 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization by Solving Jigsaw Puzzles
Apr 14, 2019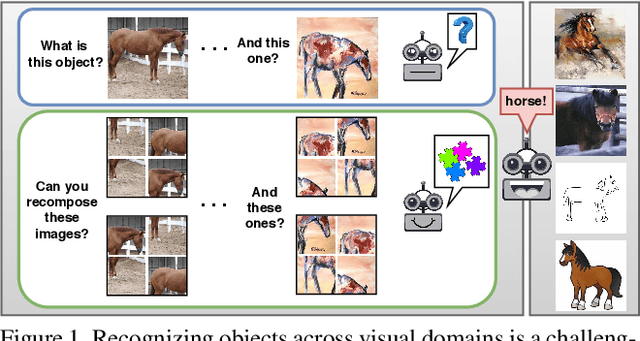
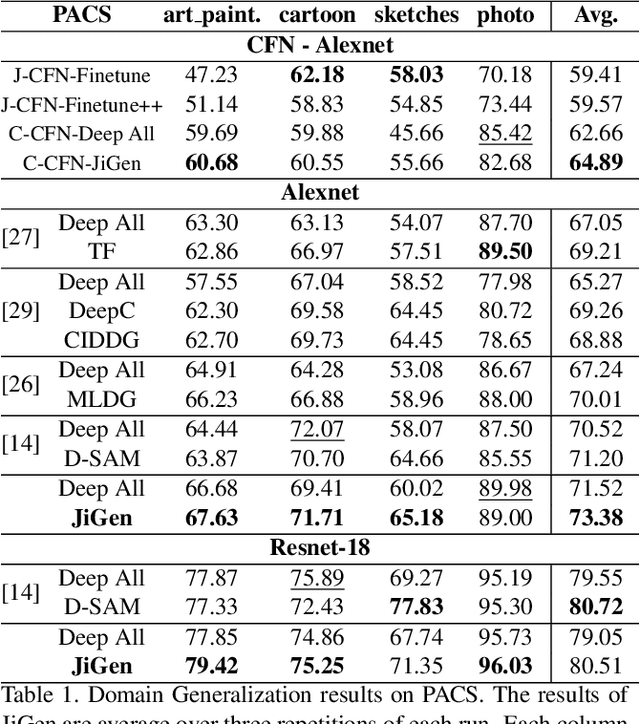
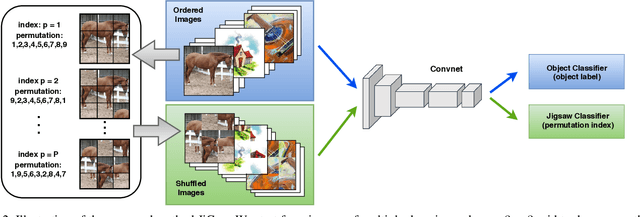
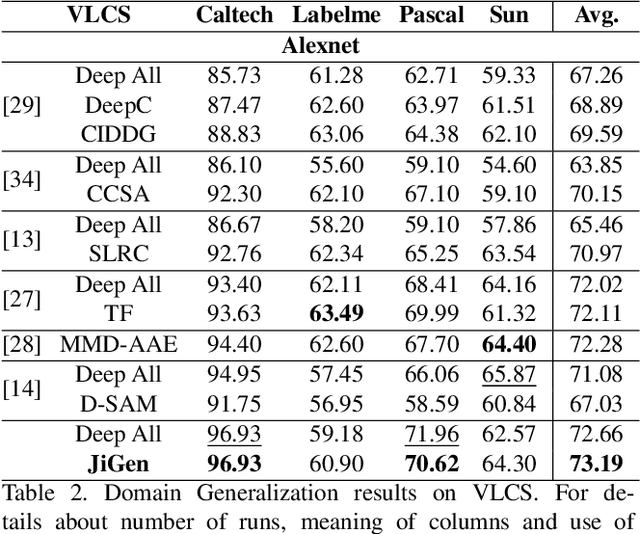
Human adaptability relies crucially on the ability to learn and merge knowledge both from supervised and unsupervised learning: the parents point out few important concepts, but then the children fill in the gaps on their own. This is particularly effective, because supervised learning can never be exhaustive and thus learning autonomously allows to discover invariances and regularities that help to generalize. In this paper we propose to apply a similar approach to the task of object recognition across domains: our model learns the semantic labels in a supervised fashion, and broadens its understanding of the data by learning from self-supervised signals how to solve a jigsaw puzzle on the same images. This secondary task helps the network to learn the concepts of spatial correlation while acting as a regularizer for the classification task. Multiple experiments on the PACS, VLCS, Office-Home and digits datasets confirm our intuition and show that this simple method outperforms previous domain generalization and adaptation solutions. An ablation study further illustrates the inner workings of our approach.
