 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging redundancy in attention with Reuse Transformers
Oct 13, 2021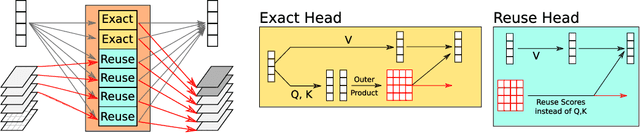
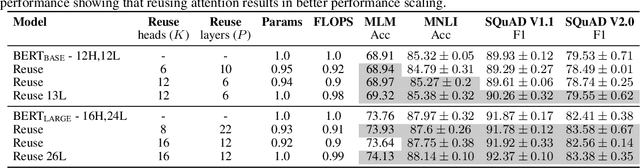
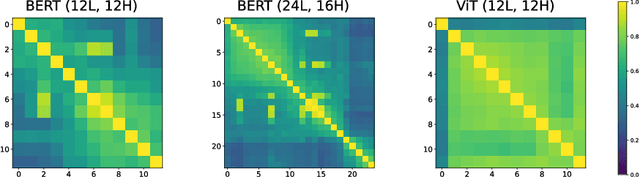
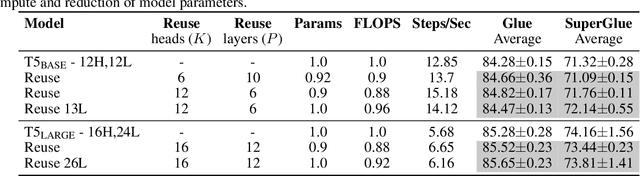
Pairwise dot product-based attention allows Transformers to exchange information between tokens in an input-dependent way, and is key to their success across diverse applications in language and vision. However, a typical Transformer model computes such pairwise attention scores repeatedly for the same sequence, in multiple heads in multiple layers. We systematically analyze the empirical similarity of these scores across heads and layers and find them to be considerably redundant, especially adjacent layers showing high similarity. Motivated by these findings, we propose a novel architecture that reuses attention scores computed in one layer in multiple subsequent layers. Experiments on a number of standard benchmarks show that reusing attention delivers performance equivalent to or better than standard transformers, while reducing both compute and memory usage.
Eigen Analysis of Self-Attention and its Reconstruction from Partial Computation
Jun 16, 2021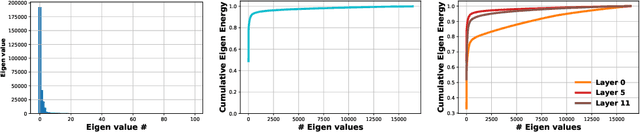
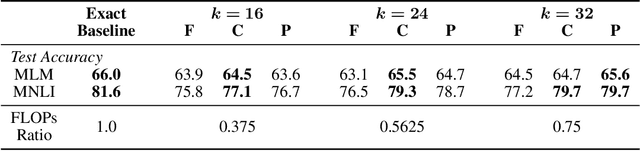
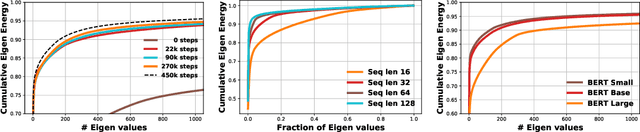
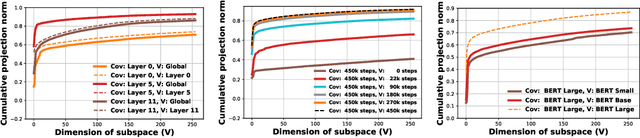
State-of-the-art transformer models use pairwise dot-product based self-attention, which comes at a computational cost quadratic in the input sequence length. In this paper, we investigate the global structure of attention scores computed using this dot product mechanism on a typical distribution of inputs, and study the principal components of their variation. Through eigen analysis of full attention score matrices, as well as of their individual rows, we find that most of the variation among attention scores lie in a low-dimensional eigenspace. Moreover, we find significant overlap between these eigenspaces for different layers and even different transformer models. Based on this, we propose to compute scores only for a partial subset of token pairs, and use them to estimate scores for the remaining pairs. Beyond investigating the accuracy of reconstructing attention scores themselves, we investigate training transformer models that employ these approximations, and analyze the effect on overall accuracy. Our analysis and the proposed method provide insights into how to balance the benefits of exact pair-wise attention and its significant computational expense.
