 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye Gaze Estimation Model Analysis
Jul 28, 2022
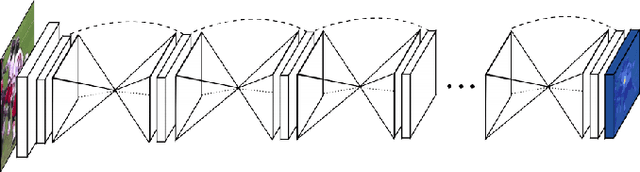
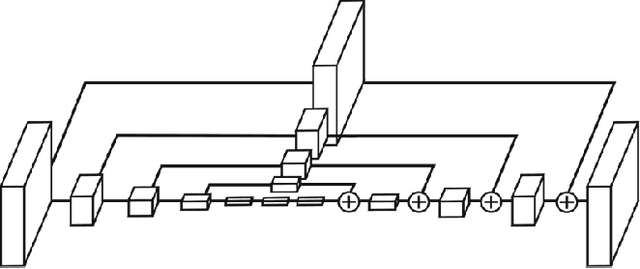
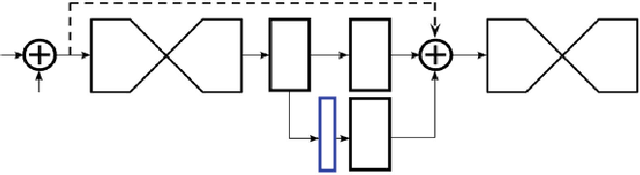
We explore techniques for eye gaze estimation using machine learning. Eye gaze estimation is a common problem for various behavior analysis and human-computer interfaces. The purpose of this work is to discuss various model types for eye gaze estimation and present the results from predicting gaze direction using eye landmarks in unconstrained settings. In unconstrained real-world settings, feature-based and model-based methods are outperformed by recent appearance-based methods due to factors like illumination changes and other visual artifacts. We discuss a learning-based method for eye region landmark localization trained exclusively on synthetic data. We discuss how to use detected landmarks as input to iterative model-fitting and lightweight learning-based gaze estimation methods and how to use the model for person-independent and personalized gaze estimations.
Low Resource Pipeline for Spoken Language Understanding via Weak Supervision
Jun 21, 2022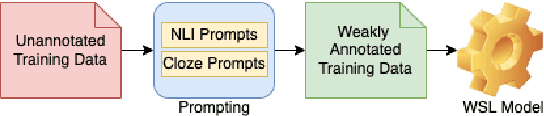
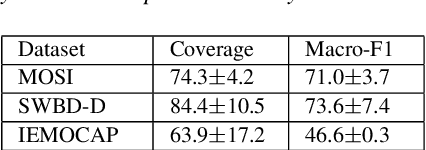
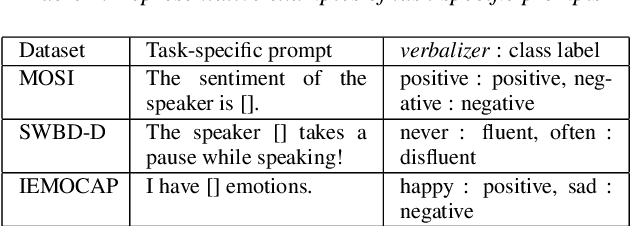

In Weak Supervised Learning (WSL), a model is trained over noisy labels obtained from semantic rules and task-specific pre-trained models. Rules offer limited generalization over tasks and require significant manual efforts while pre-trained models are available only for limited tasks. In this work, we propose to utilize prompt-based methods as weak sources to obtain the noisy labels on unannotated data. We show that task-agnostic prompts are generalizable and can be used to obtain noisy labels for different Spoken Language Understanding (SLU) tasks such as sentiment classification, disfluency detection and emotion classification. These prompts could additionally be updated to add task-specific contexts, thus providing flexibility to design task-specific prompts. We demonstrate that prompt-based methods generate reliable labels for the above SLU tasks and thus can be used as a universal weak source to train a weak-supervised model (WSM) in absence of labeled data. Our proposed WSL pipeline trained over prompt-based weak source outperforms other competitive low-resource benchmarks on zero and few-shot learning by more than 4% on Macro-F1 on all of the three benchmark SLU datasets. The proposed method also outperforms a conventional rule based WSL pipeline by more than 5% on Macro-F1.
