 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Data-Driven Control Synthesis for Nonlinear Systems with Actuation Uncertainty
Nov 21, 2020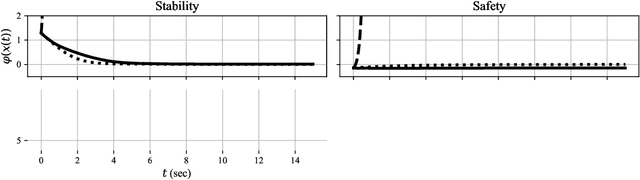
Modern nonlinear control theory seeks to endow systems with properties such as stability and safety, and has been deployed successfully across various domains. Despite this success, model uncertainty remains a significant challenge in ensuring that model-based controllers transfer to real world systems. This paper develops a data-driven approach to robust control synthesis in the presence of model uncertainty using Control Certificate Functions (CCFs), resulting in a convex optimization based controller for achieving properties like stability and safety. An important benefit of our framework is nuanced data-dependent guarantees, which in principle can yield sample-efficient data collection approaches that need not fully determine the input-to-state relationship. This work serves as a starting point for addressing important questions at the intersection of nonlinear control theory and non-parametric learning, both theoretical and in application. We validate the proposed method in simulation with an inverted pendulum in multiple experimental configurations.
Do Offline Metrics Predict Online Performance in Recommender Systems?
Nov 07, 2020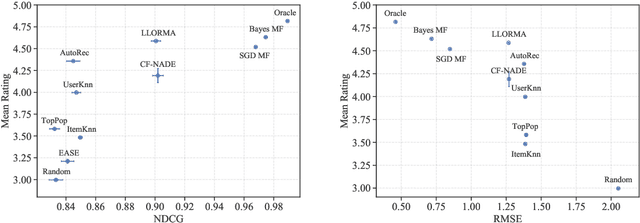
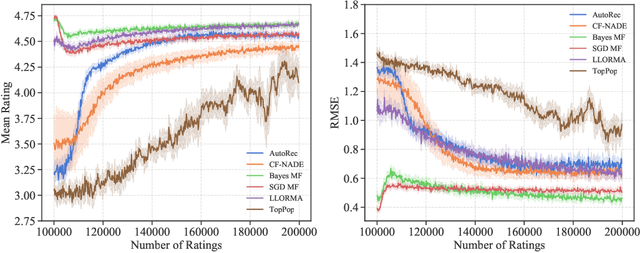
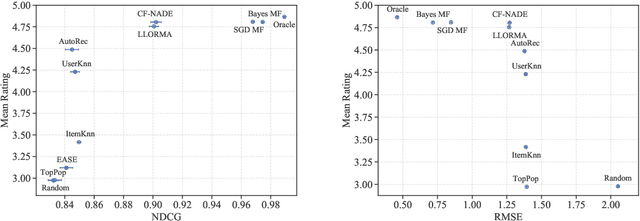
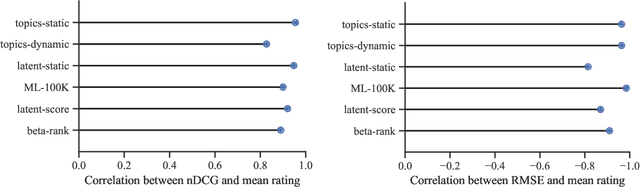
Recommender systems operate in an inherently dynamical setting. Past recommendations influence future behavior, including which data points are observed and how user preferences change. However, experimenting in production systems with real user dynamics is often infeasible, and existing simulation-based approaches have limited scale. As a result, many state-of-the-art algorithms are designed to solve supervised learning problems, and progress is judged only by offline metrics. In this work we investigate the extent to which offline metrics predict online performance by evaluating eleven recommenders across six controlled simulated environments. We observe that offline metrics are correlated with online performance over a range of environments. However, improvements in offline metrics lead to diminishing returns in online performance. Furthermore, we observe that the ranking of recommenders varies depending on the amount of initial offline data available. We study the impact of adding exploration strategies, and observe that their effectiveness, when compared to greedy recommendation, is highly dependent on the recommendation algorithm. We provide the environments and recommenders described in this paper as Reclab: an extensible ready-to-use simulation framework at https://github.com/berkeley-reclab/RecLab.
