dataset. This process can be difficult, time consuming and often requires a great deal of domain knowledge. We present Sommelier, an expert system for recommending the machine learning algorithms that should be applied on a previously unseen dataset. Sommelier is based on word embedding representations of the domain knowledge extracted from a large corpus of academic publications. When presented with a new dataset and its problem description, Sommelier leverages a recommendation model trained on the word embedding representation to provide a ranked list of the most relevant algorithms to be used on the dataset. We demonstrate Sommelier's effectiveness by conducting an extensive evaluation on 121 publicly available datasets and 53 classification algorithms. The top algorithms recommended for each dataset by Sommelier were able to achieve on average 97.7% of the optimal accuracy of all surveyed algorithms.
Sequence Preserving Network Traffic Generation
Feb 23, 2020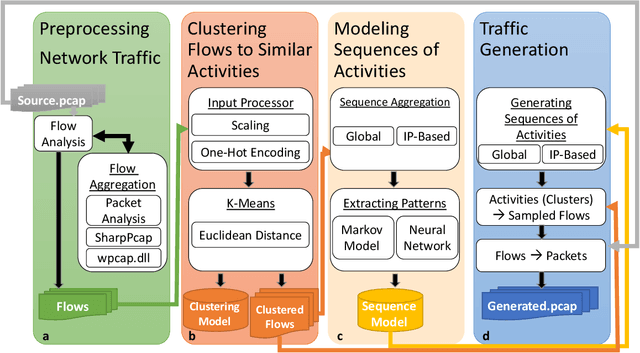


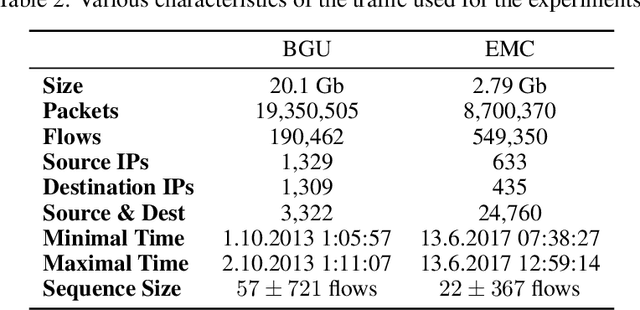
We present the Network Traffic Generator (NTG), a framework for perturbing recorded network traffic with the purpose of generating diverse but realistic background traffic for network simulation and what-if analysis in enterprise environments. The framework preserves many characteristics of the original traffic recorded in an enterprise, as well as sequences of network activities. Using the proposed framework, the original traffic flows are profiled using 200 cross-protocol features. The traffic is aggregated into flows of packets between IP pairs and clustered into groups of similar network activities. Sequences of network activities are then extracted. We examined two methods for extracting sequences of activities: a Markov model and a neural language model. Finally, new traffic is generated using the extracted model. We developed a prototype of the framework and conducted extensive experiments based on two real network traffic collections. Hypothesis testing was used to examine the difference between the distribution of original and generated features, showing that 30-100\% of the extracted features were preserved. Small differences between n-gram perplexities in sequences of network activities in the original and generated traffic, indicate that sequences of network activities were well preserved.
Diversifying Database Activity Monitoring with Bandits
Oct 23, 2019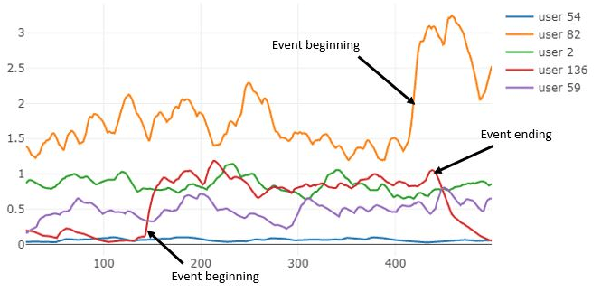
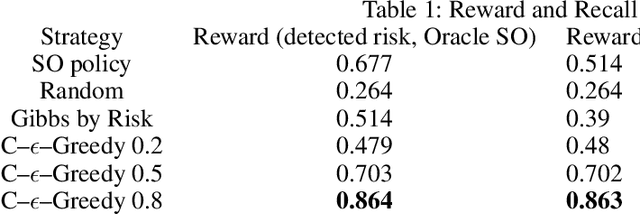
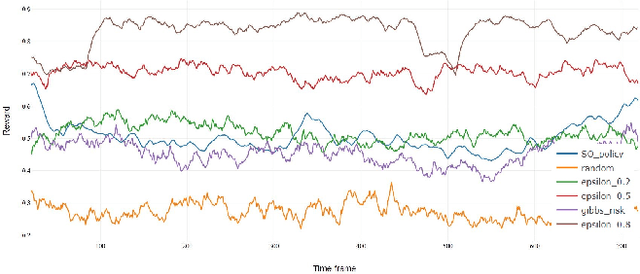
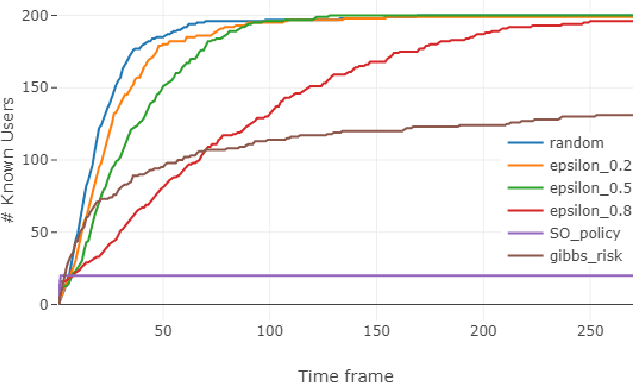
