 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
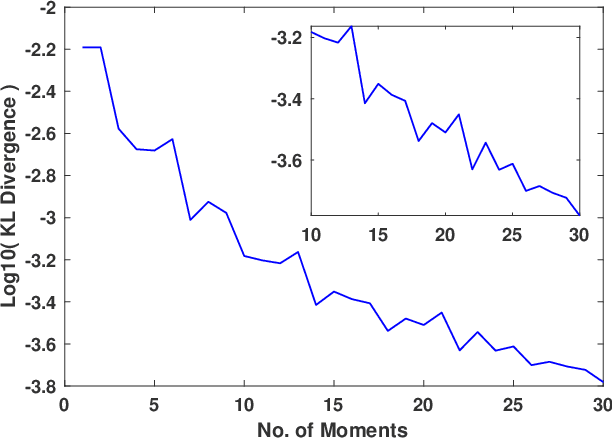
Add to EdgeMEMe: An Accurate Maximum Entropy Method for Efficient Approximations in Large-Scale Machine Learning
Jun 03, 2019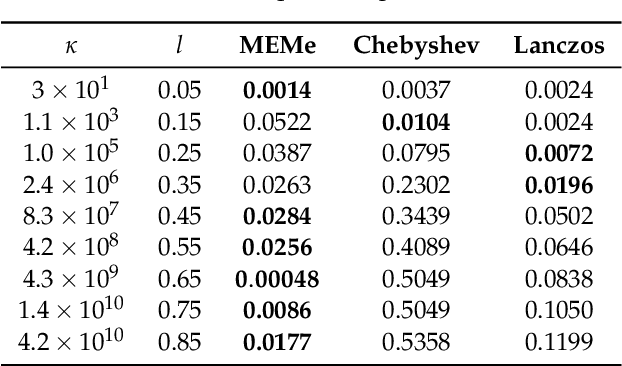
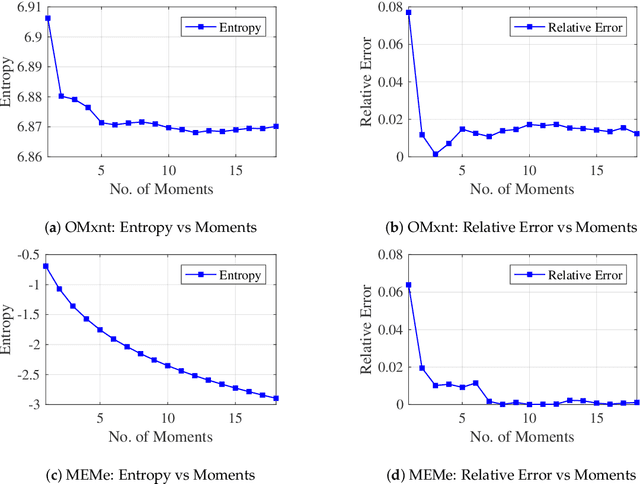
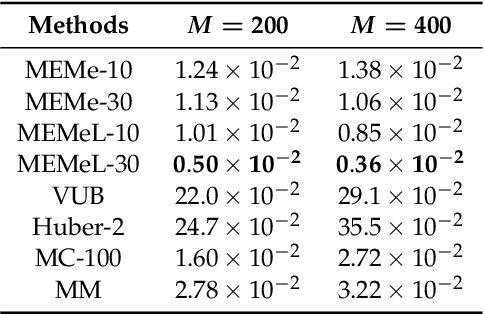
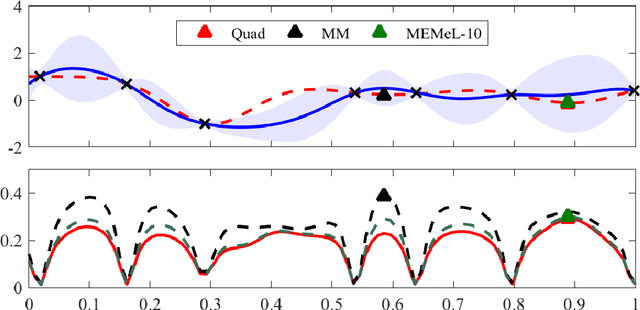
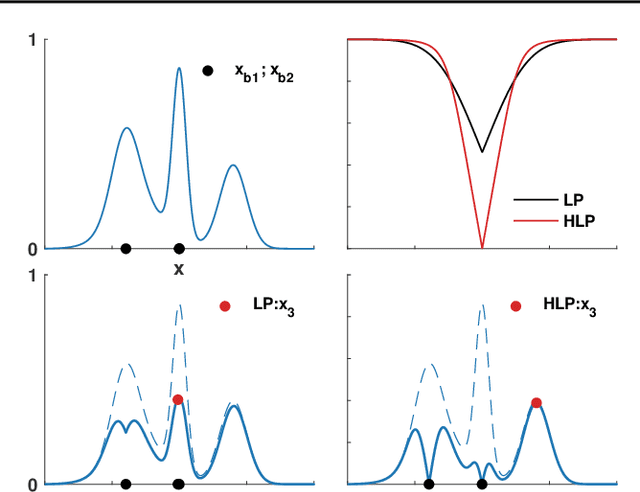
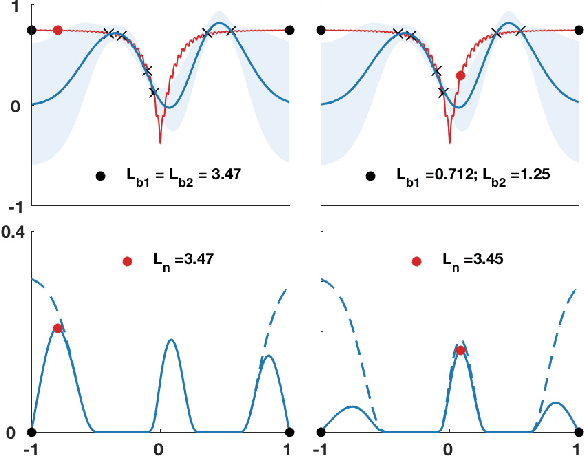
Efficient approximation lies at the heart of large-scale machine learning problems. In this paper, we propose a novel, robust maximum entropy algorithm, which is capable of dealing with hundreds of moments and allows for computationally efficient approximations. We showcase the usefulness of the proposed method, its equivalence to constrained Bayesian variational inference and demonstrate its superiority over existing approaches in two applications, namely, fast log determinant estimation and information-theoretic Bayesian optimisation.
