 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOtters++: A Time-to-first-spike Based Energy Efficient Optical Spiking Transformer
Jun 11, 2026Spiking neural networks (SNNs) are promising for energy-efficient inference, and time-to-first-spike (TTFS) coding is especially attractive because each neuron fires at most once. In practice, however, this benefit is often reduced by the cost of computing a temporal decay term and multiplying it by the synaptic weight. We address this issue by turning a physical hardware "bug," the natural signal decay in optoelectronic devices, into the main computation of TTFS, named Otters++. Specifically, we use the measured decay of a custom In$_2$O$_3$ optoelectronic synapse to directly realize the TTFS temporal term, removing the need for explicit digital decay computation. To scale this idea to Transformer models, we establish a layer-wise functional equivalence between the Otters++ and a quantized neural network (QNN), and develop a hybrid training method that uses device-faithful SNN computation in the forward pass and QNN straight-through gradients through the equivalent QNN path in the backward pass, together with model distillation. This avoids differentiation through discrete first-spike events and reduces the over-sparsity problem in direct TTFS-SNN training. We further make training aware of measured device noise by sampling run-to-run variation, and refine the system-level energy model by accounting for device sharing and multi-hop communication. On GLUE dataset, Otters++ improves the average score to 84.17\% while maintaining a clear energy advantage over prior spiking Transformer baselines. These results show that physically grounded TTFS computing can be efficient, trainable, and robust under realistic hardware effects.
A Lightweight MPC Bidding Framework for Brand Auction Ads
Mar 08, 2026Brand advertising plays a critical role in building long-term consumer awareness and loyalty, making it a key objective for advertisers across digital platforms. Although real-time bidding has been extensively studied, there is limited literature on algorithms specifically tailored for brand auction ads that fully leverage their unique characteristics. In this paper, we propose a lightweight Model Predictive Control (MPC) framework designed for brand advertising campaigns, exploiting the inherent attributes of brand ads -- such as stable user engagement patterns and fast feedback loops -- to simplify modeling and improve efficiency. Our approach utilizes online isotonic regression to construct monotonic bid-to-spend and bid-to-conversion models directly from streaming data, eliminating the need for complex machine learning models. The algorithm operates fully online with low computational overhead, making it highly practical for real-world deployment. Simulation results demonstrate that our approach significantly improves spend efficiency and cost control compared to baseline strategies, providing a scalable and easily implementable solution for modern brand advertising platforms.
Vision Transformer for Contrastive Clustering
Jun 26, 2022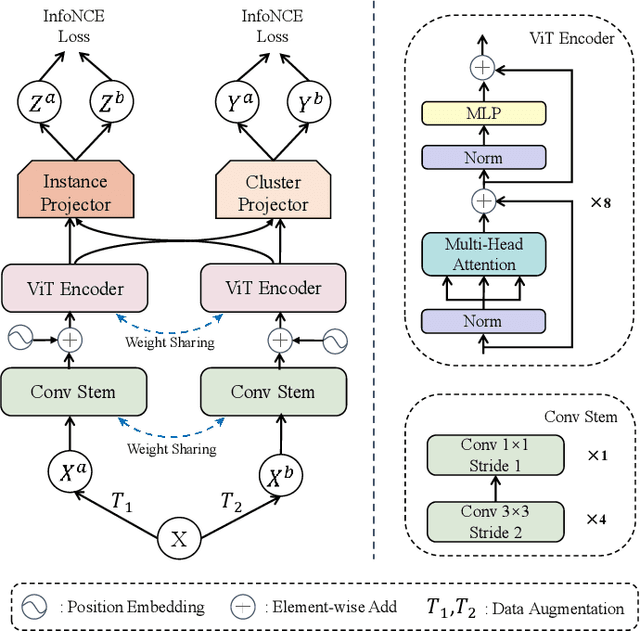

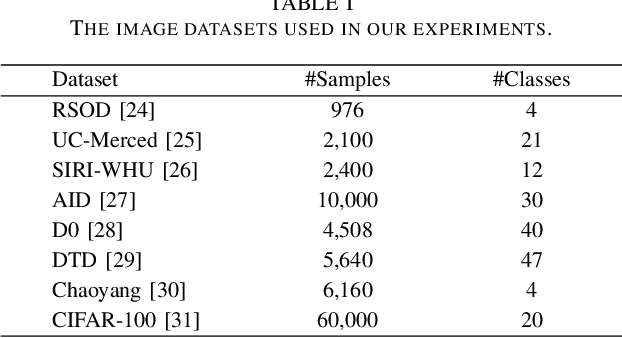
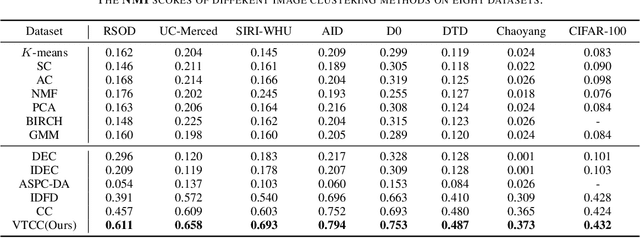
Vision Transformer (ViT) has shown its advantages over the convolutional neural network (CNN) with its ability to capture global long-range dependencies for visual representation learning. Besides ViT, contrastive learning is another popular research topic recently. While previous contrastive learning works are mostly based on CNNs, some latest studies have attempted to jointly model the ViT and the contrastive learning for enhanced self-supervised learning. Despite the considerable progress, these combinations of ViT and contrastive learning mostly focus on the instance-level contrastiveness, which often overlook the contrastiveness of the global clustering structures and also lack the ability to directly learn the clustering result (e.g., for images). In view of this, this paper presents an end-to-end deep image clustering approach termed Vision Transformer for Contrastive Clustering (VTCC), which for the first time, to the best of our knowledge, unifies the Transformer and the contrastive learning for the image clustering task. Specifically, with two random augmentations performed on each image in a mini-batch, we utilize a ViT encoder with two weight-sharing views as the backbone to learn the representations for the augmented samples. To remedy the potential instability of the ViT, we incorporate a convolutional stem, which uses multiple stacked small convolutions instead of a big convolution in the patch projection layer, to split each augmented sample into a sequence of patches. With representations learned via the backbone, an instance projector and a cluster projector are further utilized for the instance-level contrastive learning and the global clustering structure learning, respectively. Extensive experiments on eight image datasets demonstrate the stability (during the training-from-scratch) and the superiority (in clustering performance) of VTCC over the state-of-the-art.