 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Augmented Entity and Relation Extraction for Legal Documents with Hypergraph Neural Network
Feb 09, 2026With the continuous progress of digitization in Chinese judicial institutions, a substantial amount of electronic legal document information has been accumulated. To unlock its potential value, entity and relation extraction for legal documents has emerged as a crucial task. However, existing methods often lack domain-specific knowledge and fail to account for the unique characteristics of the judicial domain. In this paper, we propose an entity and relation extraction algorithm based on hypergraph neural network (Legal-KAHRE) for drug-related judgment documents. Firstly, we design a candidate span generator based on neighbor-oriented packing strategy and biaffine mechanism, which identifies spans likely to contain entities. Secondly, we construct a legal dictionary with judicial domain knowledge and integrate it into text encoding representation using multi-head attention. Additionally, we incorporate domain-specific cases like joint crimes and combined punishment for multiple crimes into the hypergraph structure design. Finally, we employ a hypergraph neural network for higher-order inference via message passing. Experimental results on the CAIL2022 information extraction dataset demonstrate that our method significantly outperforms existing baseline models.
JUSTICE: Judicial Unified Synthesis Through Intermediate Conclusion Emulation for Automated Judgment Document Generation
Feb 09, 2026Automated judgment document generation is a significant yet challenging legal AI task. As the conclusive written instrument issued by a court, a judgment document embodies complex legal reasoning. However, existing methods often oversimplify this complex process, particularly by omitting the ``Pre-Judge'' phase, a crucial step where human judges form a preliminary conclusion. This omission leads to two core challenges: 1) the ineffective acquisition of foundational judicial elements, and 2) the inadequate modeling of the Pre-Judge process, which collectively undermine the final document's legal soundness. To address these challenges, we propose \textit{\textbf{J}udicial \textbf{U}nified \textbf{S}ynthesis \textbf{T}hrough \textbf{I}ntermediate \textbf{C}onclusion \textbf{E}mulation} (JUSTICE), a novel framework that emulates the ``Search $\rightarrow$ Pre-Judge $\rightarrow$ Write'' cognitive workflow of human judges. Specifically, it introduces the Pre-Judge stage through three dedicated components: Referential Judicial Element Retriever (RJER), Intermediate Conclusion Emulator (ICE), and Judicial Unified Synthesizer (JUS). RJER first retrieves legal articles and a precedent case to establish a referential foundation. ICE then operationalizes the Pre-Judge phase by generating a verifiable intermediate conclusion. Finally, JUS synthesizes these inputs to craft the final judgment. Experiments on both an in-domain legal benchmark and an out-of-distribution dataset show that JUSTICE significantly outperforms strong baselines, with substantial gains in legal accuracy, including a 4.6\% improvement in prison term prediction. Our findings underscore the importance of explicitly modeling the Pre-Judge process to enhance the legal coherence and accuracy of generated judgment documents.
Constraint-Aware Generative Auto-bidding via Pareto-Prioritized Regret Optimization
Feb 09, 2026Auto-bidding systems aim to maximize marketing value while satisfying strict efficiency constraints such as Target Cost-Per-Action (CPA). Although Decision Transformers provide powerful sequence modeling capabilities, applying them to this constrained setting encounters two challenges: 1) standard Return-to-Go conditioning causes state aliasing by neglecting the cost dimension, preventing precise resource pacing; and 2) standard regression forces the policy to mimic average historical behaviors, thereby limiting the capacity to optimize performance toward the constraint boundary. To address these challenges, we propose PRO-Bid, a constraint-aware generative auto-bidding framework based on two synergistic mechanisms: 1) Constraint-Decoupled Pareto Representation (CDPR) decomposes global constraints into recursive cost and value contexts to restore resource perception, while reweighting trajectories based on the Pareto frontier to focus on high-efficiency data; and 2) Counterfactual Regret Optimization (CRO) facilitates active improvement by utilizing a global outcome predictor to identify superior counterfactual actions. By treating these high-utility outcomes as weighted regression targets, the model transcends historical averages to approach the optimal constraint boundary. Extensive experiments on two public benchmarks and online A/B tests demonstrate that PRO-Bid achieves superior constraint satisfaction and value acquisition compared to state-of-the-art baselines.
System Report for CCL25-Eval Task 10: Prompt-Driven Large Language Model Merge for Fine-Grained Chinese Hate Speech Detection
Dec 10, 2025



The proliferation of hate speech on Chinese social media poses urgent societal risks, yet traditional systems struggle to decode context-dependent rhetorical strategies and evolving slang. To bridge this gap, we propose a novel three-stage LLM-based framework: Prompt Engineering, Supervised Fine-tuning, and LLM Merging. First, context-aware prompts are designed to guide LLMs in extracting implicit hate patterns. Next, task-specific features are integrated during supervised fine-tuning to enhance domain adaptation. Finally, merging fine-tuned LLMs improves robustness against out-of-distribution cases. Evaluations on the STATE-ToxiCN benchmark validate the framework's effectiveness, demonstrating superior performance over baseline methods in detecting fine-grained hate speech.
