 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Language-Vision AI Models Pretrained on Web-Scraped Multimodal Data Exhibit Sexual Objectification Bias
Dec 21, 2022



Nine language-vision AI models trained on web scrapes with the Contrastive Language-Image Pretraining (CLIP) objective are evaluated for evidence of a bias studied by psychologists: the sexual objectification of girls and women, which occurs when a person's human characteristics are disregarded and the person is treated as a body or a collection of body parts. A first experiment uses standardized images of women from the Sexual OBjectification and EMotion Database, and finds that, commensurate with prior research in psychology, human characteristics are disassociated from images of objectified women: the model's recognition of emotional state is mediated by whether the subject is fully or partially clothed. Embedding association tests (EATs) return significant effect sizes for both anger (d >.8) and sadness (d >.5). A second experiment measures the effect in a representative application: an automatic image captioner (Antarctic Captions) includes words denoting emotion less than 50% as often for images of partially clothed women than for images of fully clothed women. A third experiment finds that images of female professionals (scientists, doctors, executives) are likely to be associated with sexual descriptions relative to images of male professionals. A fourth experiment shows that a prompt of "a [age] year old girl" generates sexualized images (as determined by an NSFW classifier) up to 73% of the time for VQGAN-CLIP (age 17), and up to 40% of the time for Stable Diffusion (ages 14 and 18); the corresponding rate for boys never surpasses 9%. The evidence indicates that language-vision AI models trained on automatically collected web scrapes learn biases of sexual objectification, which propagate to downstream applications.
Easily Accessible Text-to-Image Generation Amplifies Demographic Stereotypes at Large Scale
Nov 07, 2022



Machine learning models are now able to convert user-written text descriptions into naturalistic images. These models are available to anyone online and are being used to generate millions of images a day. We investigate these models and find that they amplify dangerous and complex stereotypes. Moreover, we find that the amplified stereotypes are difficult to predict and not easily mitigated by users or model owners. The extent to which these image-generation models perpetuate and amplify stereotypes and their mass deployment is cause for serious concern.
American == White in Multimodal Language-and-Image AI
Jul 01, 2022
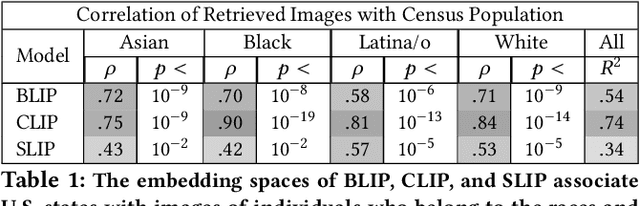
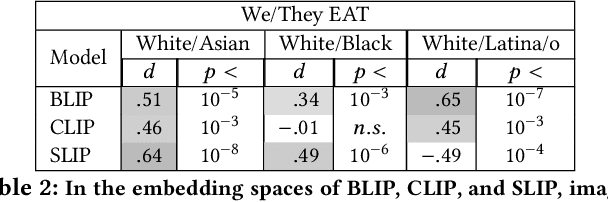
Three state-of-the-art language-and-image AI models, CLIP, SLIP, and BLIP, are evaluated for evidence of a bias previously observed in social and experimental psychology: equating American identity with being White. Embedding association tests (EATs) using standardized images of self-identified Asian, Black, Latina/o, and White individuals from the Chicago Face Database (CFD) reveal that White individuals are more associated with collective in-group words than are Asian, Black, or Latina/o individuals. In assessments of three core aspects of American identity reported by social psychologists, single-category EATs reveal that images of White individuals are more associated with patriotism and with being born in America, but that, consistent with prior findings in psychology, White individuals are associated with being less likely to treat people of all races and backgrounds equally. Three downstream machine learning tasks demonstrate biases associating American with White. In a visual question answering task using BLIP, 97% of White individuals are identified as American, compared to only 3% of Asian individuals. When asked in what state the individual depicted lives in, the model responds China 53% of the time for Asian individuals, but always with an American state for White individuals. In an image captioning task, BLIP remarks upon the race of Asian individuals as much as 36% of the time, but never remarks upon race for White individuals. Finally, provided with an initialization image from the CFD and the text "an American person," a synthetic image generator (VQGAN) using the text-based guidance of CLIP lightens the skin tone of individuals of all races (by 35% for Black individuals, based on pixel brightness). The results indicate that biases equating American identity with being White are learned by language-and-image AI, and propagate to downstream applications of such models.