Database activity monitoring (DAM) systems are commonly used by organizations to protect the organizational data, knowledge and intellectual properties. In order to protect organizations database DAM systems have two main roles, monitoring (documenting activity) and alerting to anomalous activity. Due to high-velocity streams and operating costs, such systems are restricted to examining only a sample of the activity. Current solutions use policies, manually crafted by experts, to decide which transactions to monitor and log. This limits the diversity of the data collected. Bandit algorithms, which use reward functions as the basis for optimization while adding diversity to the recommended set, have gained increased attention in recommendation systems for improving diversity. In this work, we redefine the data sampling problem as a special case of the multi-armed bandit (MAB) problem and present a novel algorithm, which combines expert knowledge with random exploration. We analyze the effect of diversity on coverage and downstream event detection tasks using a simulated dataset. In doing so, we find that adding diversity to the sampling using the bandit-based approach works well for this task and maximizing population coverage without decreasing the quality in terms of issuing alerts about events.
Deep Context-Aware Recommender System Utilizing Sequential Latent Context
Sep 09, 2019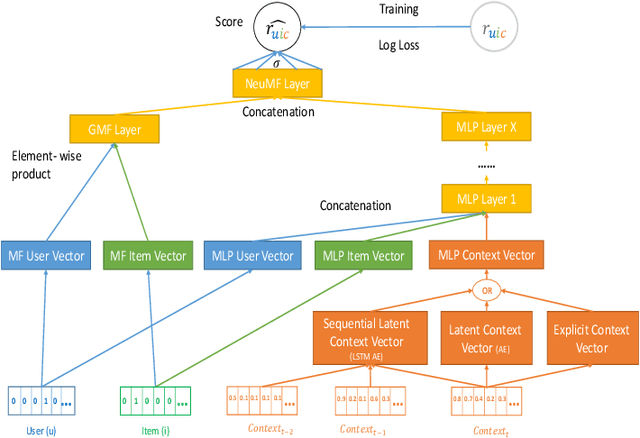

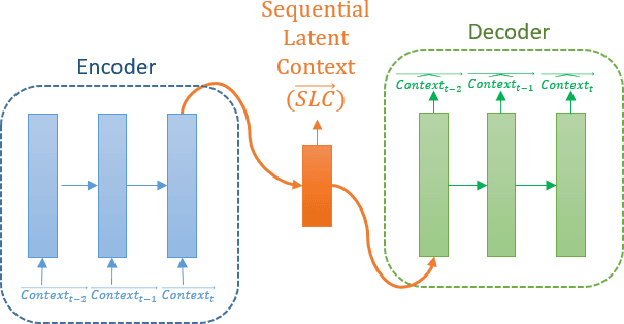
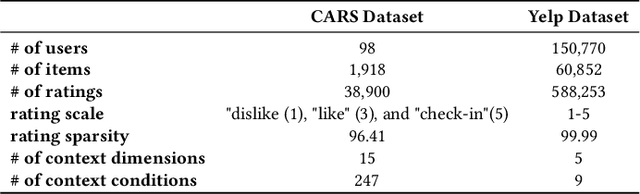
Context-aware recommender systems (CARSs) apply sensing and analysis of user context in order to provide personalized services. Adding context to a recommendation model is challenging, since the addition of context may increases both the dimensionality and sparsity of the model. Recent research has shown that modeling contextual information as a latent vector may address the sparsity and dimensionality challenges. We suggest a new latent modeling of sequential context by generating sequences of contextual information and reducing their contextual space to a compressed latent space.We train a long short-term memory (LSTM) encoder-decoder network on sequences of contextual information and extract sequential latent context from the hidden layer of the network in order to represent a compressed representation of sequential data. We propose new context-aware recommendation models that extend the neural collaborative filtering approach and learn nonlinear interactions between latent features of users, items, and contexts which take into account the sequential latent context representation as part of the recommendation process. We deployed our approach using two context-aware datasets with different context dimensions. Empirical analysis of our results validates that our proposed sequential latent context-aware model (SLCM), surpasses state of the art CARS models.