Understanding Robustness of Transformers for Image Classification
Mar 26, 2021
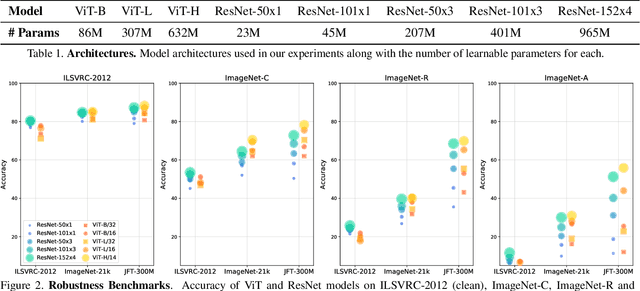
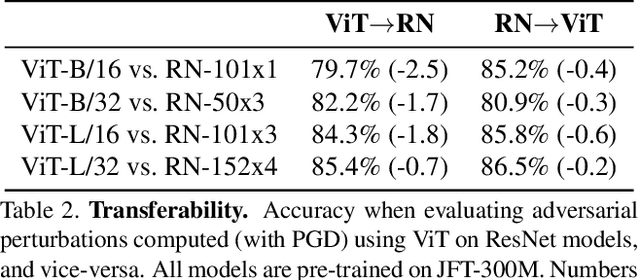

Deep Convolutional Neural Networks (CNNs) have long been the architecture of choice for computer vision tasks. Recently, Transformer-based architectures like Vision Transformer (ViT) have matched or even surpassed ResNets for image classification. However, details of the Transformer architecture -- such as the use of non-overlapping patches -- lead one to wonder whether these networks are as robust. In this paper, we perform an extensive study of a variety of different measures of robustness of ViT models and compare the findings to ResNet baselines. We investigate robustness to input perturbations as well as robustness to model perturbations. We find that when pre-trained with a sufficient amount of data, ViT models are at least as robust as the ResNet counterparts on a broad range of perturbations. We also find that Transformers are robust to the removal of almost any single layer, and that while activations from later layers are highly correlated with each other, they nevertheless play an important role in classification.
Deep Denoising of Flash and No-Flash Pairs for Photography in Low-Light Environments
Dec 09, 2020
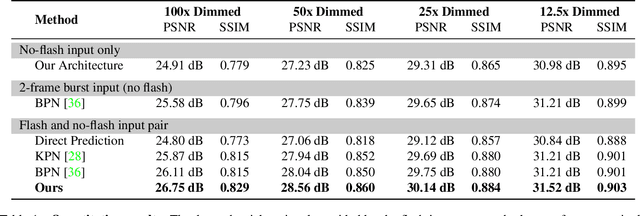
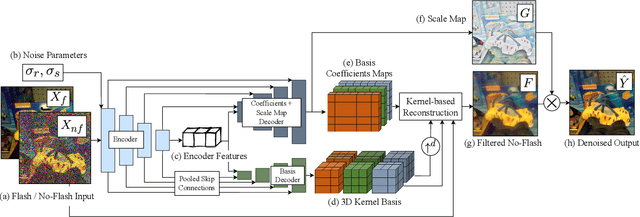
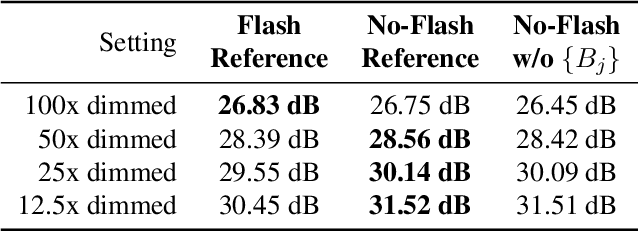
We introduce a neural network-based method to denoise pairs of images taken in quick succession in low-light environments, with and without a flash. Our goal is to produce a high-quality rendering of the scene that preserves the color and mood from the ambient illumination of the noisy no-flash image, while recovering surface texture and detail revealed by the flash. Our network outputs a gain map and a field of kernels, the latter obtained by linearly mixing elements of a per-image low-rank kernel basis. We first apply the kernel field to the no-flash image, and then multiply the result with the gain map to create the final output. We show our network effectively