Gender Bias in Word Embeddings: A Comprehensive Analysis of Frequency, Syntax, and Semantics
Jun 07, 2022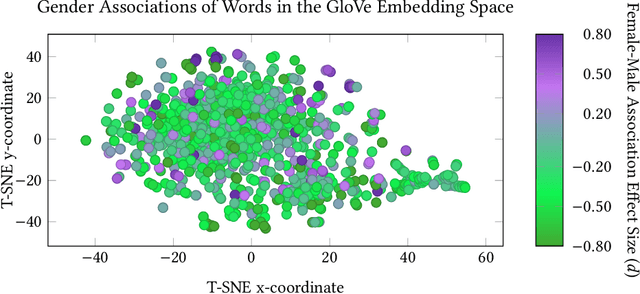
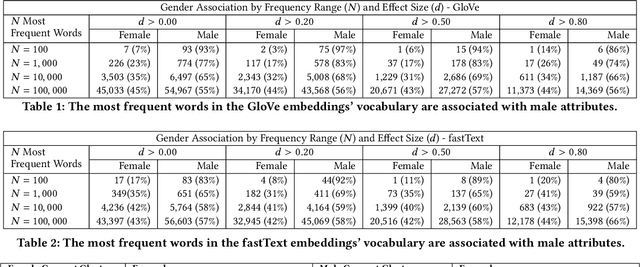
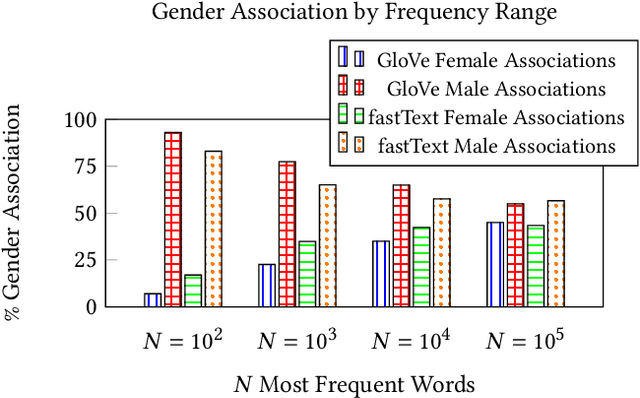
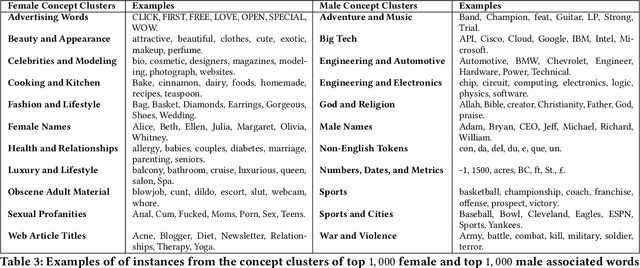
The statistical regularities in language corpora encode well-known social biases into word embeddings. Here, we focus on gender to provide a comprehensive analysis of group-based biases in widely-used static English word embeddings trained on internet corpora (GloVe 2014, fastText 2017). Using the Single-Category Word Embedding Association Test, we demonstrate the widespread prevalence of gender biases that also show differences in: (1) frequencies of words associated with men versus women; (b) part-of-speech tags in gender-associated words; (c) semantic categories in gender-associated words; and (d) valence, arousal, and dominance in gender-associated words. First, in terms of word frequency: we find that, of the 1,000 most frequent words in the vocabulary, 77% are more associated with men than women, providing direct evidence of a masculine default in the everyday language of the English-speaking world. Second, turning to parts-of-speech: the top male-associated words are typically verbs (e.g., fight, overpower) while the top female-associated words are typically adjectives and adverbs (e.g., giving, emotionally). Gender biases in embeddings also permeate parts-of-speech. Third, for semantic categories: bottom-up, cluster analyses of the top 1,000 words associated with each gender. The top male-associated concepts include roles and domains of big tech, engineering, religion, sports, and violence; in contrast, the top female-associated concepts are less focused on roles, including, instead, female-specific slurs and sexual content, as well as appearance and kitchen terms. Fourth, using human ratings of word valence, arousal, and dominance from a ~20,000 word lexicon, we find that male-associated words are higher on arousal and dominance, while female-associated words are higher on valence.
