 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deep network approach to multitemporal cloud detection
Dec 09, 2020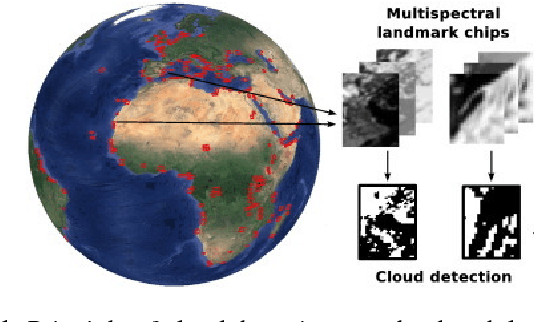
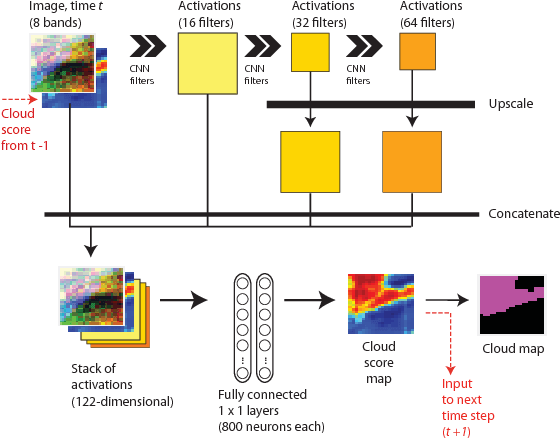
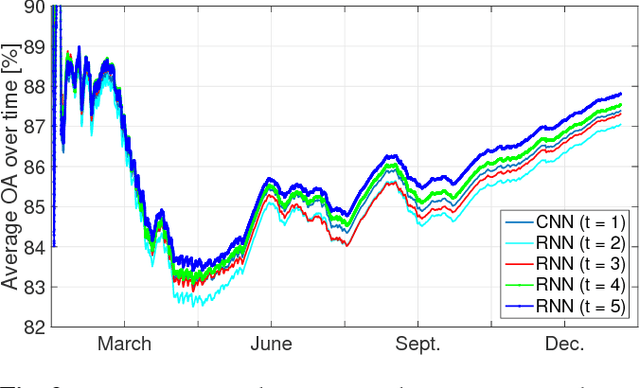
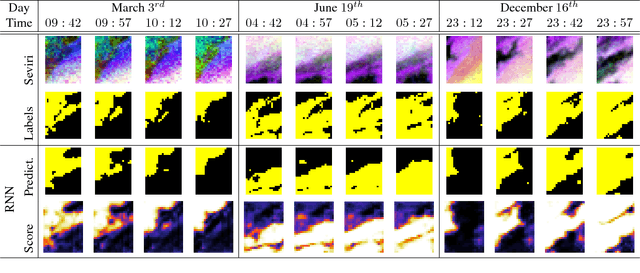
We present a deep learning model with temporal memory to detect clouds in image time series acquired by the Seviri imager mounted on the Meteosat Second Generation (MSG) satellite. The model provides pixel-level cloud maps with related confidence and propagates information in time via a recurrent neural network structure. With a single model, we are able to outline clouds along all year and during day and night with high accuracy.