Exploring the Limits of Natural Language Inference Based Setup for Few-Shot Intent Detection
Dec 14, 2021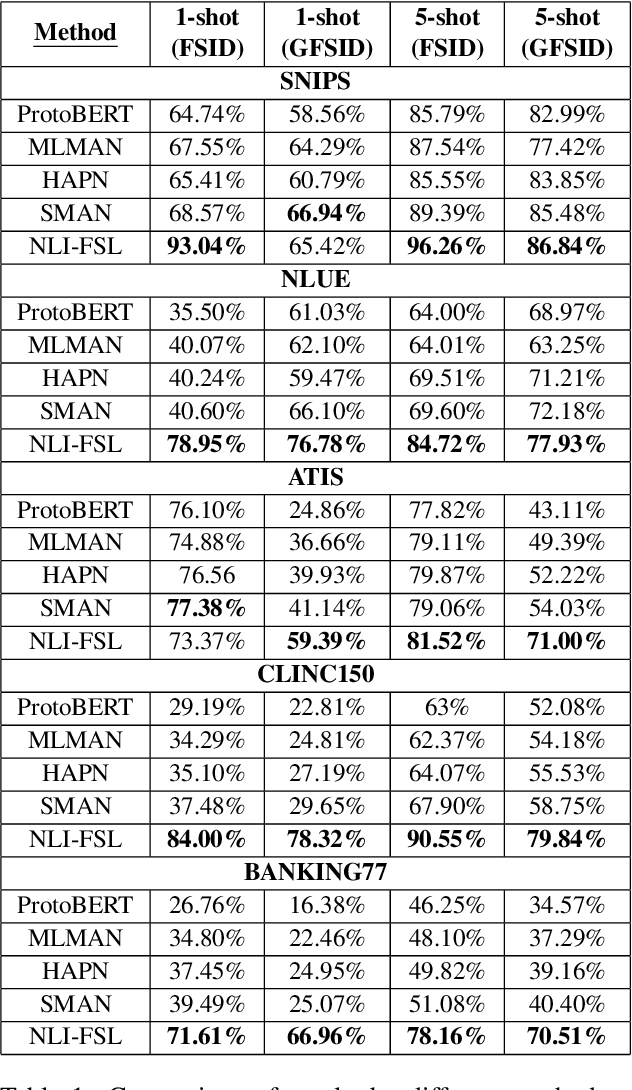
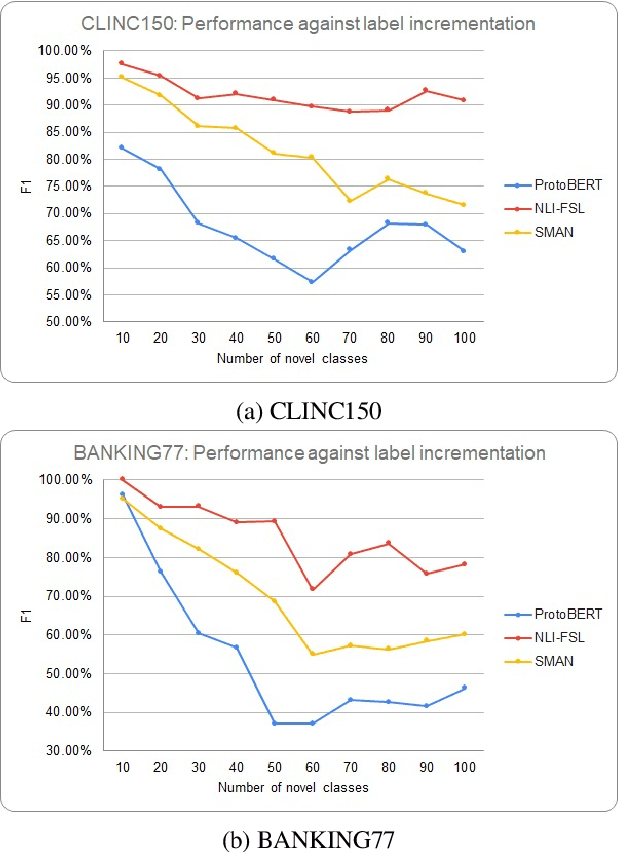
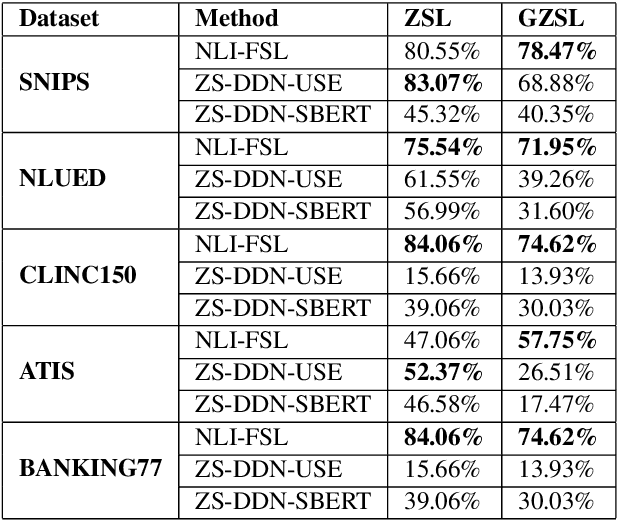
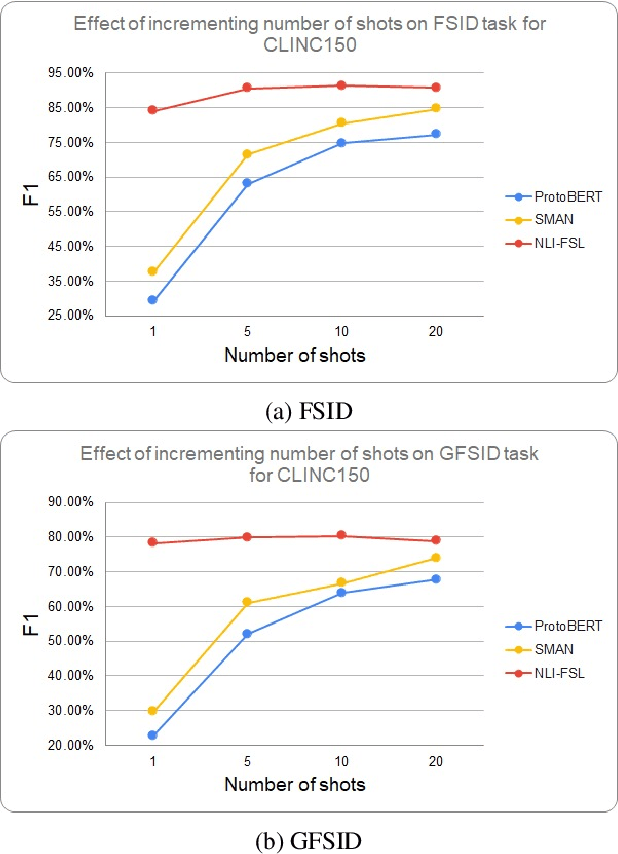
One of the core components of goal-oriented dialog systems is the task of Intent Detection. Few-shot Learning upon Intent Detection is challenging due to the scarcity of available annotated utterances. Although recent works making use of metric-based and optimization-based methods have been proposed, the task is still challenging in large label spaces and much smaller number of shots. Generalized Few-shot learning is more difficult due to the presence of both novel and seen classes during the testing phase. In this work, we propose a simple and effective method based on Natural Language Inference that not only tackles the problem of few shot intent detection, but also proves useful in zero-shot and generalized few shot learning problems. Our extensive experiments on a number of Natural Language Understanding (NLU) and Spoken Language Understanding (SLU) datasets show the effectiveness of our approach. In addition, we highlight the settings in which our NLI based method outperforms the baselines by huge margins.