The RGB-D Triathlon: Towards Agile Visual Toolboxes for Robots
Apr 02, 2019
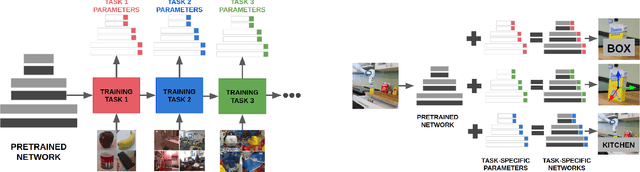

Deep networks have brought significant advances in robot perception, enabling to improve the capabilities of robots in several visual tasks, ranging from object detection and recognition to pose estimation, semantic scene segmentation and many others. Still, most approaches typically address visual tasks in isolation, resulting in overspecialized models which achieve strong performances in specific applications but work poorly in other (often related) tasks. This is clearly sub-optimal for a robot which is often required to perform simultaneously multiple visual recognition tasks in order to properly act and interact with the environment. This problem is exacerbated by the limited computational and memory resources typically available onboard to a robotic platform. The problem of learning flexible models which can handle multiple tasks in a lightweight manner has recently gained attention in the computer vision community and benchmarks supporting this research have been proposed. In this work we study this problem in the robot vision context, proposing a new benchmark, the RGB-D Triathlon, and evaluating state of the art algorithms in this novel challenging scenario. We also define a new evaluation protocol, better suited to the robot vision setting. Results shed light on the strengths and weaknesses of existing approaches and on open issues, suggesting directions for future research.
AdaGraph: Unifying Predictive and Continuous Domain Adaptation through Graphs
Mar 19, 2019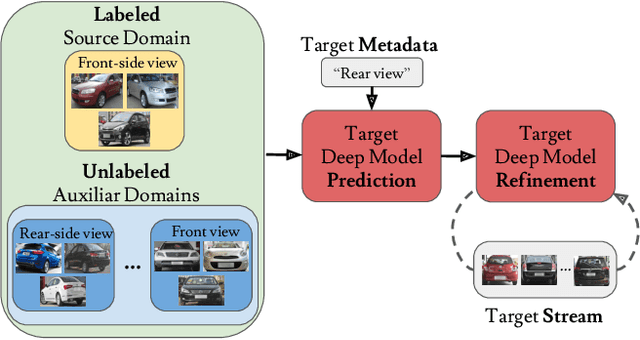
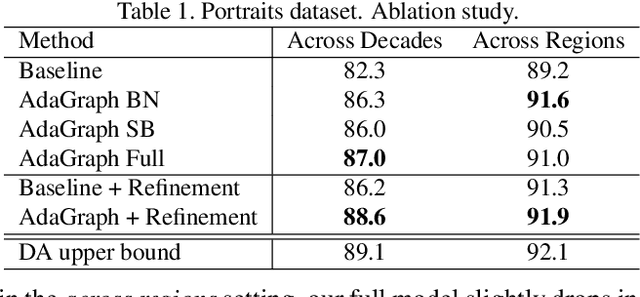
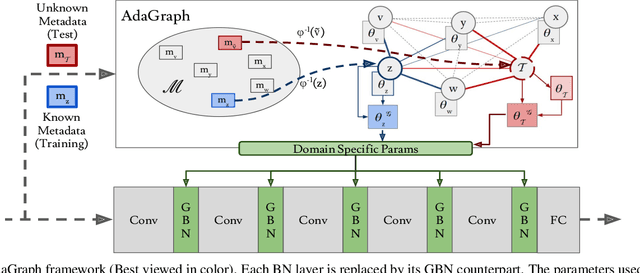
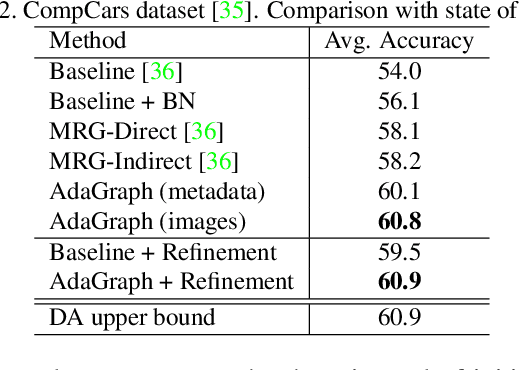
The ability to categorize is a cornerstone of visual intelligence, and a key functionality for artificial, autonomous visual machines. This problem will never be solved without algorithms able to adapt and generalize across visual domains. Within the context of domain adaptation and generalization, this paper focuses on the predictive domain adaptation scenario, namely the case where no target data are available and the system has to learn to generalize from annotated source images plus unlabeled samples with associated metadata from auxiliary domains. Our contributionis the first deep architecture that tackles predictive domainadaptation, able to leverage over the information broughtby the auxiliary domains through a graph. Moreover, we present a simple yet effective strategy that allows us to take advantage of the incoming target data at test time, in a continuous domain adaptation scenario. Experiments on three benchmark databases support the value of our approach.