Half a Percent of Labels is Enough: Efficient Animal Detection in UAV Imagery using Deep CNNs and Active Learning
Jul 17, 2019

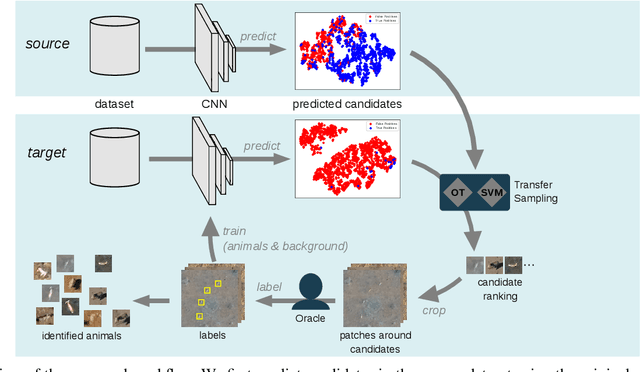
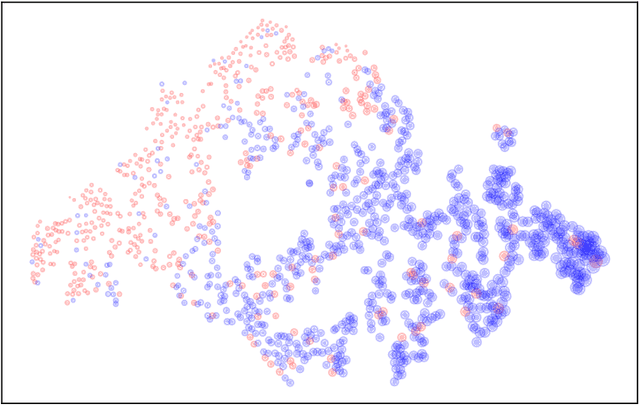
We present an Active Learning (AL) strategy for re-using a deep Convolutional Neural Network (CNN)-based object detector on a new dataset. This is of particular interest for wildlife conservation: given a set of images acquired with an Unmanned Aerial Vehicle (UAV) and manually labeled gound truth, our goal is to train an animal detector that can be re-used for repeated acquisitions, e.g. in follow-up years. Domain shifts between datasets typically prevent such a direct model application. We thus propose to bridge this gap using AL and introduce a new criterion called Transfer Sampling (TS). TS uses Optimal Transport to find corresponding regions between the source and the target datasets in the space of CNN activations. The CNN scores in the source dataset are used to rank the samples according to their likelihood of being animals, and this ranking is transferred to the target dataset. Unlike conventional AL criteria that exploit model uncertainty, TS focuses on very confident samples, thus allowing a quick retrieval of true positives in the target dataset, where positives are typically extremely rare and difficult to find by visual inspection. We extend TS with a new window cropping strategy that further accelerates sample retrieval. Our experiments show that with both strategies combined, less than half a percent of oracle-provided labels are enough to find almost 80% of the animals in challenging sets of UAV images, beating all baselines by a margin.
DeepJDOT: Deep Joint Distribution Optimal Transport for Unsupervised Domain Adaptation
Sep 05, 2018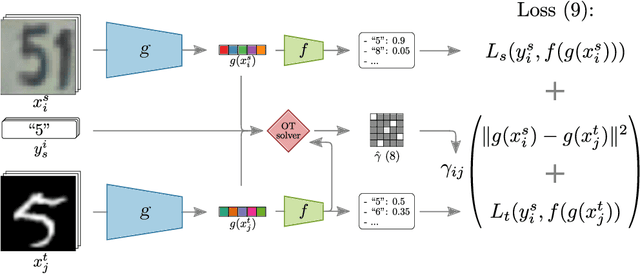
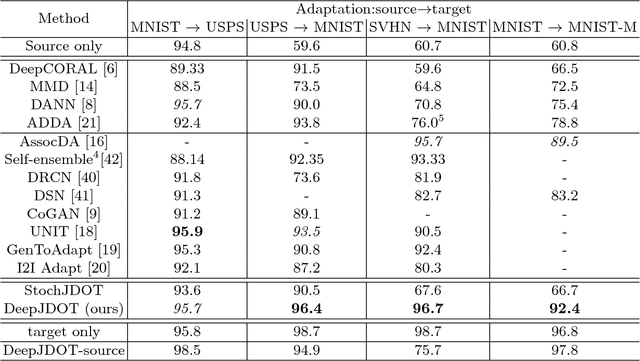


In computer vision, one is often confronted with problems of domain shifts, which occur when one applies a classifier trained on a source dataset to target data sharing similar characteristics (e.g. same classes), but also different latent data structures (e.g. different acquisition conditions). In such a situation, the model will perform poorly on the new data, since the classifier is specialized to recognize visual cues specific to the source domain. In this work we explore a solution, named DeepJDOT, to tackle this problem: through a measure of discrepancy on joint deep representations/labels based on optimal transport, we not only learn new data representations aligned between the source and target domain, but also simultaneously preserve the discriminative information used by the classifier. We applied DeepJDOT to a series of visual recognition tasks, where it compares favorably against state-of-the-art deep domain adaptation methods.