Measuring Gender Bias in Word Embeddings of Gendered Languages Requires Disentangling Grammatical Gender Signals
Jun 03, 2022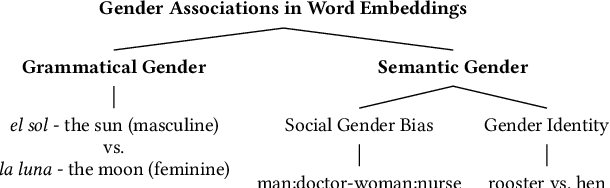

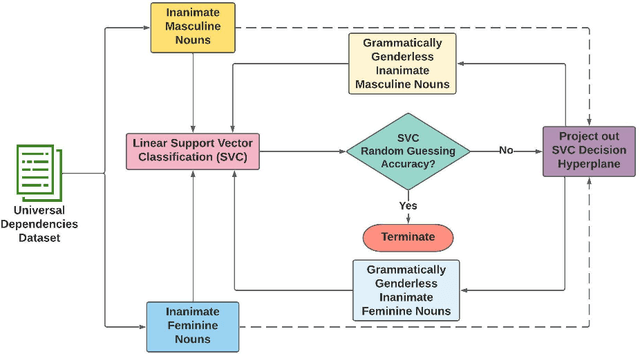
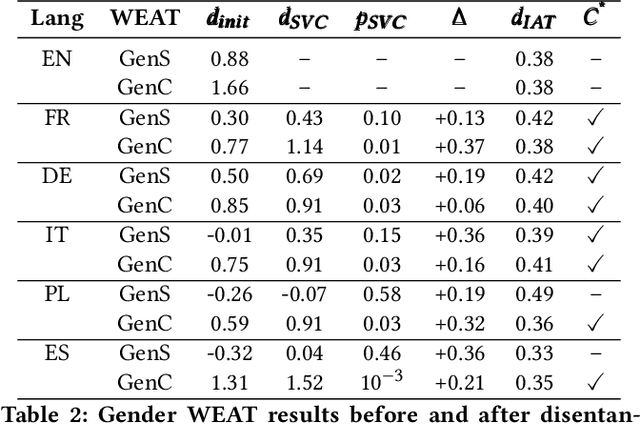
Does the grammatical gender of a language interfere when measuring the semantic gender information captured by its word embeddings? A number of anomalous gender bias measurements in the embeddings of gendered languages suggest this possibility. We demonstrate that word embeddings learn the association between a noun and its grammatical gender in grammatically gendered languages, which can skew social gender bias measurements. Consequently, word embedding post-processing methods are introduced to quantify, disentangle, and evaluate grammatical gender signals. The evaluation is performed on five gendered languages from the Germanic, Romance, and Slavic branches of the Indo-European language family. Our method reduces the strength of grammatical gender signals, which is measured in terms of effect size (Cohen's d), by a significant average of d = 1.3 for French, German, and Italian, and d = 0.56 for Polish and Spanish. Once grammatical gender is disentangled, the association between over 90% of 10,000 inanimate nouns and their assigned grammatical gender weakens, and cross-lingual bias results from the Word Embedding Association Test (WEAT) become more congruent with country-level implicit bias measurements. The results further suggest that disentangling grammatical gender signals from word embeddings may lead to improvement in semantic machine learning tasks.