What BERT Based Language Models Learn in Spoken Transcripts: An Empirical Study
Sep 21, 2021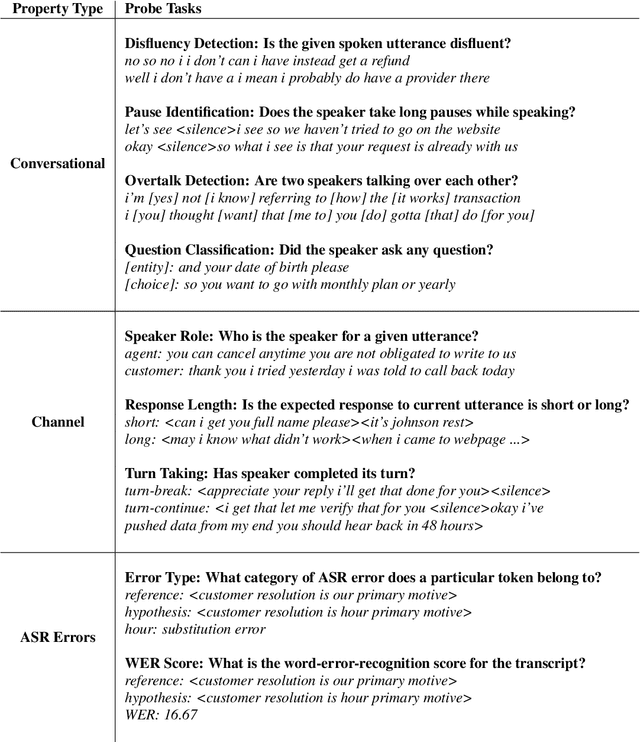
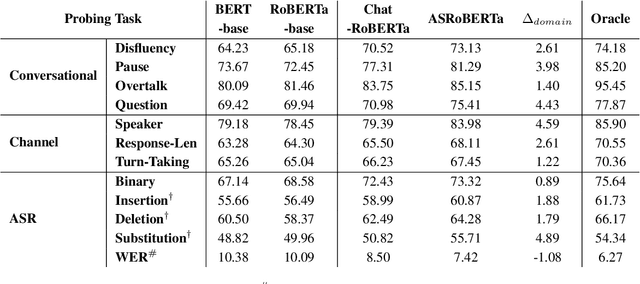
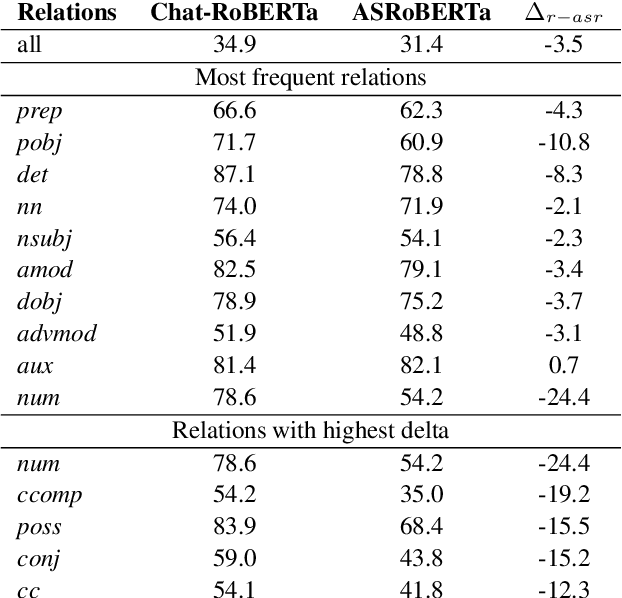
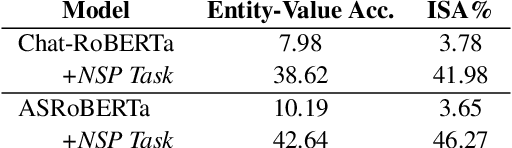
Language Models (LMs) have been ubiquitously leveraged in various tasks including spoken language understanding (SLU). Spoken language requires careful understanding of speaker interactions, dialog states and speech induced multimodal behaviors to generate a meaningful representation of the conversation. In this work, we propose to dissect SLU into three representative properties:conversational (disfluency, pause, overtalk), channel (speaker-type, turn-tasks) and ASR (insertion, deletion,substitution). We probe BERT based language models (BERT, RoBERTa) trained on spoken transcripts to investigate its ability to understand multifarious properties in absence of any speech cues. Empirical results indicate that LM is surprisingly good at capturing conversational properties such as pause prediction and overtalk detection from lexical tokens. On the downsides, the LM scores low on turn-tasks and ASR errors predictions. Additionally, pre-training the LM on spoken transcripts restrain its linguistic understanding. Finally, we establish the efficacy and transferability of the mentioned properties on two benchmark datasets: Switchboard Dialog Act and Disfluency datasets.