Deep Reinforcement Learning based Dynamic Optimization of Bus Timetable
Jul 15, 2021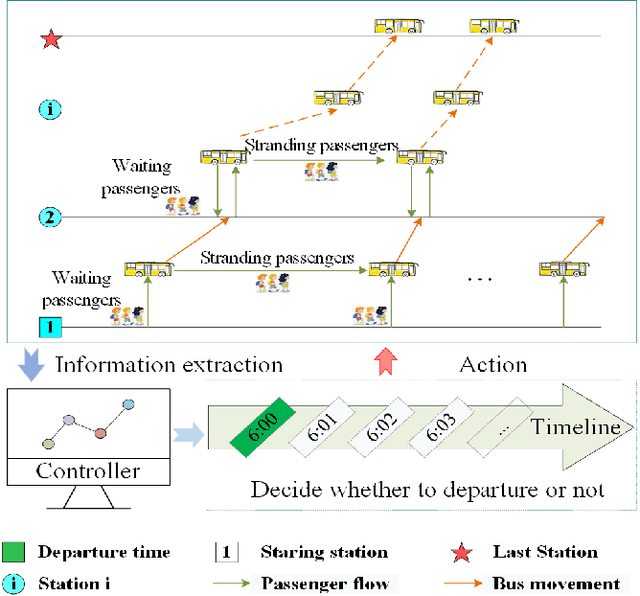
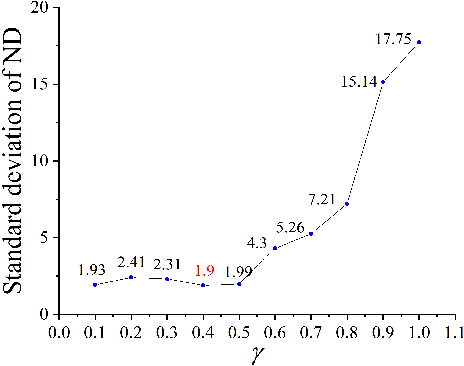
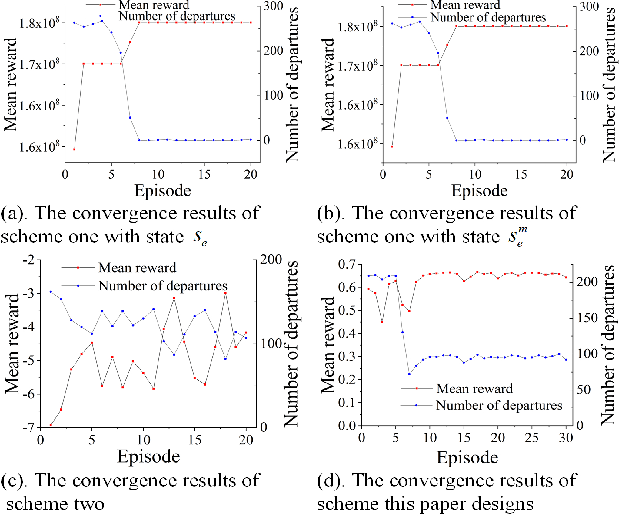
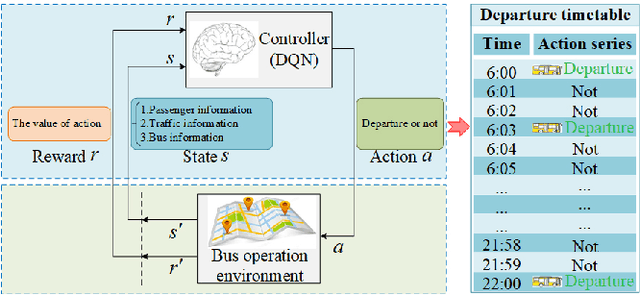
Bus timetable optimization is a key issue to reduce operational cost of bus companies and improve the service quality. Existing methods use exact or heuristic algorithms to optimize the timetable in an offline manner. In practice, the passenger flow may change significantly over time. Timetables determined in offline cannot adjust the departure interval to satisfy the changed passenger flow. Aiming at improving the online performance of bus timetable, we propose a Deep Reinforcement Learning based bus Timetable dynamic Optimization method (DRL-TO). In this method, the timetable optimization is considered as a sequential decision problem. A Deep Q-Network (DQN) is employed as the decision model to determine whether to dispatch a bus service during each minute of the service period. Therefore, the departure intervals of bus services are determined in real time in accordance with passenger demand. We identify several new and useful state features for the DQN, including the load factor, carrying capacity utilization rate, and the number of stranding passengers. Taking into account both the interests of the bus company and passengers, a reward function is designed, which includes the indicators of full load rate, empty load rate, passengers' waiting time, and the number of stranding passengers. Building on an existing method for calculating the carrying capacity, we develop a new technique to enhance the matching degree at each bus station. Experiments demonstrate that compared with the timetable generated by the state-of-the-art bus timetable optimization approach based on a memetic algorithm (BTOA-MA), Genetic Algorithm (GA) and the manual method, DRL-TO can dynamically determine the departure intervals based on the real-time passenger flow, saving 8$\%$ of vehicles and reducing 17$\%$ of passengers' waiting time on average.