 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-rebench V2: Language-Agnostic SWE Task Collection at Scale
Feb 27, 2026Software engineering agents (SWE) are improving rapidly, with recent gains largely driven by reinforcement learning (RL). However, RL training is constrained by the scarcity of large-scale task collections with reproducible execution environments and reliable test suites. Although a growing number of benchmarks have emerged, datasets suitable for training remain limited in scale and diversity or often target a limited set of high-resource language ecosystems. We introduce SWE-rebench V2, a language-agnostic automated pipeline for harvesting executable real-world SWE tasks and constructing RL training environments at scale. The pipeline synthesizes repository-specific installation and test procedures via an interactive setup agent, and filters unsound instances using an ensemble of LLM judges, validated against human-verified SWE-bench annotations. Using this pipeline, we construct a dataset of 32,000+ tasks spanning 20 languages and 3,600+ repositories, with pre-built images for reproducible execution. To further scale training data, we additionally release 120,000+ tasks with installation instructions, fail-to-pass tests and rich metadata, where the problem statement is generated based on the original pull request description. We validate the collected instances through a diagnostic study that covers a subset of tasks in five programming languages across seven popular models, and provide instance-level metadata that flags common confounders such as overly restrictive tests and underspecified descriptions. We release the datasets, the collection and execution code, and associated artifacts to enable large-scale training of SWE agents across diverse languages and repositories.
LK Losses: Direct Acceptance Rate Optimization for Speculative Decoding
Feb 27, 2026Speculative decoding accelerates autoregressive large language model (LLM) inference by using a lightweight draft model to propose candidate tokens that are then verified in parallel by the target model. The speedup is significantly determined by the acceptance rate, yet standard training minimizes Kullback-Leibler (KL) divergence as a proxy objective. While KL divergence and acceptance rate share the same global optimum, small draft models, having limited capacity, typically converge to suboptimal solutions where minimizing KL does not guarantee maximizing acceptance rate. To address this issue, we propose LK losses, special training objectives that directly target acceptance rate. Comprehensive experiments across four draft architectures and six target models, ranging from 8B to 685B parameters, demonstrate consistent improvements in acceptance metrics across all configurations compared to the standard KL-based training. We evaluate our approach on general, coding and math domains and report gains of up to 8-10% in average acceptance length. LK losses are easy to implement, introduce no computational overhead and can be directly integrated into any existing speculator training framework, making them a compelling alternative to the existing draft training objectives.
Blockwise Advantage Estimation for Multi-Objective RL with Verifiable Rewards
Feb 10, 2026Group Relative Policy Optimization (GRPO) assigns a single scalar advantage to all tokens in a completion. For structured generations with explicit segments and objectives, this couples unrelated reward signals across segments, leading to objective interference and misattributed credit. We propose Blockwise Advantage Estimation, a family of GRPO-compatible methods that assigns each objective its own advantage and applies it only to the tokens in the corresponding text block, reducing reliance on hand-designed scalar rewards and scaling naturally to additional objectives. A key challenge is estimating advantages for later blocks whose rewards are conditioned on sampled prefixes; standard unbiased approaches require expensive nested rollouts from intermediate states. Concretely, we introduce an Outcome-Conditioned Baseline that approximates intermediate state values using only within-group statistics by stratifying samples according to a prefix-derived intermediate outcome. On math tasks with uncertainty estimation, our method mitigates reward interference, is competitive with a state-of-the-art reward-designed approach, and preserves test-time gains from confidence-weighted ensembling. More broadly, it provides a modular recipe for optimizing sequential objectives in structured generations without additional rollouts.
SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents
May 26, 2025LLM-based agents have shown promising capabilities in a growing range of software engineering (SWE) tasks. However, advancing this field faces two critical challenges. First, high-quality training data is scarce, especially data that reflects real-world SWE scenarios, where agents must interact with development environments, execute code and adapt behavior based on the outcomes of their actions. Existing datasets are either limited to one-shot code generation or comprise small, manually curated collections of interactive tasks, lacking both scale and diversity. Second, the lack of fresh interactive SWE tasks affects evaluation of rapidly improving models, as static benchmarks quickly become outdated due to contamination issues. To address these limitations, we introduce a novel, automated, and scalable pipeline to continuously extract real-world interactive SWE tasks from diverse GitHub repositories. Using this pipeline, we construct SWE-rebench, a public dataset comprising over 21,000 interactive Python-based SWE tasks, suitable for reinforcement learning of SWE agents at scale. Additionally, we use continuous supply of fresh tasks collected using SWE-rebench methodology to build a contamination-free benchmark for agentic software engineering. We compare results of various LLMs on this benchmark to results on SWE-bench Verified and show that performance of some language models might be inflated due to contamination issues.