Investigating Bias In Automatic Toxic Comment Detection: An Empirical Study
Aug 14, 2021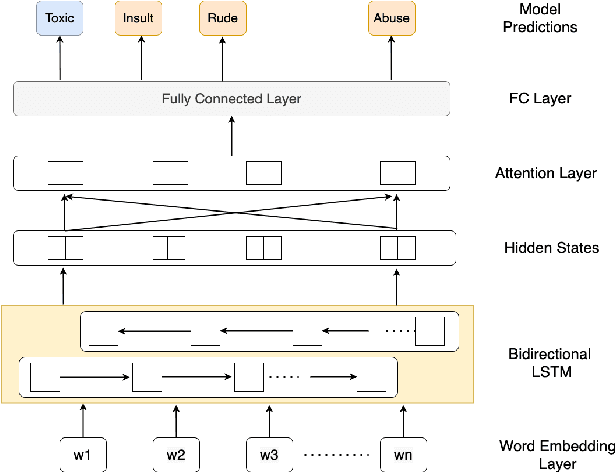
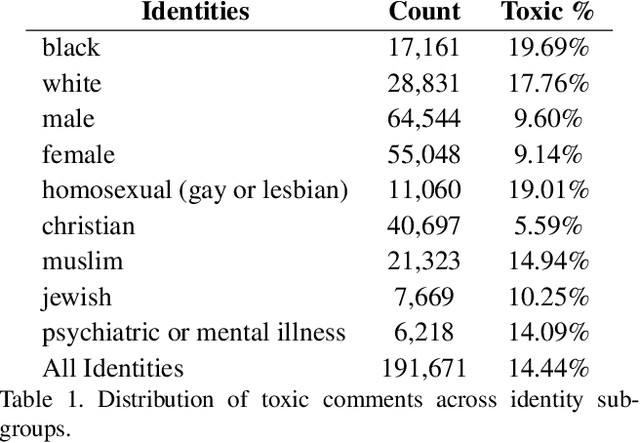
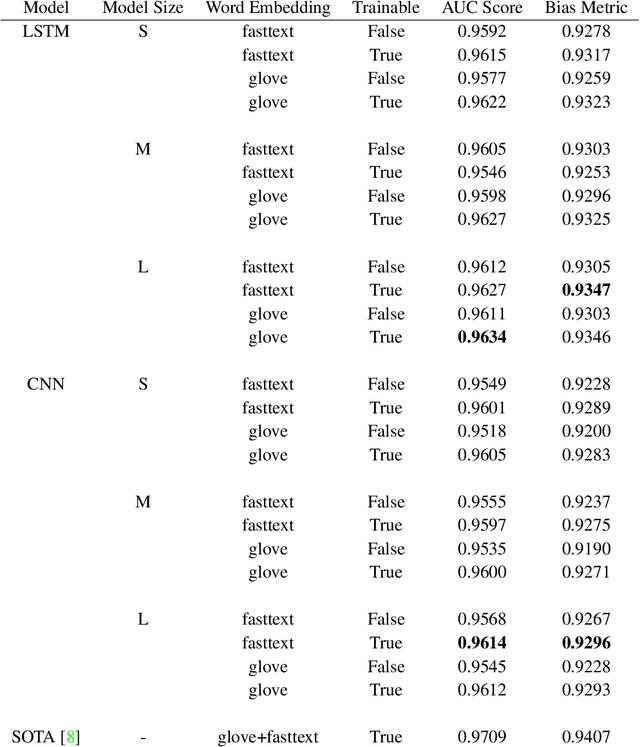
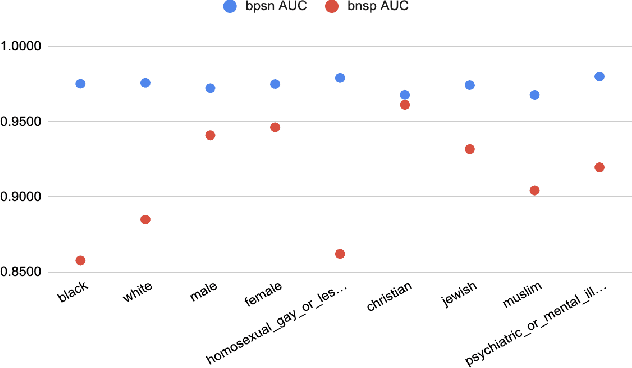
With surge in online platforms, there has been an upsurge in the user engagement on these platforms via comments and reactions. A large portion of such textual comments are abusive, rude and offensive to the audience. With machine learning systems in-place to check such comments coming onto platform, biases present in the training data gets passed onto the classifier leading to discrimination against a set of classes, religion and gender. In this work, we evaluate different classifiers and feature to estimate the bias in these classifiers along with their performance on downstream task of toxicity classification. Results show that improvement in performance of automatic toxic comment detection models is positively correlated to mitigating biases in these models. In our work, LSTM with attention mechanism proved to be a better modelling strategy than a CNN model. Further analysis shows that fasttext embeddings is marginally preferable than glove embeddings on training models for toxicity comment detection. Deeper analysis reveals the findings that such automatic models are particularly biased to specific identity groups even though the model has a high AUC score. Finally, in effort to mitigate bias in toxicity detection models, a multi-task setup trained with auxiliary task of toxicity sub-types proved to be useful leading to upto 0.26% (6% relative) gain in AUC scores.