* European Conference on Computer Vision 2018 (ECCV-2018)
Scale equivariance in CNNs with vector fields
Jul 31, 2018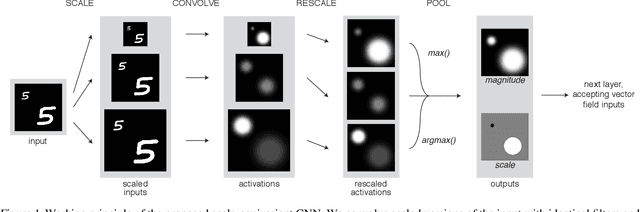
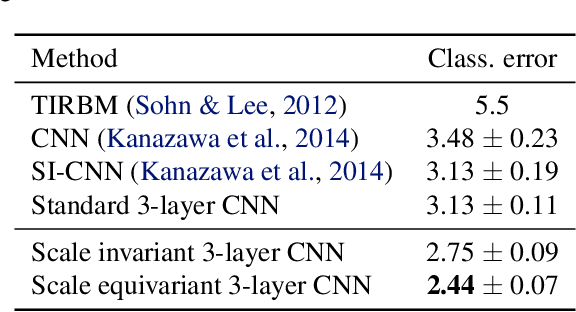
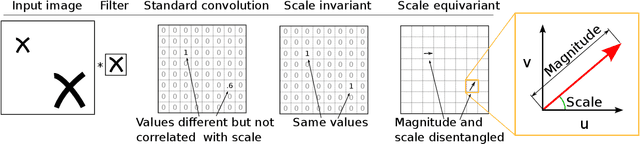
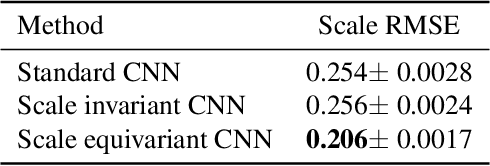
We study the effect of injecting local scale equivariance into Convolutional Neural Networks. This is done by applying each convolutional filter at multiple scales. The output is a vector field encoding for the maximally activating scale and the scale itself, which is further processed by the following convolutional layers. This allows all the intermediate representations to be locally scale equivariant. We show that this improves the performance of the model by over $20\%$ in the scale equivariant task of regressing the scaling factor applied to randomly scaled MNIST digits. Furthermore, we find it also useful for scale invariant tasks, such as the actual classification of randomly scaled digits. This highlights the usefulness of allowing for a compact representation that can also learn relationships between different local scales by keeping internal scale equivariance.
Detecting Mammals in UAV Images: Best Practices to address a substantially Imbalanced Dataset with Deep Learning
Jun 29, 2018

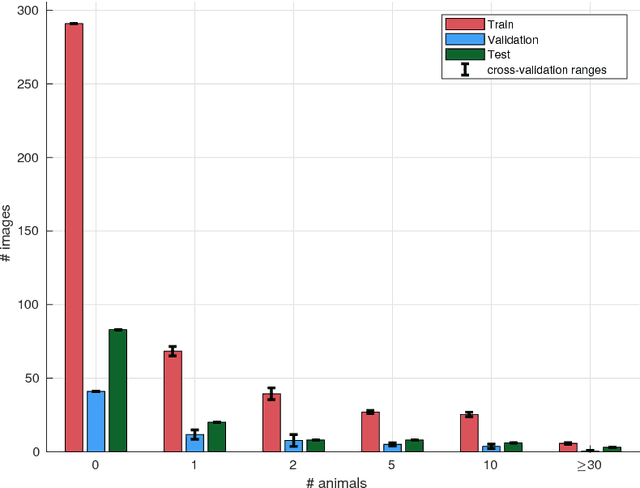
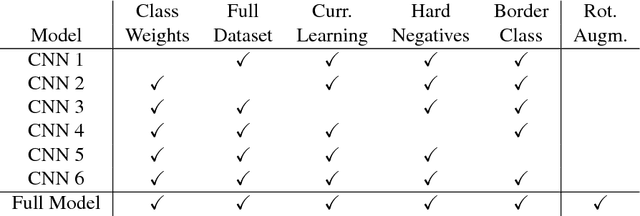
Knowledge over the number of animals in large wildlife reserves is a vital necessity for park rangers in their efforts to protect endangered species. Manual animal censuses are dangerous and expensive, hence Unmanned Aerial Vehicles (UAVs) with consumer level digital cameras are becoming a popular alternative tool to estimate livestock. Several works have been proposed that semi-automatically process UAV images to detect animals, of which some employ Convolutional Neural Networks (CNNs), a recent family of deep learning algorithms that proved very effective in object detection in large datasets from computer vision. However, the majority of works related to wildlife focuses only on small datasets (typically subsets of UAV campaigns), which might be detrimental when presented with the sheer scale of real study areas for large mammal census. Methods may yield thousands of false alarms in such cases. In this paper, we study how to scale CNNs to large wildlife census tasks and present a number of recommendations to train a CNN on a large UAV dataset. We further introduce novel evaluation protocols that are tailored to censuses and model suitability for subsequent human verification of detections. Using our recommendations, we are able to train a CNN reducing the number of false positives by an order of magnitude compared to previous state-of-the-art. Setting the requirements at 90% recall, our CNN allows to reduce the amount of data required for manual verification by three times, thus making it possible for rangers to screen all the data acquired efficiently and to detect almost all animals in the reserve automatically.