Guided Search Strategies in Non-Serializable Environments with Applications to Software Engineering Agents
May 19, 2025Large language models (LLMs) have recently achieved remarkable results in complex multi-step tasks, such as mathematical reasoning and agentic software engineering. However, they often struggle to maintain consistent performance across multiple solution attempts. One effective approach to narrow the gap between average-case and best-case performance is guided test-time search, which explores multiple solution paths to identify the most promising one. Unfortunately, effective search techniques (e.g. MCTS) are often unsuitable for non-serializable RL environments, such as Docker containers, where intermediate environment states cannot be easily saved and restored. We investigate two complementary search strategies applicable to such environments: 1-step lookahead and trajectory selection, both guided by a learned action-value function estimator. On the SWE-bench Verified benchmark, a key testbed for agentic software engineering, we find these methods to double the average success rate of a fine-tuned Qwen-72B model, achieving 40.8%, the new state-of-the-art for open-weights models. Additionally, we show that these techniques are transferable to more advanced closed models, yielding similar improvements with GPT-4o.
Variance Reduction for Policy-Gradient Methods via Empirical Variance Minimization
Jun 15, 2022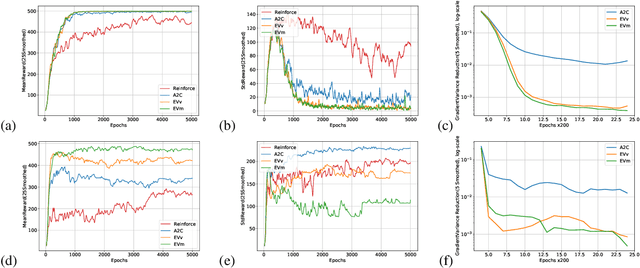
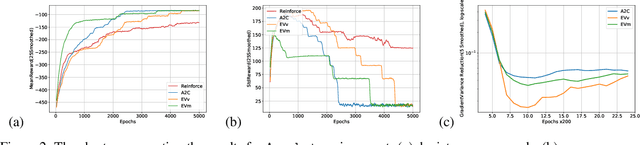
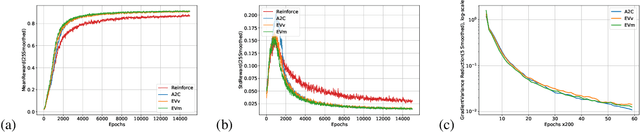
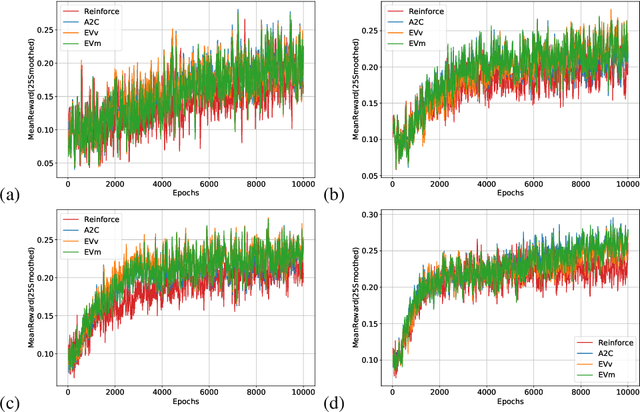
Policy-gradient methods in Reinforcement Learning(RL) are very universal and widely applied in practice but their performance suffers from the high variance of the gradient estimate. Several procedures were proposed to reduce it including actor-critic(AC) and advantage actor-critic(A2C) methods. Recently the approaches have got new perspective due to the introduction of Deep RL: both new control variates(CV) and new sub-sampling procedures became available in the setting of complex models like neural networks. The vital part of CV-based methods is the goal functional for the training of the CV, the most popular one is the least-squares criterion of A2C. Despite its practical success, the criterion is not the only one possible. In this paper we for the first time investigate the performance of the one called Empirical Variance(EV). We observe in the experiments that not only EV-criterion performs not worse than A2C but sometimes can be considerably better. Apart from that, we also prove some theoretical guarantees of the actual variance reduction under very general assumptions and show that A2C least-squares goal functional is an upper bound for EV goal. Our experiments indicate that in terms of variance reduction EV-based methods are much better than A2C and allow stronger variance reduction.