Document Structure aware Relational Graph Convolutional Networks for Ontology Population
Apr 27, 2021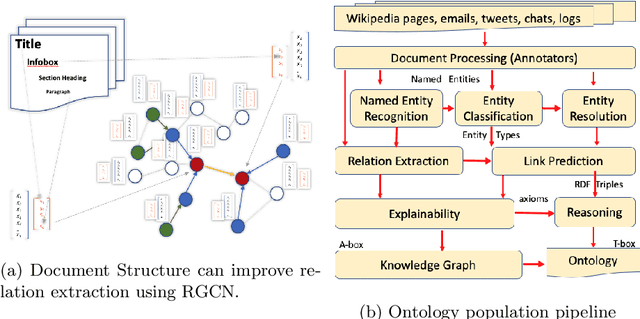
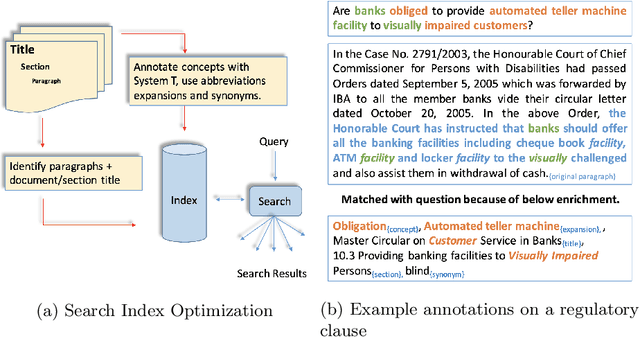
Ontologies comprising of concepts, their attributes, and relationships, form the quintessential backbone of many knowledge based AI systems. These systems manifest in the form of question-answering or dialogue in number of business analytics and master data management applications. While there have been efforts towards populating domain specific ontologies, we examine the role of document structure in learning ontological relationships between concepts in any document corpus. Inspired by ideas from hypernym discovery and explainability, our method performs about 15 points more accurate than a stand-alone R-GCN model for this task.
Phoneme-BERT: Joint Language Modelling of Phoneme Sequence and ASR Transcript
Feb 01, 2021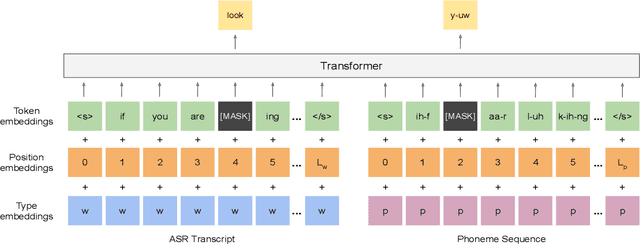
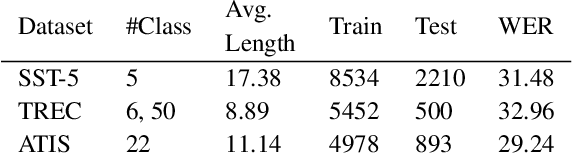
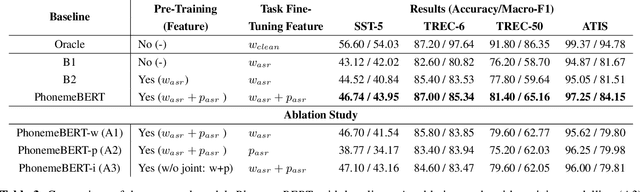
Recent years have witnessed significant improvement in ASR systems to recognize spoken utterances. However, it is still a challenging task for noisy and out-of-domain data, where substitution and deletion errors are prevalent in the transcribed text. These errors significantly degrade the performance of downstream tasks. In this work, we propose a BERT-style language model, referred to as PhonemeBERT, that learns a joint language model with phoneme sequence and ASR transcript to learn phonetic-aware representations that are robust to ASR errors. We show that PhonemeBERT can be used on downstream tasks using phoneme sequences as additional features, and also in low-resource setup where we only have ASR-transcripts for the downstream tasks with no phoneme information available. We evaluate our approach extensively by generating noisy data for three benchmark datasets - Stanford Sentiment Treebank, TREC and ATIS for sentiment, question and intent classification tasks respectively. The results of the proposed approach beats the state-of-the-art baselines comprehensively on each dataset.