Guaranteeing Safety of Learned Perception Modules via Measurement-Robust Control Barrier Functions
Oct 30, 2020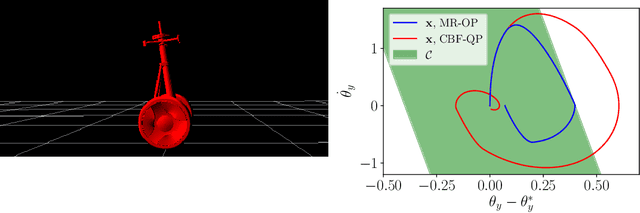
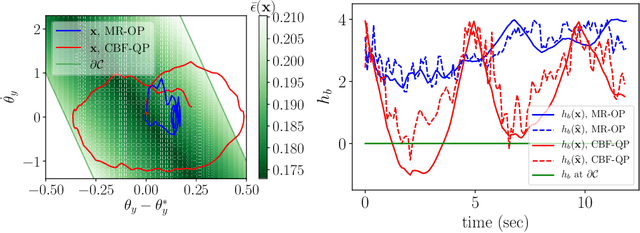
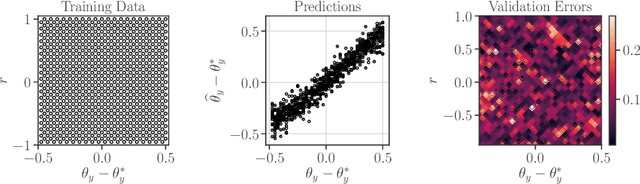
Modern nonlinear control theory seeks to develop feedback controllers that endow systems with properties such as safety and stability. The guarantees ensured by these controllers often rely on accurate estimates of the system state for determining control actions. In practice, measurement model uncertainty can lead to error in state estimates that degrades these guarantees. In this paper, we seek to unify techniques from control theory and machine learning to synthesize controllers that achieve safety in the presence of measurement model uncertainty. We define the notion of a Measurement-Robust Control Barrier Function (MR-CBF) as a tool for determining safe control inputs when facing measurement model uncertainty. Furthermore, MR-CBFs are used to inform sampling methodologies for learning-based perception systems and quantify tolerable error in the resulting learned models. We demonstrate the efficacy of MR-CBFs in achieving safety with measurement model uncertainty on a simulated Segway system.
