 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCESRec: Constructing Pseudo Interactions for Sequential Recommendation via Conversational Feedback
Sep 11, 2025Sequential Recommendation Systems (SRS) have become essential in many real-world applications. However, existing SRS methods often rely on collaborative filtering signals and fail to capture real-time user preferences, while Conversational Recommendation Systems (CRS) excel at eliciting immediate interests through natural language interactions but neglect historical behavior. To bridge this gap, we propose CESRec, a novel framework that integrates the long-term preference modeling of SRS with the real-time preference elicitation of CRS. We introduce semantic-based pseudo interaction construction, which dynamically updates users'historical interaction sequences by analyzing conversational feedback, generating a pseudo-interaction sequence that seamlessly combines long-term and real-time preferences. Additionally, we reduce the impact of outliers in historical items that deviate from users'core preferences by proposing dual alignment outlier items masking, which identifies and masks such items using semantic-collaborative aligned representations. Extensive experiments demonstrate that CESRec achieves state-of-the-art performance by boosting strong SRS models, validating its effectiveness in integrating conversational feedback into SRS.
Syllable based DNN-HMM Cantonese Speech to Text System
Feb 13, 2024This paper reports our work on building up a Cantonese Speech-to-Text (STT) system with a syllable based acoustic model. This is a part of an effort in building a STT system to aid dyslexic students who have cognitive deficiency in writing skills but have no problem expressing their ideas through speech. For Cantonese speech recognition, the basic unit of acoustic models can either be the conventional Initial-Final (IF) syllables, or the Onset-Nucleus-Coda (ONC) syllables where finals are further split into nucleus and coda to reflect the intra-syllable variations in Cantonese. By using the Kaldi toolkit, our system is trained using the stochastic gradient descent optimization model with the aid of GPUs for the hybrid Deep Neural Network and Hidden Markov Model (DNN-HMM) with and without I-vector based speaker adaptive training technique. The input features of the same Gaussian Mixture Model with speaker adaptive training (GMM-SAT) to DNN are used in all cases. Experiments show that the ONC-based syllable acoustic modeling with I-vector based DNN-HMM achieves the best performance with the word error rate (WER) of 9.66% and the real time factor (RTF) of 1.38812.
Relation Extraction with Self-determined Graph Convolutional Network
Aug 27, 2020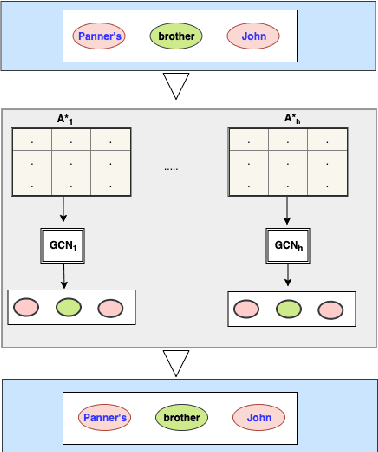
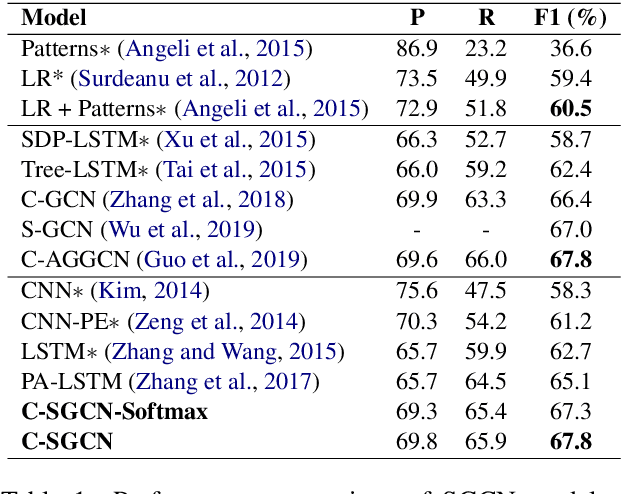
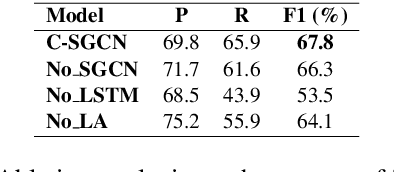
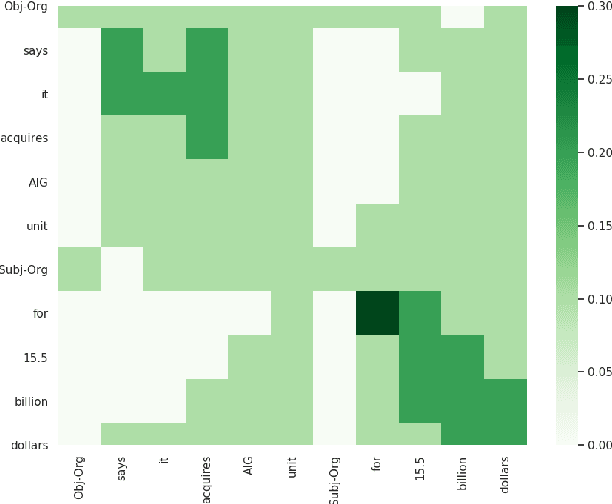
Relation Extraction is a way of obtaining the semantic relationship between entities in text. The state-of-the-art methods use linguistic tools to build a graph for the text in which the entities appear and then a Graph Convolutional Network (GCN) is employed to encode the pre-built graphs. Although their performance is promising, the reliance on linguistic tools results in a non end-to-end process. In this work, we propose a novel model, the Self-determined Graph Convolutional Network (SGCN), which determines a weighted graph using a self-attention mechanism, rather using any linguistic tool. Then, the self-determined graph is encoded using a GCN. We test our model on the TACRED dataset and achieve the state-of-the-art result. Our experiments show that SGCN outperforms the traditional GCN, which uses dependency parsing tools to build the graph.