Assessing the Quality of Scientific Papers
Aug 12, 2019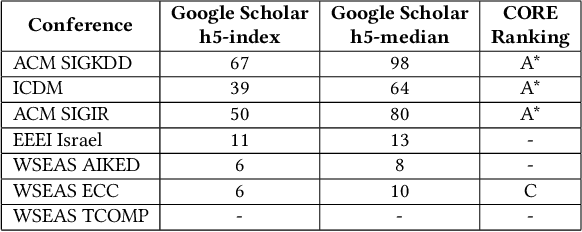
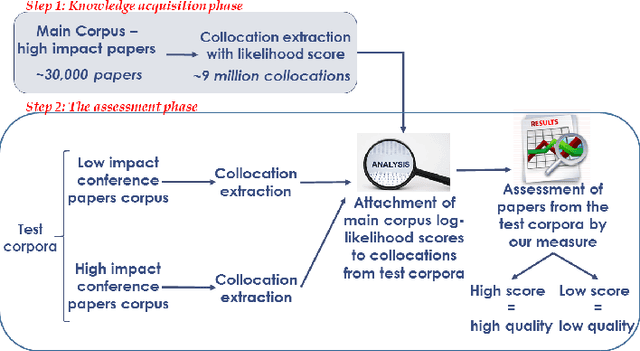

A multitude of factors are responsible for the overall quality of scientific papers, including readability, linguistic quality, fluency,semantic complexity, and of course domain-specific technical factors. These factors vary from one field of study to another. In this paper, we propose a measure and method for assessing the overall quality of the scientific papers in a particular field of study. We evaluate our method in the computer science domain, but it can be applied to other technical and scientific fields.Our method is based on the corpus linguistics technique. This technique enables the extraction of required information and knowledge associated with a specific domain. For this purpose, we have created a large corpus, consisting of papers from very high impact conferences. First, we analyze this corpus in order to extract rich domain-specific terminology and knowledge. Then we use the acquired knowledge to estimate the quality of scientific papers by applying our proposed measure. We examine our measure on high and low scientific impact test corpora. Our results show a significant difference in the measure scores of the high and low impact test corpora. Second, we develop a classifier based on our proposed measure and compare it to the baseline classifier. Our results show that the classifier based on our measure over-performed the baseline classifier. Based on the presented results the proposed measure and the technique can be used for automated assessment of scientific papers.
A difficulty ranking approach to personalization in E-learning
Jul 28, 2019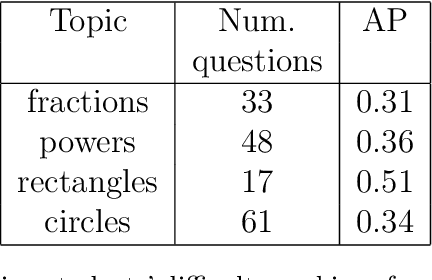

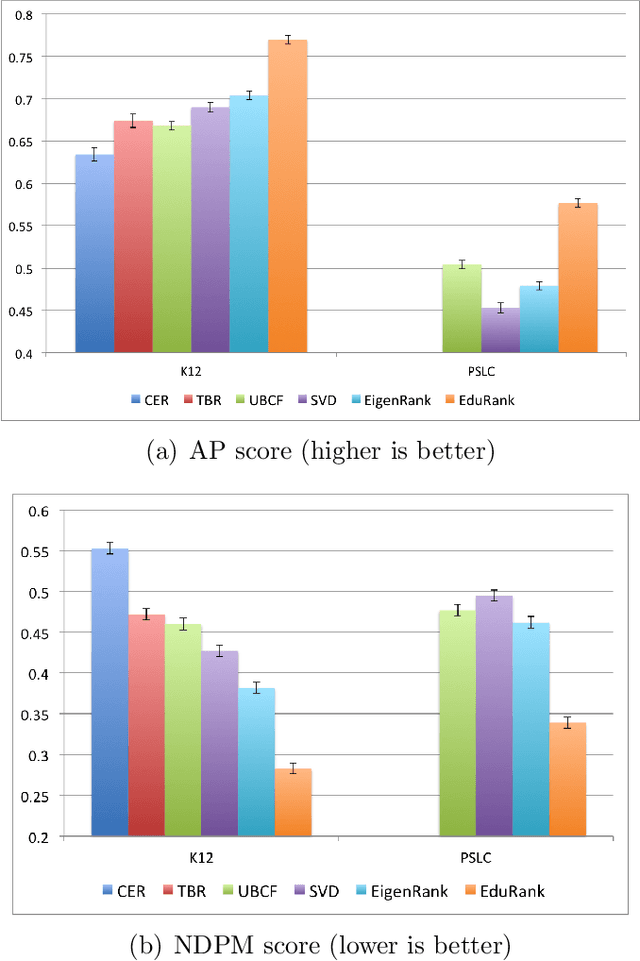
The prevalence of e-learning systems and on-line courses has made educational material widely accessible to students of varying abilities and backgrounds. There is thus a growing need to accommodate for individual differences in e-learning systems. This paper presents an algorithm called EduRank for personalizing educational content to students that combines a collaborative filtering algorithm with