Domain Generalization with Domain-Specific Aggregation Modules
Sep 28, 2018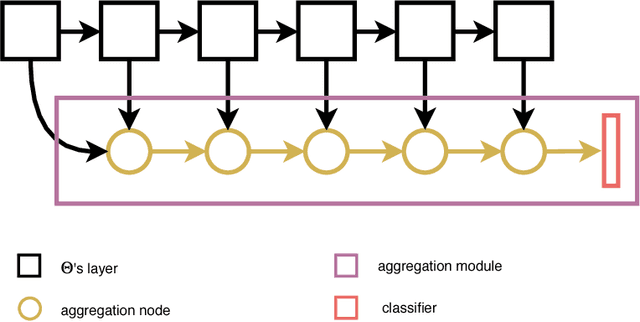
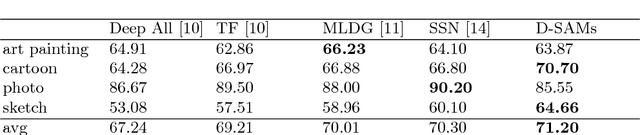
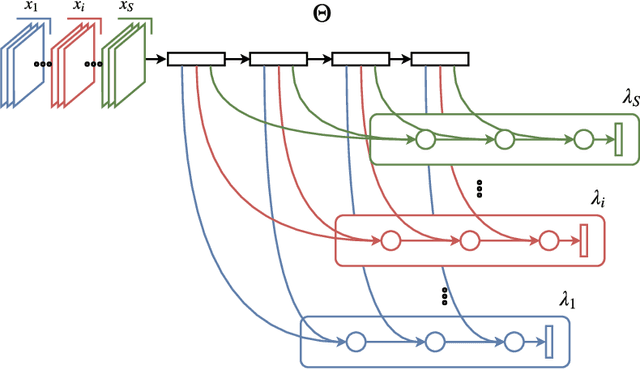
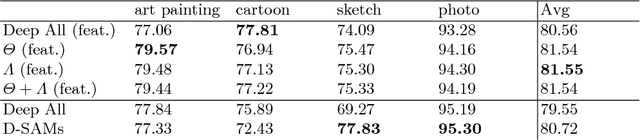
Visual recognition systems are meant to work in the real world. For this to happen, they must work robustly in any visual domain, and not only on the data used during training. Within this context, a very realistic scenario deals with domain generalization, i.e. the ability to build visual recognition algorithms able to work robustly in several visual domains, without having access to any information about target data statistic. This paper contributes to this research thread, proposing a deep architecture that maintains separated the information about the available source domains data while at the same time leveraging over generic perceptual information. We achieve this by introducing domain-specific aggregation modules that through an aggregation layer strategy are able to merge generic and specific information in an effective manner. Experiments on two different benchmark databases show the power of our approach, reaching the new state of the art in domain generalization.
