 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA recurrent multi-scale approach to RBG-D Object Recognition
Paper and Code
Sep 05, 2018
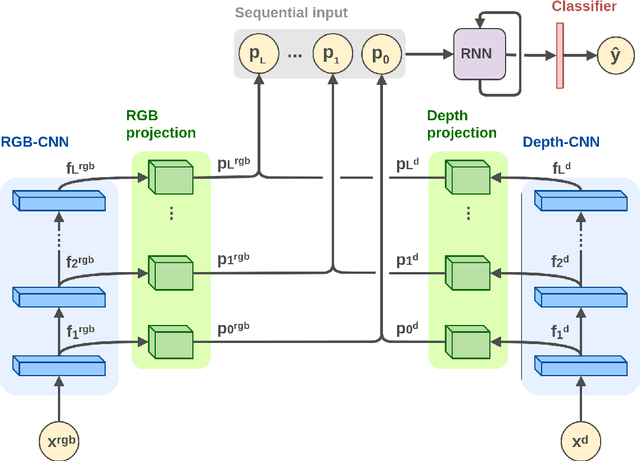
Technological development aims to produce generations of increasingly efficient robots able to perform complex tasks. This requires considerable efforts, from the scientific community, to find new algorithms that solve computer vision problems, such as object recognition. The diffusion of RGB-D cameras directed the study towards the research of new architectures able to exploit the RGB and Depth information. The project that is developed in this thesis concerns the realization of a new end-to-end architecture for the recognition of RGB-D objects called RCFusion. Our method generates compact and highly discriminative multi-modal features by combining complementary RGB and depth information representing different levels of abstraction. We evaluate our method on standard object recognition datasets, RGB-D Object Dataset and JHUIT-50. The experiments performed show that our method outperforms the existing approaches and establishes new state-of-the-art results for both datasets.