Markedness in Visual Semantic AI
May 23, 2022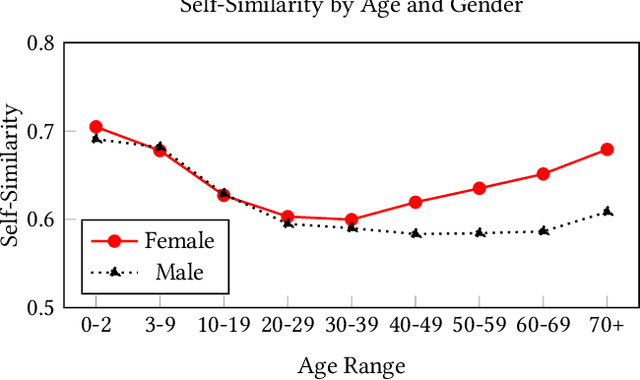
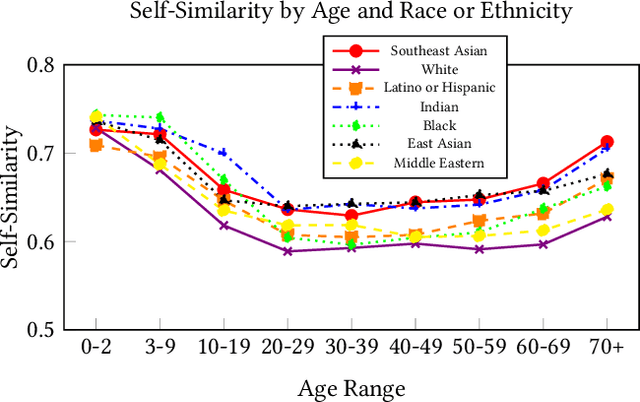

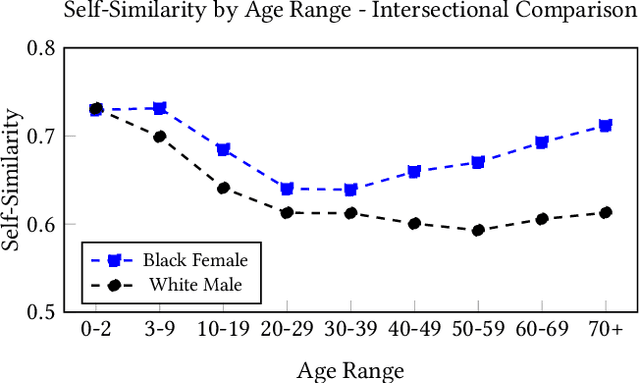
We evaluate the state-of-the-art multimodal "visual semantic" model CLIP ("Contrastive Language Image Pretraining") for biases related to the marking of age, gender, and race or ethnicity. Given the option to label an image as "a photo of a person" or to select a label denoting race or ethnicity, CLIP chooses the "person" label 47.9% of the time for White individuals, compared with 5.0% or less for individuals who are Black, East Asian, Southeast Asian, Indian, or Latino or Hispanic. The model is more likely to rank the unmarked "person" label higher than labels denoting gender for Male individuals (26.7% of the time) vs. Female individuals (15.2% of the time). Age affects whether an individual is marked by the model: Female individuals under the age of 20 are more likely than Male individuals to be marked with a gender label, but less likely to be marked with an age label, while Female individuals over the age of 40 are more likely to be marked based on age than Male individuals. We also examine the self-similarity (mean pairwise cosine similarity) for each social group, where higher self-similarity denotes greater attention directed by CLIP to the shared characteristics (age, race, or gender) of the social group. As age increases, the self-similarity of representations of Female individuals increases at a higher rate than for Male individuals, with the disparity most pronounced at the "more than 70" age range. All ten of the most self-similar social groups are individuals under the age of 10 or over the age of 70, and six of the ten are Female individuals. Existing biases of self-similarity and markedness between Male and Female gender groups are further exacerbated when the groups compared are individuals who are White and Male and individuals who are Black and Female. Results indicate that CLIP reflects the biases of the language and society which produced its training data.