Learning deep structured active contours end-to-end
Mar 16, 2018
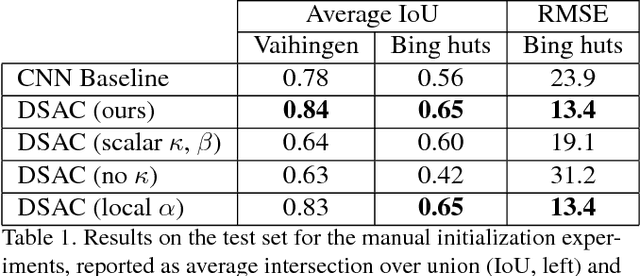
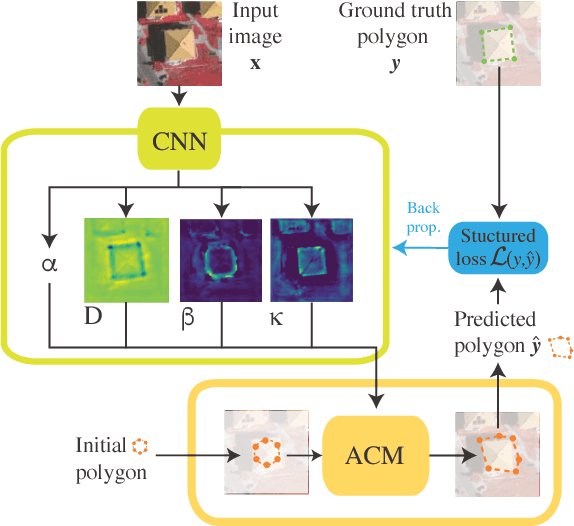
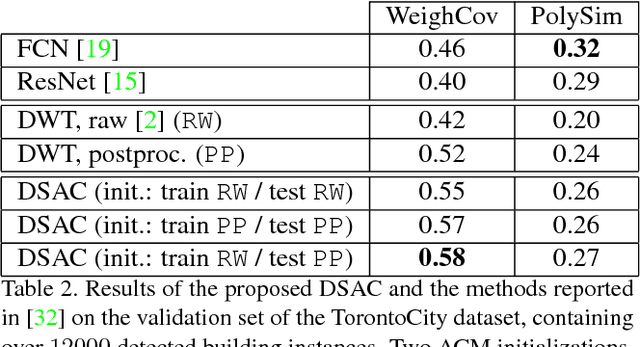
The world is covered with millions of buildings, and precisely knowing each instance's position and extents is vital to a multitude of applications. Recently, automated building footprint segmentation models have shown superior detection accuracy thanks to the usage of Convolutional Neural Networks (CNN). However, even the latest evolutions struggle to precisely delineating borders, which often leads to geometric distortions and inadvertent fusion of adjacent building instances. We propose to overcome this issue by exploiting the distinct geometric properties of buildings. To this end, we present Deep Structured Active Contours (DSAC), a novel framework that integrates priors and constraints into the segmentation process, such as continuous boundaries, smooth edges, and sharp corners. To do so, DSAC employs Active Contour Models (ACM), a family of constraint- and prior-based polygonal models. We learn ACM parameterizations per instance using a CNN, and show how to incorporate all components in a structured output model, making DSAC trainable end-to-end. We evaluate DSAC on three challenging building instance segmentation datasets, where it compares favorably against state-of-the-art. Code will be made available.
