 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel and Deep Regimes in Overparametrized Models
Jun 13, 2019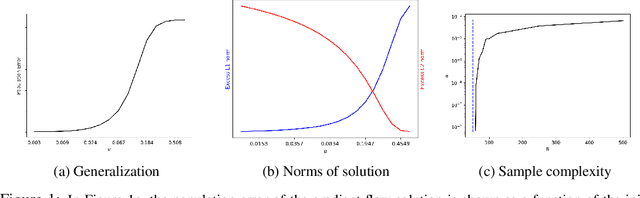
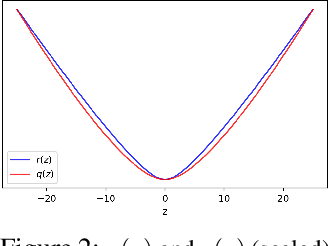
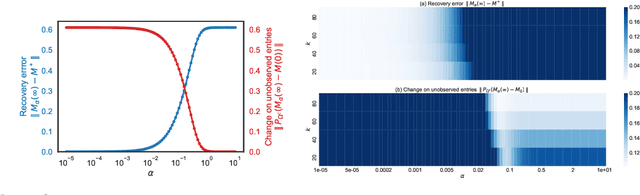
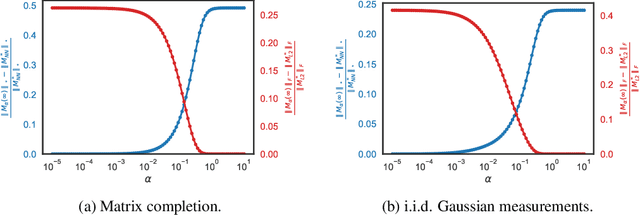
A recent line of work studies overparametrized neural networks in the ``kernel regime,'' i.e.~when the network behaves during training as a kernelized linear predictor, and thus training with gradient descent has the effect of finding the minimum RKHS norm solution. This stands in contrast to other studies which demonstrate how gradient descent on overparametrized multilayer networks can induce rich implicit biases that are not RKHS norms. Building on an observation by Chizat and Bach, we show how the scale of the initialization controls the transition between the ``kernel'' (aka lazy) and ``deep'' (aka active) regimes and affects generalization properties in multilayer homogeneous models. We provide a complete and detailed analysis for a simple two-layer model that already exhibits an interesting and meaningful transition between the kernel and deep regimes, and we demonstrate the transition for more complex matrix factorization models.
The Complexity of Making the Gradient Small in Stochastic Convex Optimization
Feb 14, 2019
We give nearly matching upper and lower bounds on the oracle complexity of finding $\epsilon$-stationary points ($\| \nabla F(x) \| \leq\epsilon$) in stochastic convex optimization. We jointly analyze the oracle complexity in both the local stochastic oracle model and the global oracle (or, statistical learning) model. This allows us to decompose the complexity of finding near-stationary points into optimization complexity and sample complexity, and reveals some surprising differences between the complexity of stochastic optimization versus learning. Notably, we show that in the global oracle/statistical learning model, only logarithmic dependence on smoothness is required to find a near-stationary point, whereas polynomial dependence on smoothness is necessary in the local stochastic oracle model. In other words, the separation in complexity between the two models can be exponential, and that the folklore understanding that smoothness is required to find stationary points is only weakly true for statistical learning. Our upper bounds are based on extensions of a recent "recursive regularization" technique proposed by Allen-Zhu (2018). We show how to extend the technique to achieve near-optimal rates, and in particular show how to leverage the extra information available in the global oracle model. Our algorithm for the global model can be implemented efficiently through finite sum methods, and suggests an interesting new computational-statistical tradeoff.
