 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-TIDE: Fast, Structure-Preserving Motion Forecasting from Event Sequences
Mar 29, 2026Event-based cameras capture visual information as asynchronous streams of per-pixel brightness changes, generating sparse, temporally precise data. Compared to conventional frame-based sensors, they offer significant advantages in capturing high-speed dynamics while consuming substantially less power. Predicting future event representations from past observations is an important problem, enabling downstream tasks such as future semantic segmentation or object tracking without requiring access to future sensor measurements. While recent state-of-the-art approaches achieve strong performance, they often rely on computationally heavy backbones and, in some cases, large-scale pretraining, limiting their applicability in resource-constrained scenarios. In this work, we introduce E-TIDE, a lightweight, end-to-end trainable architecture for event-tensor prediction that is designed to operate efficiently without large-scale pretraining. Our approach employs the TIDE module (Temporal Interaction for Dynamic Events), motivated by efficient spatiotemporal interaction design for sparse event tensors, to capture temporal dependencies via large-kernel mixing and activity-aware gating while maintaining low computational complexity. Experiments on standard event-based datasets demonstrate that our method achieves competitive performance with significantly reduced model size and training requirements, making it well-suited for real-time deployment under tight latency and memory budgets.
Forming a sparse representation for visual place recognition using a neurorobotic approach
Sep 30, 2021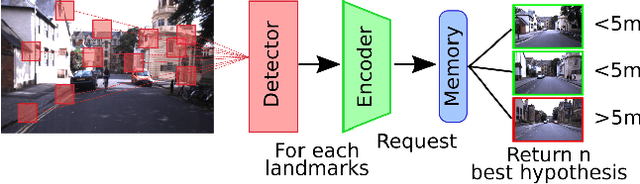
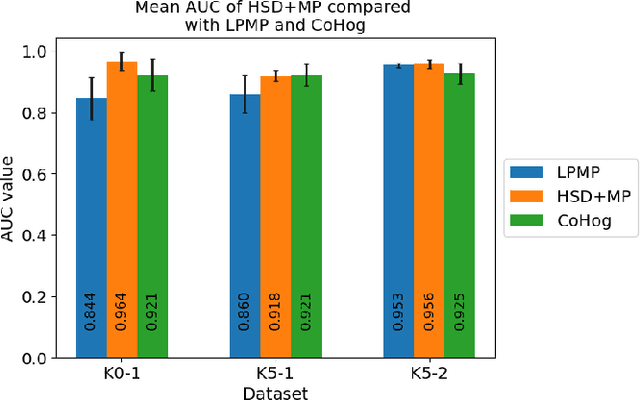
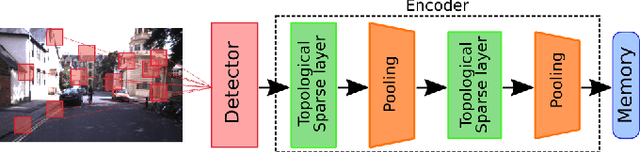
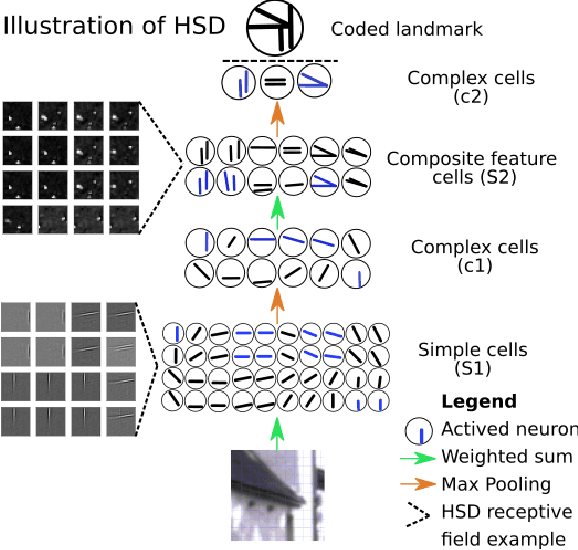
This paper introduces a novel unsupervised neural network model for visual information encoding which aims to address the problem of large-scale visual localization. Inspired by the structure of the visual cortex, the model (namely HSD) alternates layers of topologic sparse coding and pooling to build a more compact code of visual information. Intended for visual place recognition (VPR) systems that use local descriptors, the impact of its integration in a bio-inpired model for self-localization (LPMP) is evaluated. Our experimental results on the KITTI dataset show that HSD improves the runtime speed of LPMP by a factor of at least 2 and its localization accuracy by 10%. A comparison with CoHog, a state-of-the-art VPR approach, showed that our method achieves slightly better results.