A recurrent multi-scale approach to RBG-D Object Recognition
Sep 05, 2018
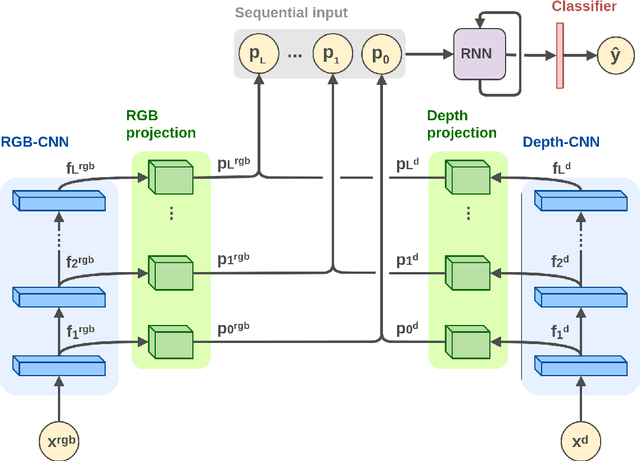
Technological development aims to produce generations of increasingly efficient robots able to perform complex tasks. This requires considerable efforts, from the scientific community, to find new algorithms that solve computer vision problems, such as object recognition. The diffusion of RGB-D cameras directed the study towards the research of new architectures able to exploit the RGB and Depth information. The project that is developed in this thesis concerns the realization of a new end-to-end architecture for the recognition of RGB-D objects called RCFusion. Our method generates compact and highly discriminative multi-modal features by combining complementary RGB and depth information representing different levels of abstraction. We evaluate our method on standard object recognition datasets, RGB-D Object Dataset and JHUIT-50. The experiments performed show that our method outperforms the existing approaches and establishes new state-of-the-art results for both datasets.
Agnostic Domain Generalization
Aug 03, 2018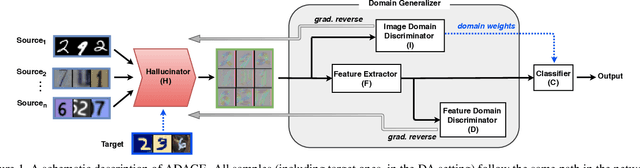

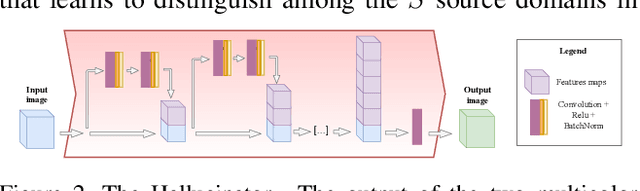
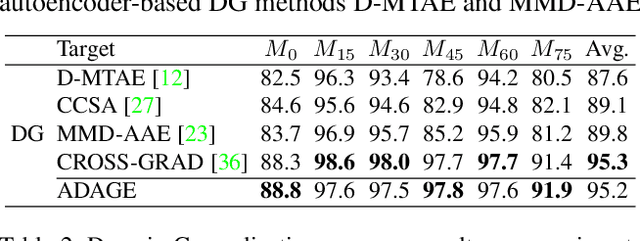
The ability to generalize across visual domains is crucial for the robustness of visual recognition systems in the wild. Several works have been dedicated to close the gap between a single labeled source domain and a target domain with transductive access to its data. In this paper we focus on the wider domain generalization task involving multiple sources and seamlessly extending to unsupervised domain adaptation when unlabeled target samples are available at training time. We propose a hybrid architecture that we name ADAGE: it gracefully maps different source data towards an agnostic visual domain through pixel-adaptation based on a novel incremental architecture, and closes the remaining domain gap through feature adaptation. Both the adaptive processes are guided by adversarial learning. Extensive experiments show remarkable improvements compared to the state of the art.