A Generalizable and Accessible Approach to Machine Learning with Global Satellite Imagery
Oct 16, 2020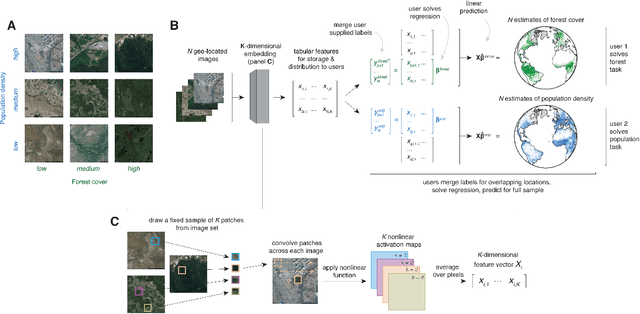
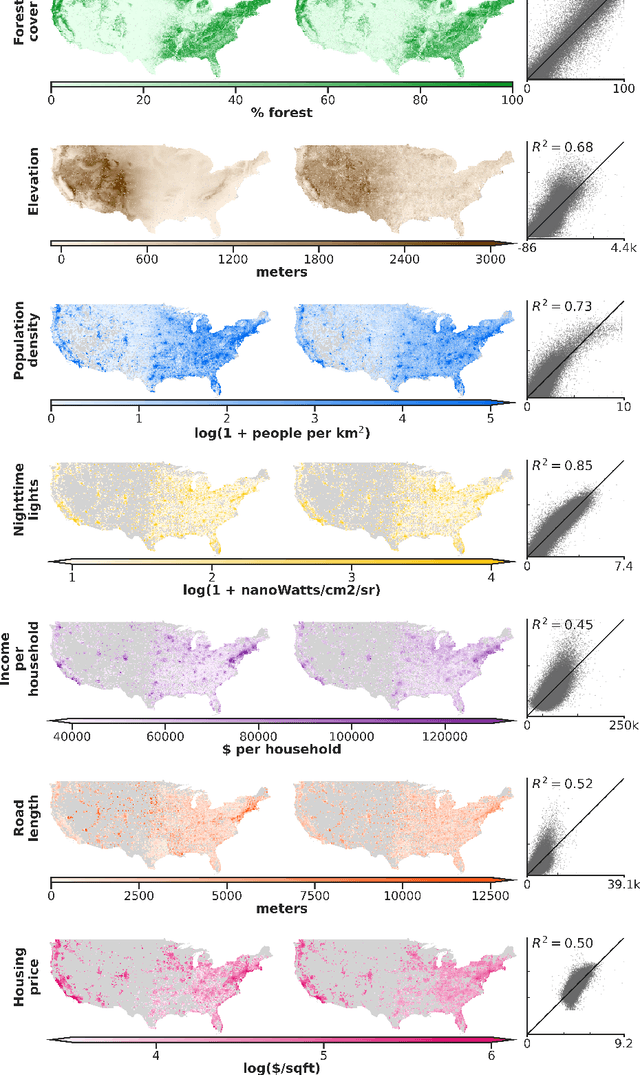
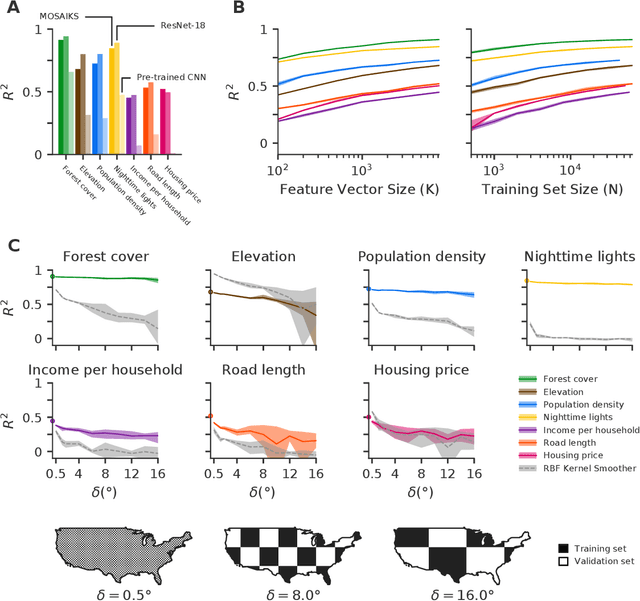
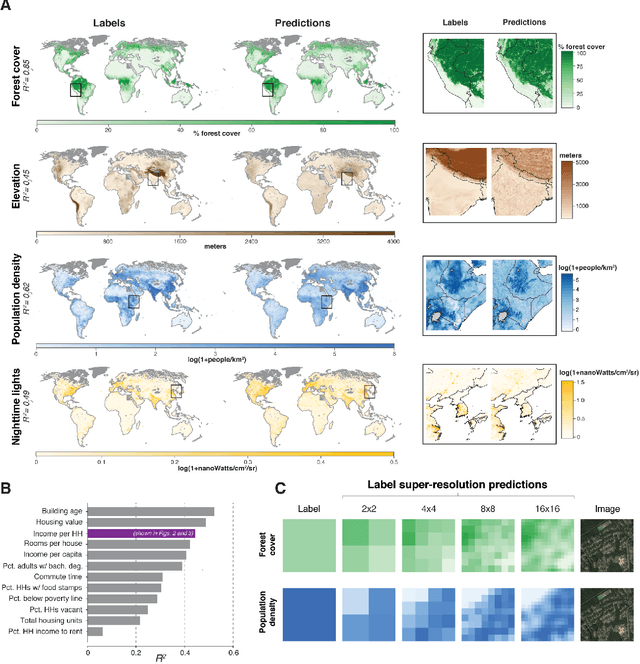
Combining satellite imagery with machine learning (SIML) has the potential to address global challenges by remotely estimating socioeconomic and environmental conditions in data-poor regions, yet the resource requirements of SIML limit its accessibility and use. We show that a single encoding of satellite imagery can generalize across diverse prediction tasks (e.g. forest cover, house price, road length). Our method achieves accuracy competitive with deep neural networks at orders of magnitude lower computational cost, scales globally, delivers label super-resolution predictions, and facilitates characterizations of uncertainty. Since image encodings are shared across tasks, they can be centrally computed and distributed to unlimited researchers, who need only fit a linear regression to their own ground truth data in order to achieve state-of-the-art SIML performance.