Chitrakar: Robotic System for Drawing Jordan Curve of Facial Portrait
Nov 21, 2020

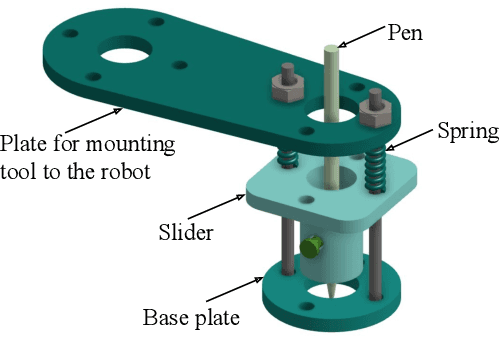
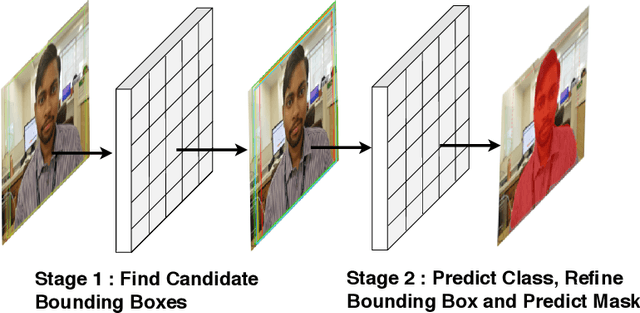
This paper presents a robotic system (\textit{Chitrakar}) which autonomously converts any image of a human face to a recognizable non-self-intersecting loop (Jordan Curve) and draws it on any planar surface. The image is processed using Mask R-CNN for instance segmentation, Laplacian of Gaussian (LoG) for feature enhancement and intensity-based probabilistic stippling for the image to points conversion. These points are treated as a destination for a travelling salesman and are connected with an optimal path which is calculated heuristically by minimizing the total distance to be travelled. This path is converted to a Jordan Curve in feasible time by removing intersections using a combination of image processing, 2-opt, and Bresenham's Algorithm. The robotic system generates $n$ instances of each image for human aesthetic judgement, out of which the most appealing instance is selected for the final drawing. The drawing is executed carefully by the robot's arm using trapezoidal velocity profiles for jerk-free and fast motion. The drawing, with a decent resolution, can be completed in less than 30 minutes which is impossible to do by hand. This work demonstrates the use of robotics to augment humans in executing difficult craft-work instead of replacing them altogether.
Machine Learning-Based Early Detection of IoT Botnets Using Network-Edge Traffic
Oct 22, 2020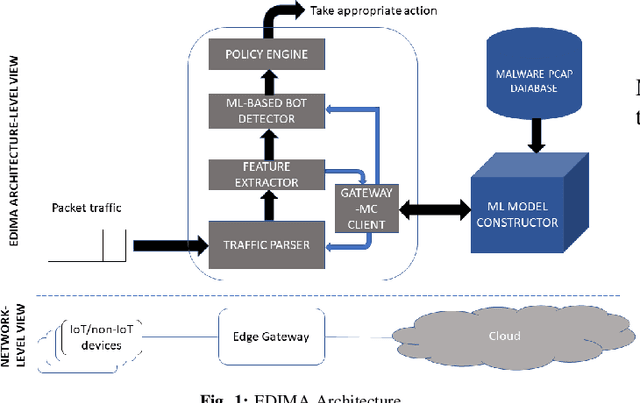

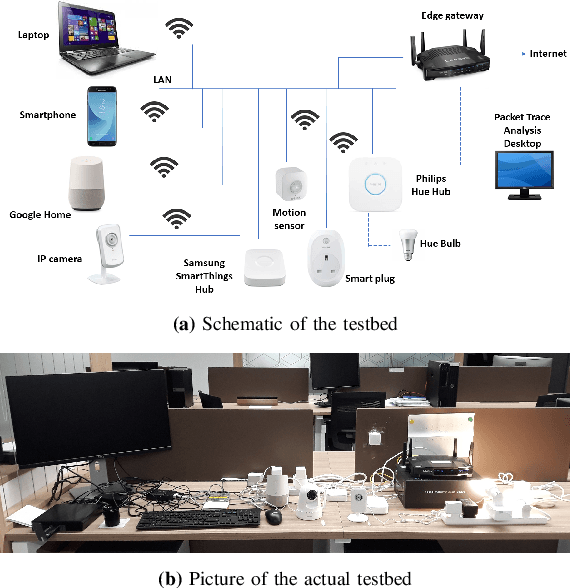
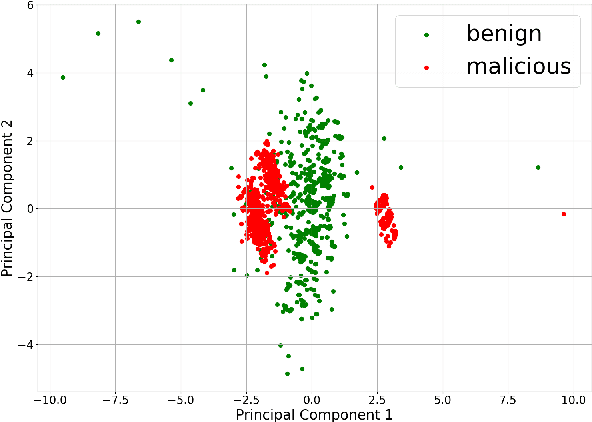
In this work, we present a lightweight IoT botnet detection solution, EDIMA, which is designed to be deployed at the edge gateway installed in home networks and targets early detection of botnets prior to the launch of an attack. EDIMA includes a novel two-stage Machine Learning (ML)-based detector developed specifically for IoT bot detection at the edge gateway. The