Multimodal Deep Domain Adaptation
Jul 31, 2018


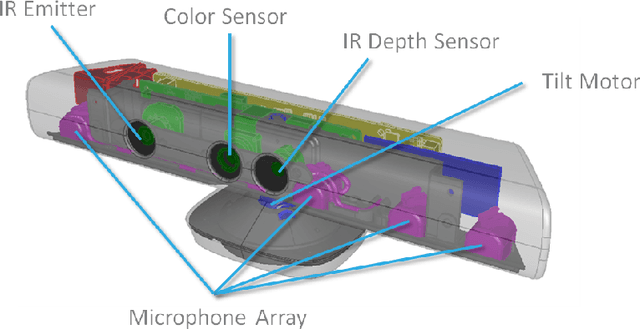
Typically a classifier trained on a given dataset (source domain) does not performs well if it is tested on data acquired in a different setting (target domain). This is the problem that domain adaptation (DA) tries to overcome and, while it is a well explored topic in computer vision, it is largely ignored in robotic vision where usually visual classification methods are trained and tested in the same domain. Robots should be able to deal with unknown environments, recognize objects and use them in the correct way, so it is important to explore the domain adaptation scenario also in this context. The goal of the project is to define a benchmark and a protocol for multi-modal domain adaptation that is valuable for the robot vision community. With this purpose some of the state-of-the-art DA methods are selected: Deep Adaptation Network (DAN), Domain Adversarial Training of Neural Network (DANN), Automatic Domain Alignment Layers (AutoDIAL) and Adversarial Discriminative Domain Adaptation (ADDA). Evaluations have been done using different data types: RGB only, depth only and RGB-D over the following datasets, designed for the robotic community: RGB-D Object Dataset (ROD), Web Object Dataset (WOD), Autonomous Robot Indoor Dataset (ARID), Big Berkeley Instance Recognition Dataset (BigBIRD) and Active Vision Dataset. Although progresses have been made on the formulation of effective adaptation algorithms and more realistic object datasets are available, the results obtained show that, training a sufficiently good object classifier, especially in the domain adaptation scenario, is still an unsolved problem. Also the best way to combine depth with RGB informations to improve the performance is a point that needs to be investigated more.
Recurrent Convolutional Fusion for RGB-D Object Recognition
Jul 12, 2018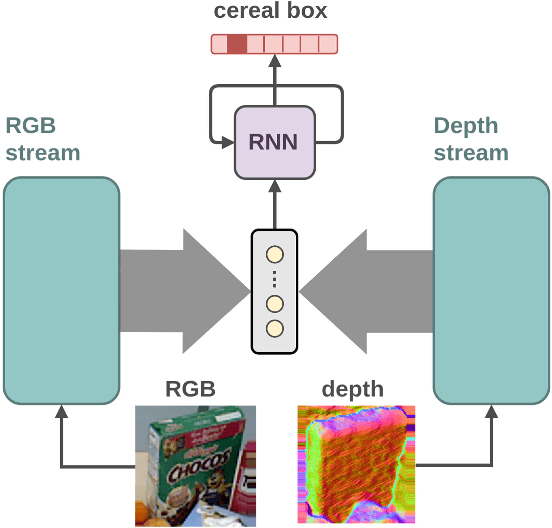
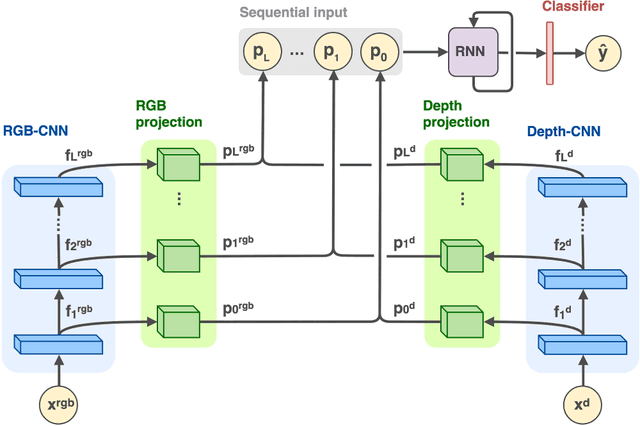
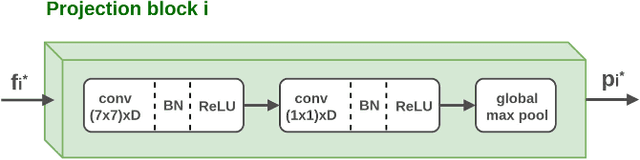
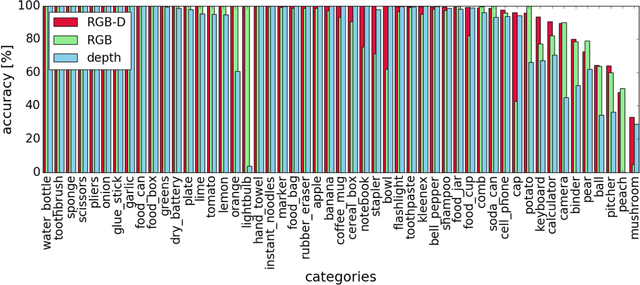
Providing machines with the ability to recognize objects like humans has always been one of the primary goals of machine vision. The introduction of RGB-D cameras has paved the way for a significant leap forward in this direction thanks to the rich information provided by these sensors. However, the machine vision community still lacks an effective method to synergically use the RGB and depth data to improve object recognition. In order to take a step in this direction, we introduce a novel end-to-end architecture for RGB-D object recognition called recurrent convolutional fusion (RCFusion). Our method generates compact and highly discriminative multi-modal features by combining complementary RGB and depth information representing different levels of abstraction. Extensive experiments on two popular datasets, RGB-D Object Dataset and JHUIT-50, show that RCFusion significantly outperforms state-of-the-art approaches in both the object categorization and instance recognition tasks.