* 18 pages, 3 figures, Published at Entropy 2019: Special Issue Entropy Based Inference and Optimization in Machine Learning
Asynchronous Batch Bayesian Optimisation with Improved Local Penalisation
Jan 30, 2019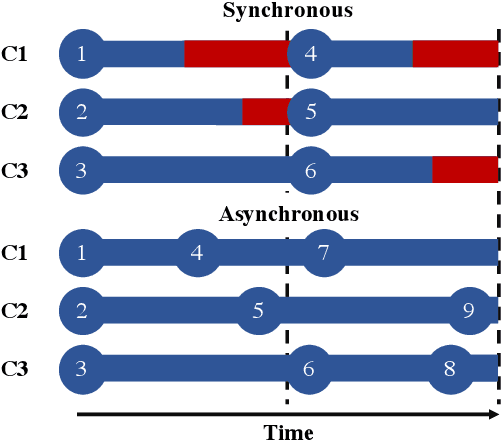
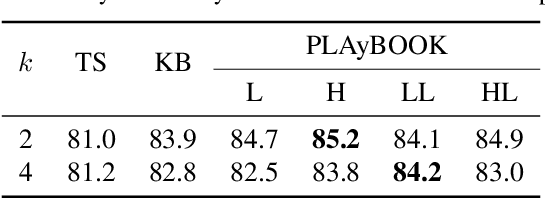
Batch Bayesian optimisation (BO) has been successfully applied to hyperparameter tuning using parallel computing, but it is wasteful of resources: workers that complete jobs ahead of others are left idle. We address this problem by developing an approach, Penalising Locally for Asynchronous Bayesian Optimisation on $k$ workers (PLAyBOOK), for asynchronous parallel BO. We demonstrate empirically the efficacy of PLAyBOOK and its variants on synthetic tasks and a real-world problem. We undertake a comparison between synchronous and asynchronous BO, and show that asynchronous BO often outperforms synchronous batch BO in both wall-clock time and number of function evaluations.