Land cover mapping at very high resolution with rotation equivariant CNNs: towards small yet accurate models
Mar 16, 2018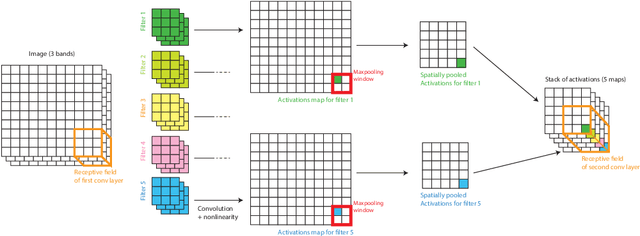
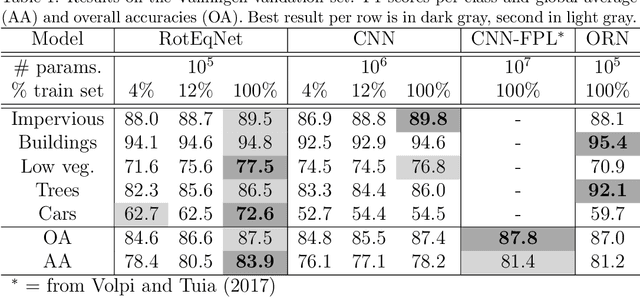
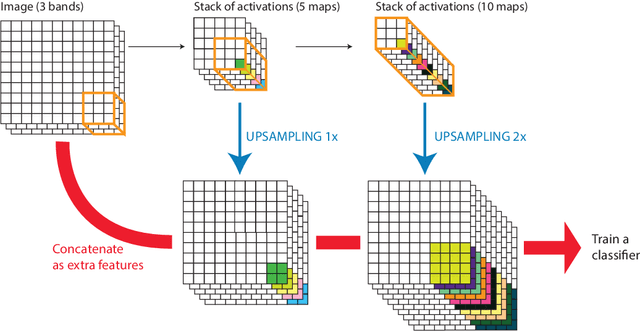
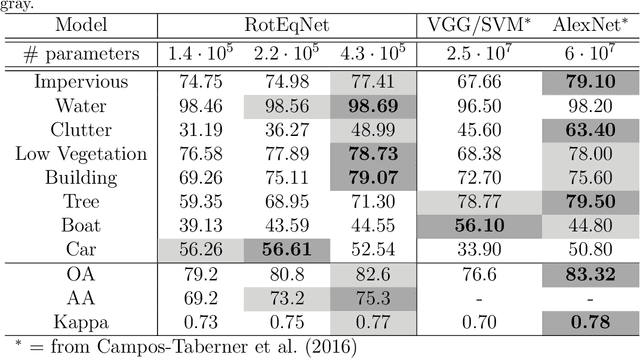
In remote sensing images, the absolute orientation of objects is arbitrary. Depending on an object's orientation and on a sensor's flight path, objects of the same semantic class can be observed in different orientations in the same image. Equivariance to rotation, in this context understood as responding with a rotated semantic label map when subject to a rotation of the input image, is therefore a very desirable feature, in particular for high capacity models, such as Convolutional Neural Networks (CNNs). If rotation equivariance is encoded in the network, the model is confronted with a simpler task and does not need to learn specific (and redundant) weights to address rotated versions of the same object class. In this work we propose a CNN architecture called Rotation Equivariant Vector Field Network (RotEqNet) to encode rotation equivariance in the network itself. By using rotating convolutions as building blocks and passing only the the values corresponding to the maximally activating orientation throughout the network in the form of orientation encoding vector fields, RotEqNet treats rotated versions of the same object with the same filter bank and therefore achieves state-of-the-art performances even when using very small architectures trained from scratch. We test RotEqNet in two challenging sub-decimeter resolution semantic labeling problems, and show that we can perform better than a standard CNN while requiring one order of magnitude less parameters.