Kitting in the Wild through Online Domain Adaptation
Jul 03, 2018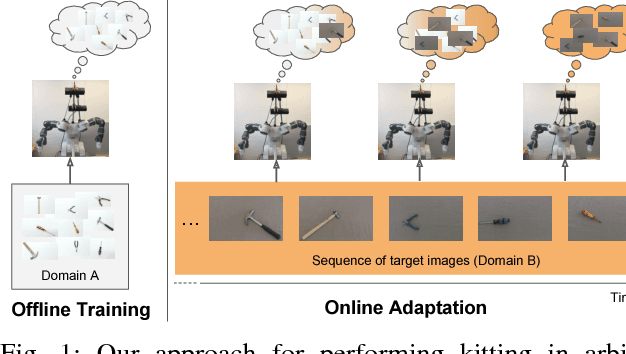

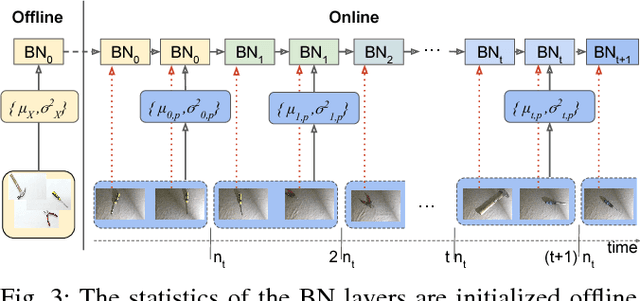
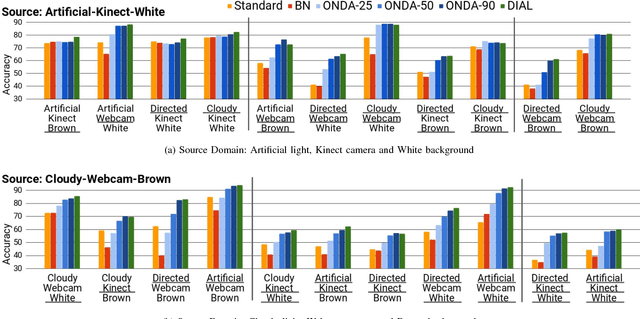
Technological developments call for increasing perception and action capabilities of robots. Among other skills, vision systems that can adapt to any possible change in the working conditions are needed. Since these conditions are unpredictable, we need benchmarks which allow to assess the generalization and robustness capabilities of our visual recognition algorithms. In this work we focus on robotic kitting in unconstrained scenarios. As a first contribution, we present a new visual dataset for the kitting task. Differently from standard object recognition datasets, we provide images of the same objects acquired under various conditions where camera, illumination and background are changed. This novel dataset allows for testing the robustness of robot visual recognition algorithms to a series of different domain shifts both in isolation and unified. Our second contribution is a novel online adaptation algorithm for deep models, based on batch-normalization layers, which allows to continuously adapt a model to the current working conditions. Differently from standard domain adaptation algorithms, it does not require any image from the target domain at training time. We benchmark the performance of the algorithm on the proposed dataset, showing its capability to fill the gap between the performances of a standard architecture and its counterpart adapted offline to the given target domain.