Evidence for Hypodescent in Visual Semantic AI
May 22, 2022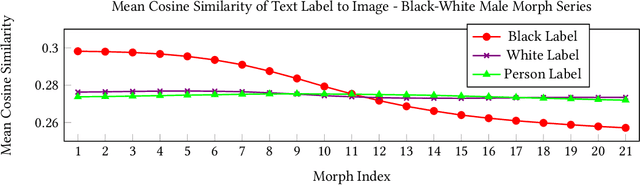
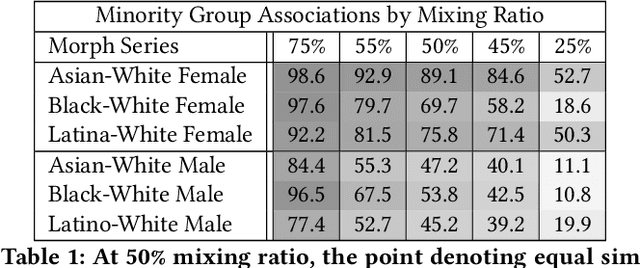

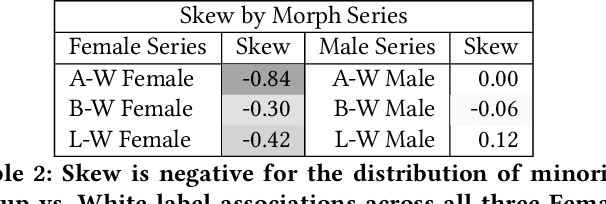
We examine the state-of-the-art multimodal "visual semantic" model CLIP ("Contrastive Language Image Pretraining") for the rule of hypodescent, or one-drop rule, whereby multiracial people are more likely to be assigned a racial or ethnic label corresponding to a minority or disadvantaged racial or ethnic group than to the equivalent majority or advantaged group. A face morphing experiment grounded in psychological research demonstrating hypodescent indicates that, at the midway point of 1,000 series of morphed images, CLIP associates 69.7% of Black-White female images with a Black text label over a White text label, and similarly prefers Latina (75.8%) and Asian (89.1%) text labels at the midway point for Latina-White female and Asian-White female morphs, reflecting hypodescent. Additionally, assessment of the underlying cosine similarities in the model reveals that association with White is correlated with association with "person," with Pearson's rho as high as 0.82 over a 21,000-image morph series, indicating that a White person corresponds to the default representation of a person in CLIP. Finally, we show that the stereotype-congruent pleasantness association of an image correlates with association with the Black text label in CLIP, with Pearson's rho = 0.48 for 21,000 Black-White multiracial male images, and rho = 0.41 for Black-White multiracial female images. CLIP is trained on English-language text gathered using data collected from an American website (Wikipedia), and our findings demonstrate that CLIP embeds the values of American racial hierarchy, reflecting the implicit and explicit beliefs that are present in human minds. We contextualize these findings within the history and psychology of hypodescent. Overall, the data suggests that AI supervised using natural language will, unless checked, learn biases that reflect racial hierarchies.
Contrastive Visual Semantic Pretraining Magnifies the Semantics of Natural Language Representations
Mar 14, 2022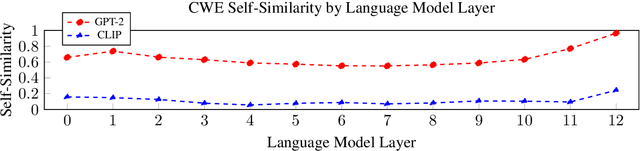
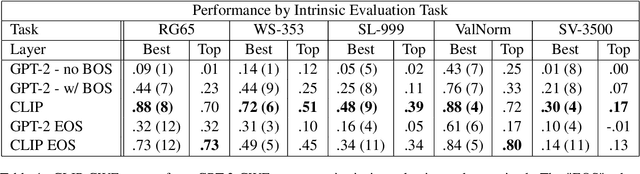
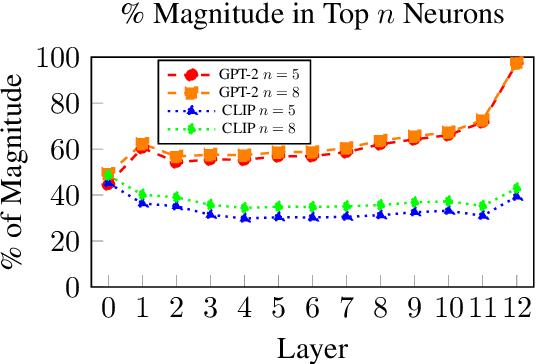
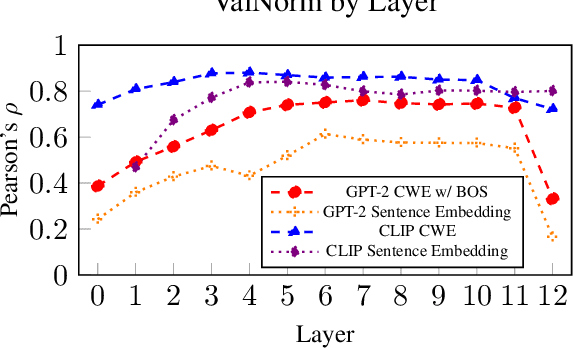
We examine the effects of contrastive visual semantic pretraining by comparing the geometry and semantic properties of contextualized English language representations formed by GPT-2 and CLIP, a zero-shot multimodal image classifier which adapts the GPT-2 architecture to encode image captions. We find that contrastive visual semantic pretraining significantly mitigates the anisotropy found in contextualized word embeddings from GPT-2, such that the intra-layer self-similarity (mean pairwise cosine similarity) of CLIP word embeddings is under .25 in all layers, compared to greater than .95 in the top layer of GPT-2. CLIP word embeddings outperform GPT-2 on word-level semantic intrinsic