Certainty Equivalent Perception-Based Control
Aug 27, 2020In order to certify performance and safety, feedback control requires precise characterization of sensor errors. In this paper, we provide guarantees on such feedback systems when sensors are characterized by solving a supervised learning problem. We show a uniform error bound on nonparametric kernel regression under a dynamically-achievable dense sampling scheme. This allows for a finite-time convergence rate on the sub-optimality of using the regressor in closed-loop for waypoint tracking. We demonstrate our results in simulation with simplified unmanned aerial vehicle and autonomous driving examples.
Measuring Robustness to Natural Distribution Shifts in Image Classification
Jul 01, 2020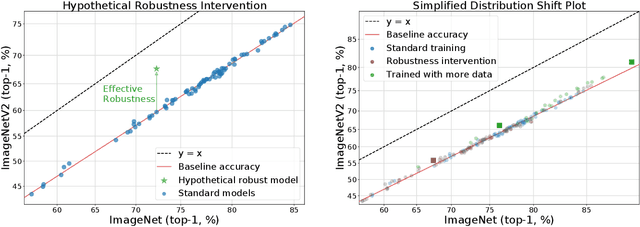
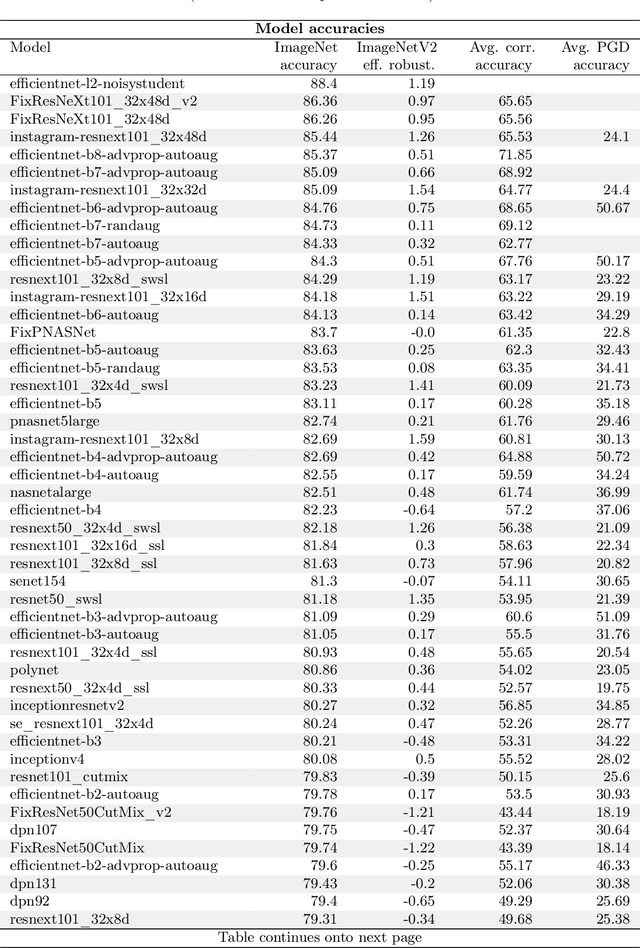
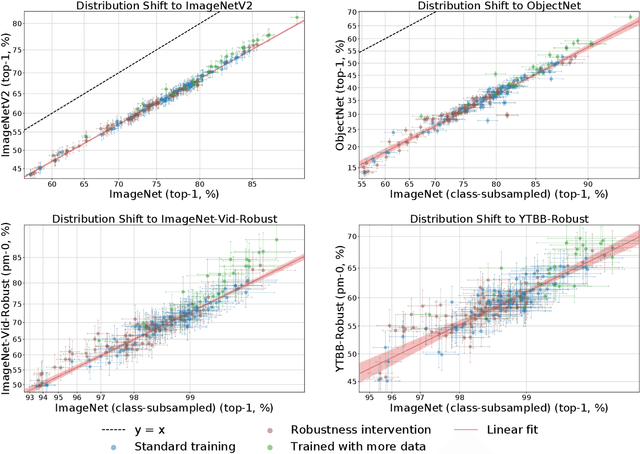
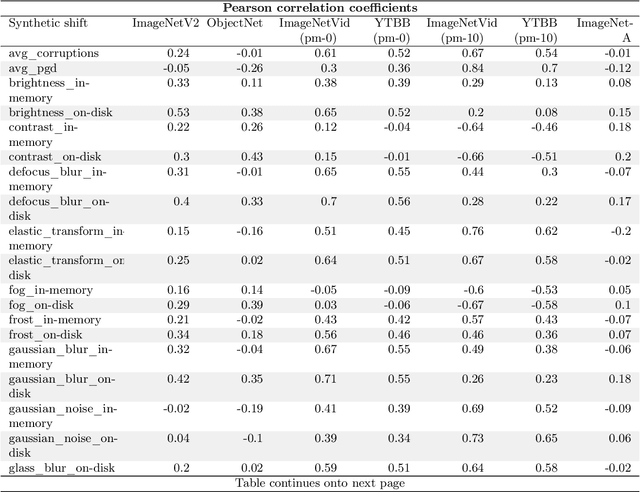
We study how robust current ImageNet models are to distribution shifts arising from natural variations in datasets. Most research on robustness focuses on synthetic image perturbations (noise, simulated weather artifacts, adversarial examples, etc.), which leaves open how robustness on synthetic distribution shift relates to distribution shift arising in real data. Informed by an evaluation of 196 ImageNet models in 211 different test conditions, we find that there is little to no transfer of robustness from current synthetic to natural distribution shift. Moreover, most current techniques provide no robustness to the natural distribution shifts in our testbed. The main exception is training on larger datasets, which in some cases offers small gains in robustness. Our results indicate that distribution shifts arising in real data are currently an open research problem.
Active Learning for Nonlinear System Identification with Guarantees
Jun 18, 2020While the identification of nonlinear dynamical systems is a fundamental building block of model-based reinforcement learning and feedback control, its sample complexity is only understood for systems that either have discrete states and actions or for systems that can be identified from data generated by i.i.d. random inputs. Nonetheless, many interesting dynamical systems have continuous states and actions and can only be identified through a judicious choice of inputs. Motivated by practical settings, we study a class of nonlinear dynamical systems whose state transitions depend linearly on a known feature embedding of state-action pairs. To estimate such systems in finite time identification methods must explore all directions in feature space. We propose an active learning approach that achieves this by repeating three steps: trajectory planning, trajectory tracking, and re-estimation of the system from all available data. We show that our method estimates nonlinear dynamical systems at a parametric rate, similar to the statistical rate of standard linear regression.