Best sources forward: domain generalization through source-specific nets
Jun 15, 2018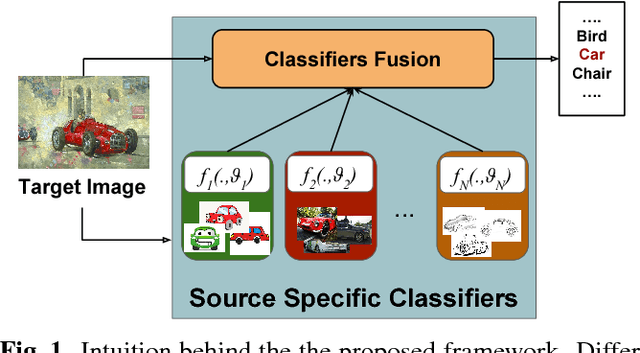
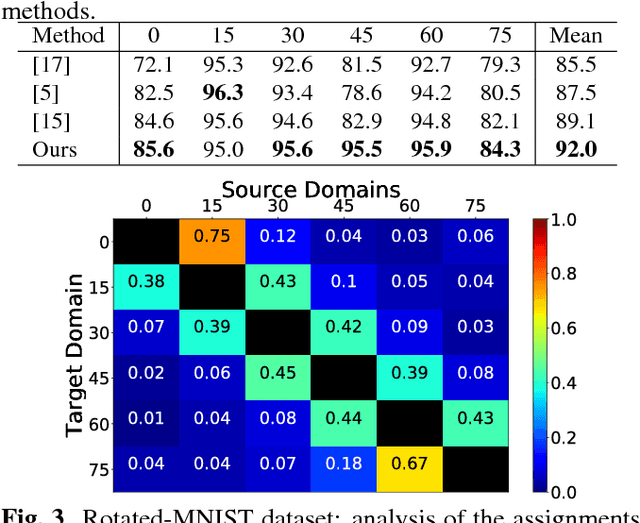
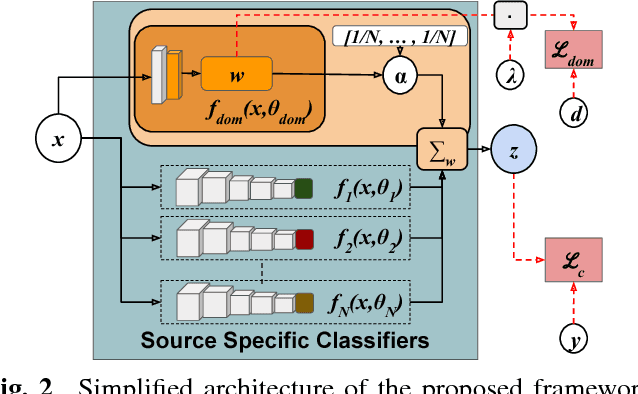
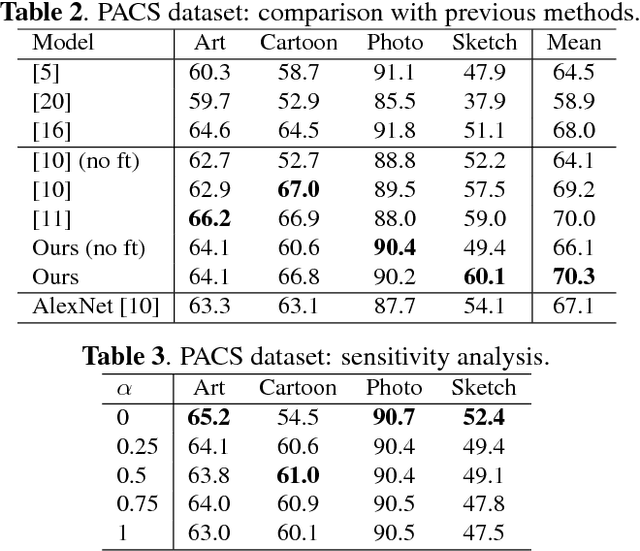
A long standing problem in visual object categorization is the ability of algorithms to generalize across different testing conditions. The problem has been formalized as a covariate shift among the probability distributions generating the training data (source) and the test data (target) and several domain adaptation methods have been proposed to address this issue. While these approaches have considered the single source-single target scenario, it is plausible to have multiple sources and require adaptation to any possible target domain. This last scenario, named Domain Generalization (DG), is the focus of our work. Differently from previous DG methods which learn domain invariant representations from source data, we design a deep network with multiple domain-specific classifiers, each associated to a source domain. At test time we estimate the probabilities that a target sample belongs to each source domain and exploit them to optimally fuse the classifiers predictions. To further improve the generalization ability of our model, we also introduced a domain agnostic component supporting the final classifier. Experiments on two public benchmarks demonstrate the power of our approach.