evaluation tasks, and achieve a new corpus-based state of the art for the RG65 evaluation, at .88. CLIP also forms fine-grained semantic representations of sentences, and obtains Spearman's rho = .73 on the SemEval-2017 Semantic Textual Similarity Benchmark with no fine-tuning, compared to no greater than rho = .45 in any layer of GPT-2. Finally, intra-layer self-similarity of CLIP sentence embeddings decreases as the layer index increases, finishing at .25 in the top layer, while the self-similarity of GPT-2 sentence embeddings formed using the EOS token increases layer-over-layer and never falls below .97. Our results indicate that high anisotropy is not an inevitable consequence of contextualization, and that visual semantic pretraining is beneficial not only for ordering visual representations, but also for encoding useful semantic representations of language, both on the word level and the sentence level.
VAST: The Valence-Assessing Semantics Test for Contextualizing Language Models
Mar 14, 2022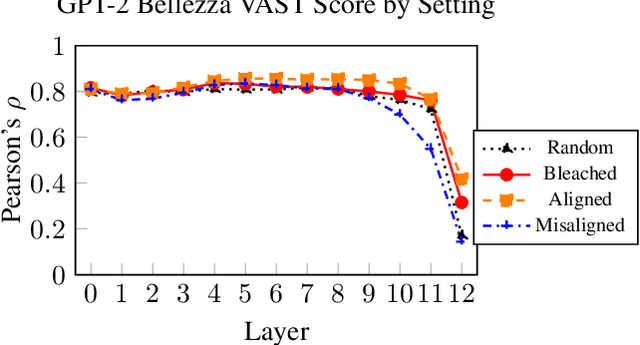

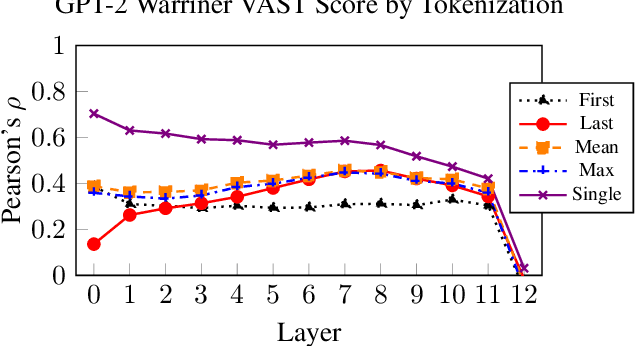
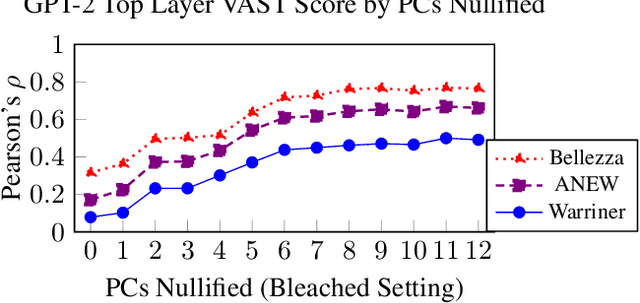
VAST, the Valence-Assessing Semantics Test, is a novel intrinsic evaluation task for contextualized word embeddings (CWEs). VAST uses valence, the association of a word with pleasantness, to measure the correspondence of word-level LM semantics with widely used human judgments, and examines the effects of contextualization, tokenization, and LM-specific geometry. Because prior research has found that CWEs from GPT-2 perform poorly on other intrinsic evaluations, we select GPT-2 as our primary subject, and include results showing that VAST is useful for 7 other LMs, and can be used in 7 languages. GPT-2 results show that the semantics of a word incorporate the semantics of context in layers closer to model output, such that VAST scores diverge between our contextual settings, ranging from Pearson's rho of .55 to .77 in layer 11. We also show that multiply tokenized words are not semantically encoded until layer 8, where they achieve Pearson's rho of .46, indicating the presence of an encoding process for multiply tokenized words which differs from that of singly tokenized words, for which rho is highest in layer 0. We find that a few neurons with values having greater magnitude than the rest mask word-level semantics in GPT-2's top layer, but that word-level semantics can be recovered by nullifying non-semantic principal components: Pearson's rho in the top layer improves from .32 to .76. After isolating semantics, we show the utility of VAST for understanding LM semantics via improvements over related work on four word similarity tasks, with a score of .50 on SimLex-999, better than the previous best of .45 for GPT-2. Finally, we show that 8 of 10 WEAT bias tests, which compare differences in word embedding associations between groups of words, exhibit more stereotype-congruent biases after isolating semantics, indicating that non-semantic structures in LMs also mask biases.