Fast Information-theoretic Bayesian Optimisation
Jun 06, 2018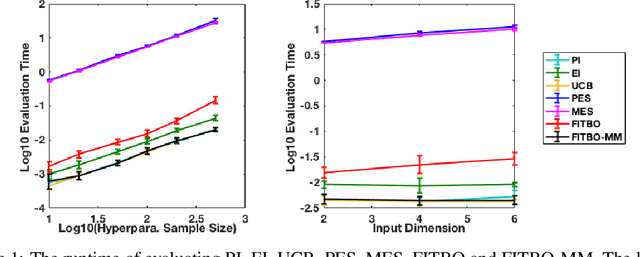
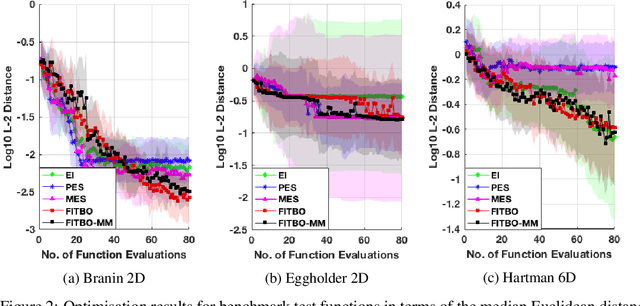
Information-theoretic Bayesian optimisation techniques have demonstrated state-of-the-art performance in tackling important global optimisation problems. However, current information-theoretic approaches require many approximations in implementation, introduce often-prohibitive computational overhead and limit the choice of kernels available to model the objective. We develop a fast information-theoretic Bayesian Optimisation method, FITBO, that avoids the need for sampling the global minimiser, thus significantly reducing computational overhead. Moreover, in comparison with existing approaches, our method faces fewer constraints on kernel choice and enjoys the merits of dealing with the output space. We demonstrate empirically that FITBO inherits the performance associated with information-theoretic Bayesian optimisation, while being even faster than simpler Bayesian optimisation approaches, such as Expected Improvement.
Entropic Spectral Learning in Large Scale Networks
Apr 18, 2018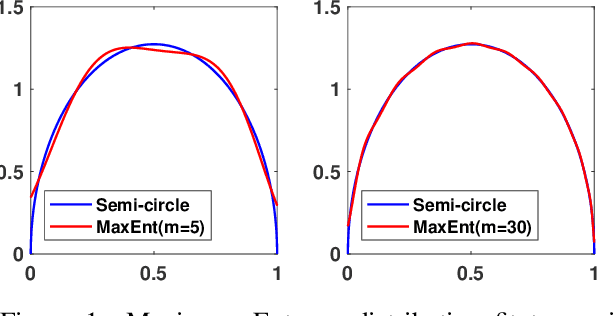

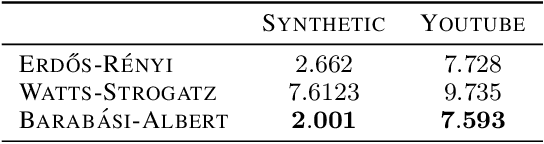
We present a novel algorithm for learning the spectral density of large scale networks using stochastic trace estimation and the method of maximum entropy. The complexity of the algorithm is linear in the number of non-zero elements of the matrix, offering a computational advantage over other algorithms. We apply our algorithm to the problem of community detection in large networks. We show state-of-the-art performance on both synthetic and real datasets.