The Effect of Natural Distribution Shift on Question Answering Models
Apr 29, 2020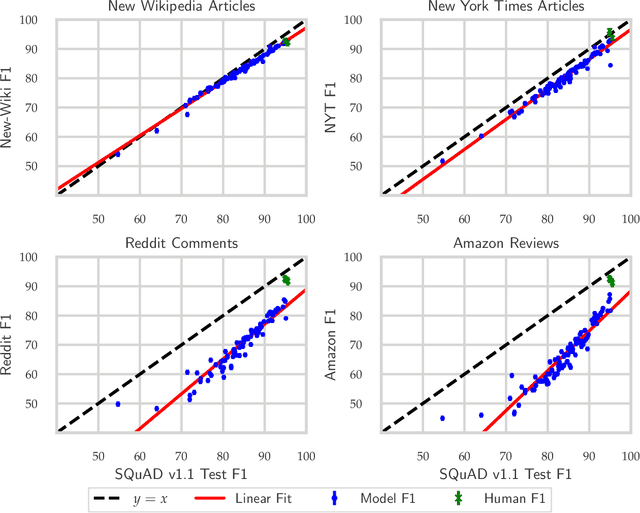
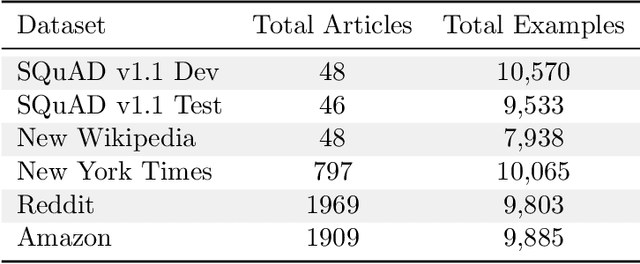

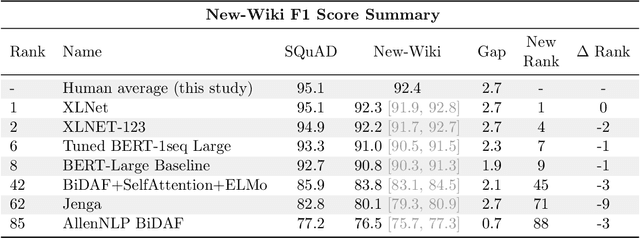
We build four new test sets for the Stanford Question Answering Dataset (SQuAD) and evaluate the ability of question-answering systems to generalize to new data. Our first test set is from the original Wikipedia domain and measures the extent to which existing systems overfit the original test set. Despite several years of heavy test set re-use, we find no evidence of adaptive overfitting. The remaining three test sets are constructed from New York Times articles, Reddit posts, and Amazon product reviews and measure robustness to natural distribution shifts. Across a broad range of models, we observe average performance drops of 3.8, 14.0, and 17.4 F1 points, respectively. In contrast, a strong human baseline matches or exceeds the performance of SQuAD models on the original domain and exhibits little to no drop in new domains. Taken together, our results confirm the surprising resilience of the holdout method and emphasize the need to move towards evaluation metrics that incorporate robustness to natural distribution shifts.
Post-Estimation Smoothing: A Simple Baseline for Learning with Side Information
Mar 12, 2020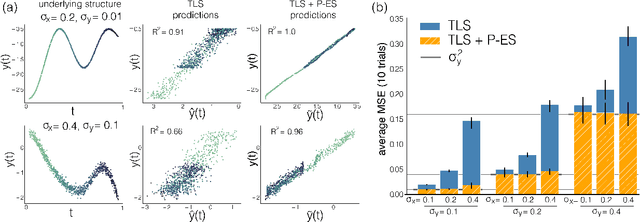
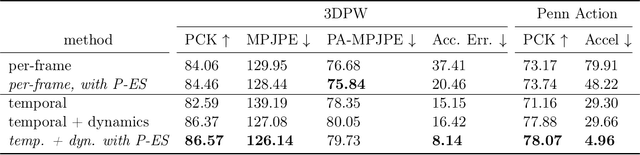
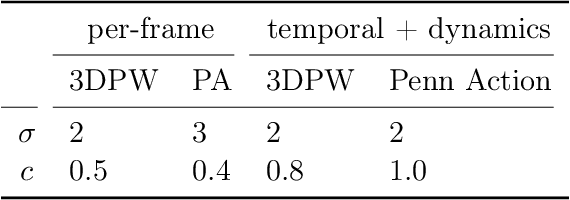
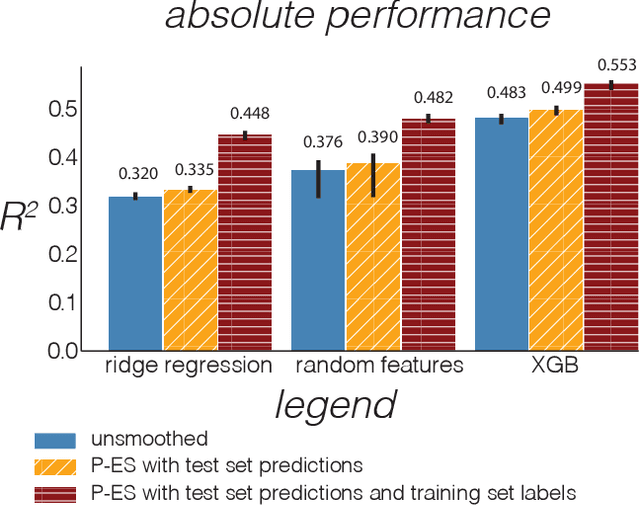
Observational data are often accompanied by natural structural indices, such as time stamps or geographic locations, which are meaningful to prediction tasks but are often discarded. We leverage semantically meaningful indexing data while ensuring robustness to potentially uninformative or misleading indices. We propose a post-estimation smoothing