Low Frequency Names Exhibit Bias and Overfitting in Contextualizing Language Models
Oct 01, 2021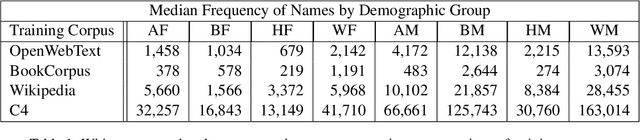
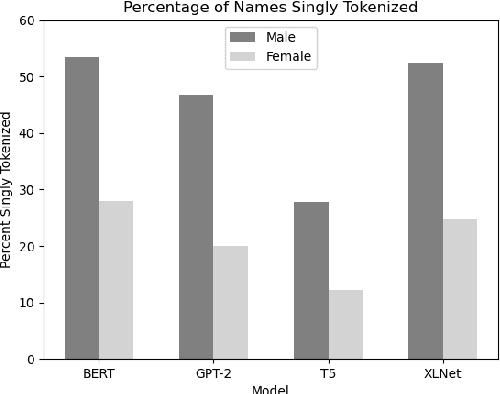
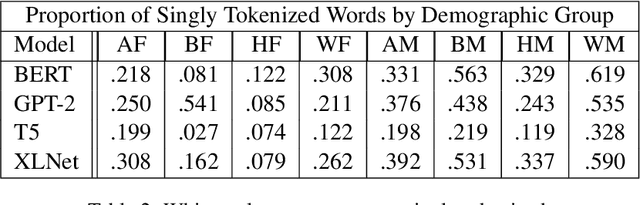
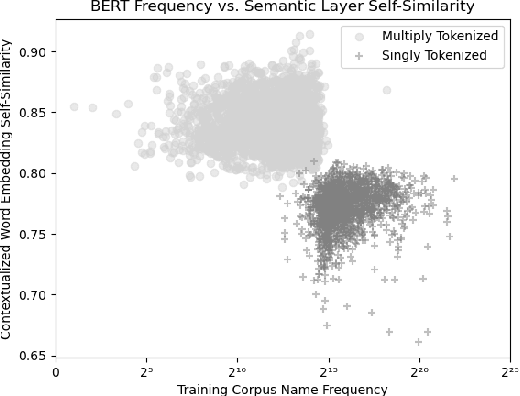
We use a dataset of U.S. first names with labels based on predominant gender and racial group to examine the effect of training corpus frequency on tokenization, contextualization, similarity to initial representation, and bias in BERT, GPT-2, T5, and XLNet. We show that predominantly female and non-white names are less frequent in the training corpora of these four language models. We find that infrequent names are more self-similar across contexts, with Spearman's r between frequency and self-similarity as low as -.763. Infrequent names are also less similar to initial representation, with Spearman's r between frequency and linear centered kernel alignment (CKA) similarity to initial representation as high as .702. Moreover, we find Spearman's r between racial bias and name frequency in BERT of .492, indicating that lower-frequency minority group names are more associated with unpleasantness. Representations of infrequent names undergo more processing, but are more self-similar, indicating that models rely on less context-informed representations of uncommon and minority names which are overfit to a lower number of observed contexts.
* 15 pages, 3 figures, 8 tables