voting methods. EduRank constructs a difficulty ranking for each student by aggregating the rankings of similar students using different aspects of their performance on common questions. These aspects include grades, number of retries, and time spent solving questions. It infers a difficulty ranking directly over the questions for each student, rather than ordering them according to the student's predicted score. The EduRank algorithm was tested on two data sets containing thousands of students and a million records. It was able to outperform the state-of-the-art ranking approaches as well as a domain expert. EduRank was used by students in a classroom activity, where a prior model was incorporated to predict the difficulty rankings of students with no prior history in the system. It was shown to lead students to solve more difficult questions than an ordering by a domain expert, without reducing their performance.
New Item Consumption Prediction Using Deep Learning
May 12, 2019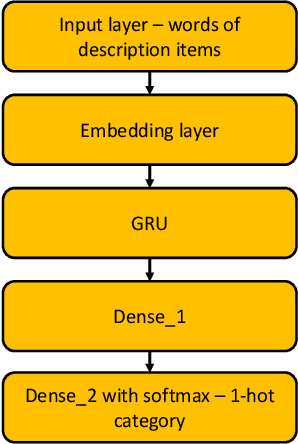
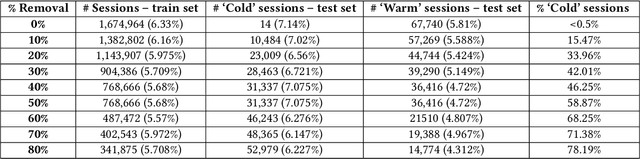
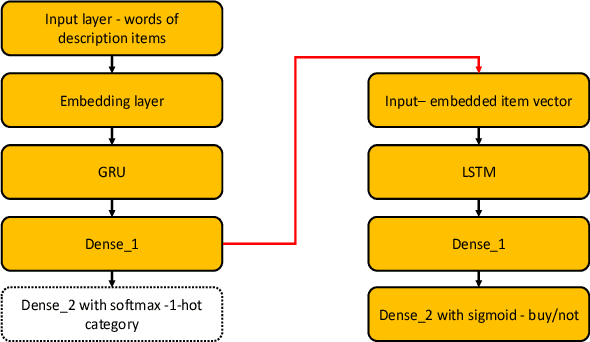
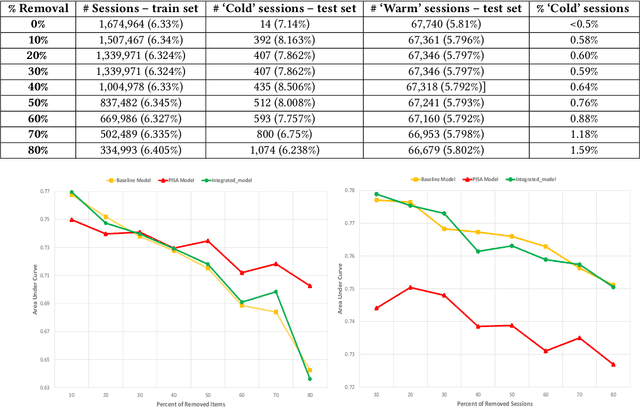
Recommendation systems have become ubiquitous in today's online world and are an integral part of practically every e-commerce platform. While traditional recommender systems use customer history, this approach is not feasible in 'cold start' scenarios. Such scenarios include the need to produce recommendations for new or unregistered users and the introduction of new items. In this study, we present the Purchase Intent Session-bAsed (PISA) algorithm, a content-based algorithm for predicting the purchase intent for cold start session-based scenarios. Our approach employs deep learning techniques both for modeling the content and purchase intent prediction. Our experiments show that PISA outperforms a well-known deep learning baseline when new items are introduced. In addition, while content-based approaches often fail to perform well in highly imbalanced datasets, our approach successfully handles such cases. Finally, our experiments show that combining PISA with the baseline in non-cold start scenarios further improves performance.