ML-based bot detector first employs ML algorithms for aggregate traffic classification and subsequently Autocorrelation Function (ACF)-based tests to detect individual bots. The EDIMA architecture also comprises a malware traffic database, a policy engine, a feature extractor and a traffic parser. Performance evaluation results show that EDIMA achieves high bot scanning and bot-CnC traffic detection accuracies with very low false positive rates. The detection performance is also shown to be robust to an increase in the number of IoT devices connected to the edge gateway where EDIMA is deployed. Further, the runtime performance analysis of a Python implementation of EDIMA deployed on a Raspberry Pi reveals low bot detection delays and low RAM consumption. EDIMA is also shown to outperform existing detection techniques for bot scanning traffic and bot-CnC server communication.
BAKSA at SemEval-2020 Task 9: Bolstering CNN with Self-Attention for Sentiment Analysis of Code Mixed Text
Jul 21, 2020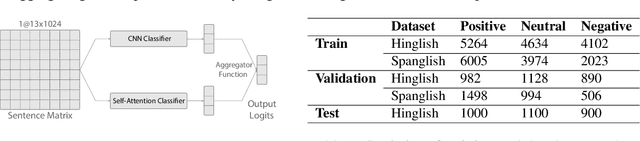
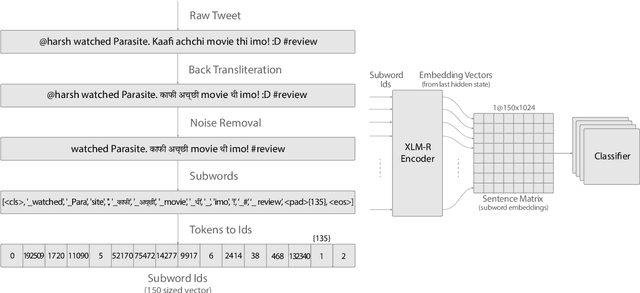
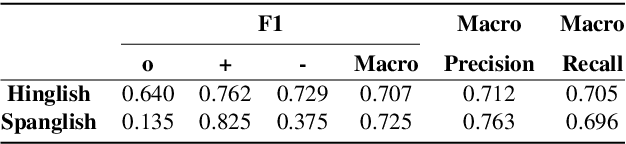
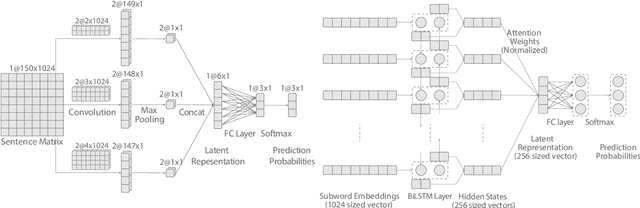
Sentiment Analysis of code-mixed text has diversified applications in opinion mining ranging from tagging user reviews to identifying social or political sentiments of a sub-population. In this paper, we present an ensemble architecture of convolutional neural net (CNN) and self-attention based LSTM for sentiment analysis of code-mixed tweets. While the CNN component helps in the classification of positive and negative tweets, the self-attention based LSTM, helps in the classification of neutral tweets, because of its ability to identify correct sentiment among multiple sentiment bearing units. We achieved F1 scores of 0.707 (ranked 5th) and 0.725 (ranked 13th) on Hindi-English (Hinglish) and Spanish-English (Spanglish) datasets, respectively. The submissions for Hinglish and Spanglish tasks were made under the usernames ayushk and harsh_6 respectively.