operator as a fast and effective method for incorporating structural index data into prediction. Because the smoothing step is separate from the original predictor, it applies to a broad class of machine learning tasks, with no need to retrain models. Our theoretical analysis details simple conditions under which post-estimation smoothing will improve accuracy over that of the original predictor. Our experiments on large scale spatial and temporal datasets highlight the speed and accuracy of post-estimation smoothing in practice. Together, these results illuminate a novel way to consider and incorporate the natural structure of index variables in machine learning.
Neural Kernels Without Tangents
Mar 05, 2020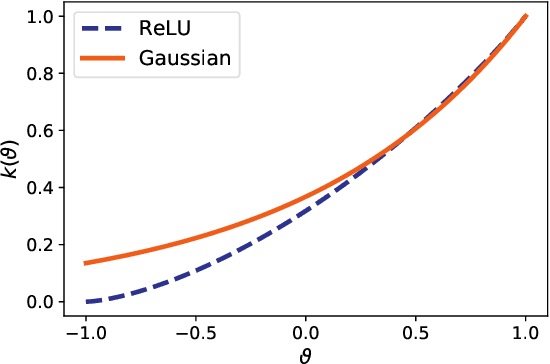
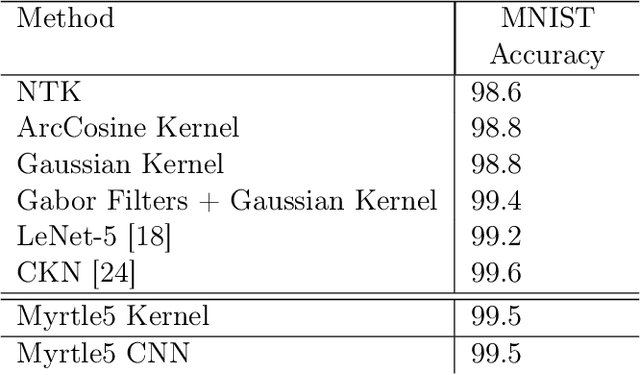


We investigate the connections between neural networks and simple building blocks in kernel space. In particular, using well established feature space tools such as direct sum, averaging, and moment lifting, we present an algebra for creating "compositional" kernels from bags of features. We show that these operations correspond to many of the building blocks of "neural tangent kernels (NTK)". Experimentally, we show that there is a correlation in test error between neural network architectures and the associated kernels. We construct a simple neural network architecture using only 3x3 convolutions, 2x2 average pooling, ReLU, and optimized with SGD and MSE loss that achieves 96% accuracy on CIFAR10, and whose corresponding compositional kernel achieves 90% accuracy. We also use our constructions to investigate the relative performance of neural networks, NTKs, and compositional kernels in the small dataset regime. In particular, we find that compositional kernels outperform NTKs and neural networks outperform both kernel methods.