Training Well-Generalizing Classifiers for Fairness Metrics and Other Data-Dependent Constraints
Sep 28, 2018

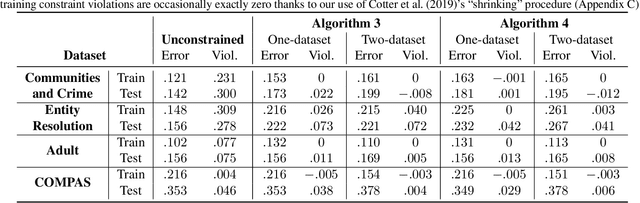
Classifiers can be trained with data-dependent constraints to satisfy fairness goals, reduce churn, achieve a targeted false positive rate, or other policy goals. We study the generalization performance for such constrained optimization problems, in terms of how well the constraints are satisfied at evaluation time, given that they are satisfied at training time. To improve generalization performance, we frame the problem as a two-player game where one player optimizes the model parameters on a training dataset, and the other player enforces the constraints on an independent validation dataset. We build on recent work in two-player constrained optimization to show that if one uses this two-dataset approach, then constraint generalization can be significantly improved. As we illustrate experimentally, this approach works not only in theory, but also in practice.
Graph Oracle Models, Lower Bounds, and Gaps for Parallel Stochastic Optimization
Jul 31, 2018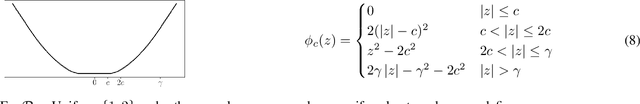
We suggest a general oracle-based framework that captures different parallel stochastic optimization settings described by a dependency graph, and derive generic lower bounds in terms of this graph. We then use the framework and derive lower bounds for several specific parallel optimization settings, including delayed updates and parallel processing with intermittent communication. We highlight gaps between lower and upper bounds on the oracle complexity, and cases where the "natural" algorithms are not known to be optimal.
The Everlasting Database: Statistical Validity at a Fair Price
Mar 12, 2018The problem of handling adaptivity in data analysis, intentional or not, permeates a variety of fields, including test-set overfitting in ML challenges and the accumulation of invalid scientific discoveries. We propose a mechanism for answering an arbitrarily long sequence of potentially adaptive statistical queries, by charging a price for each query and using the proceeds to collect additional samples. Crucially, we guarantee statistical validity without any assumptions on how the queries are generated. We also ensure with high probability that the cost for $M$ non-adaptive queries is $O(\log M)$, while the cost to a potentially adaptive user who makes $M$ queries that do not depend on any others is $O(\sqrt{M})$.
Learning Non-Discriminatory Predictors
Nov 01, 2017We consider learning a predictor which is non-discriminatory with respect to a "protected attribute" according to the notion of "equalized odds" proposed by Hardt et al. [2016]. We study the problem of learning such a non-discriminatory predictor from a finite training set, both statistically and computationally. We show that a post-hoc correction approach, as suggested by Hardt et al, can be highly suboptimal, present a nearly-optimal statistical procedure, argue that the associated computational problem is intractable, and suggest a second moment relaxation of the non-discrimination definition for which learning is tractable.
Implicit Regularization in Matrix Factorization
May 25, 2017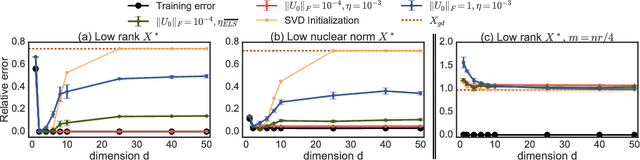
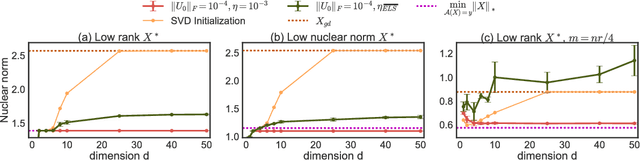


We study implicit regularization when optimizing an underdetermined quadratic objective over a matrix $X$ with gradient descent on a factorization of $X$. We conjecture and provide empirical and theoretical evidence that with small enough step sizes and initialization close enough to the origin, gradient descent on a full dimensional factorization converges to the minimum nuclear norm solution.
Tight Complexity Bounds for Optimizing Composite Objectives
Oct 27, 2016
We provide tight upper and lower bounds on the complexity of minimizing the average of $m$ convex functions using gradient and prox oracles of the component functions. We show a significant gap between the complexity of deterministic vs randomized optimization. For smooth functions, we show that accelerated gradient descent (AGD) and an accelerated variant of SVRG are optimal in the deterministic and randomized settings respectively, and that a gradient oracle is sufficient for the optimal rate. For non-smooth functions, having access to prox oracles reduces the complexity and we present optimal methods based on smoothing that improve over methods using just gradient accesses.