learns to produce high-quality images by combining a smoothed out estimate of the scene's ambient appearance from the no-flash image, with high-frequency albedo details extracted from the flash input. Our experiments show significant improvements over alternative captures without a flash, and baseline denoisers that use flash no-flash pairs. In particular, our method produces images that are both noise-free and contain accurate ambient colors without the sharp shadows or strong specular highlights visible in the flash image.
Real-Time Edge Classification: Optimal Offloading under Token Bucket Constraints
Nov 05, 2020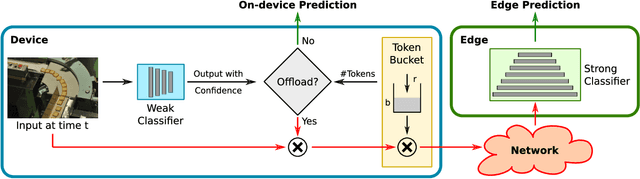
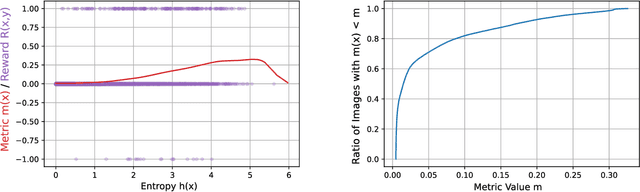
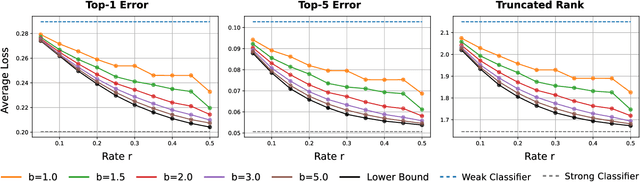
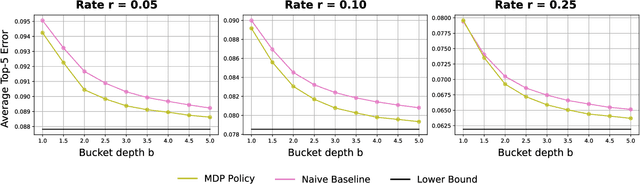
To deploy machine learning-based algorithms for real-time applications with strict latency constraints, we consider an edge-computing setting where a subset of inputs are offloaded to the edge for processing by an accurate but resource-intensive model, and the rest are processed only by a less-accurate model on the device itself. Both models have computational costs that match available compute resources, and process inputs with low-latency. But offloading incurs network delays, and to manage these delays to meet application deadlines, we use a token bucket to constrain the average rate and burst length of transmissions from the device. We introduce a Markov Decision Process-based framework to make offload decisions under these constraints, based on the local model's confidence and the token bucket state, with the goal of minimizing a specified error measure for the application. Beyond isolated decisions for individual devices, we also propose approaches to allow multiple devices connected to the same access switch to share their bursting allocation. We evaluate and analyze the policies derived using our framework on the standard ImageNet image classification benchmark.
Finding Physical Adversarial Examples for Autonomous Driving with Fast and Differentiable Image Compositing
Oct 17, 2020
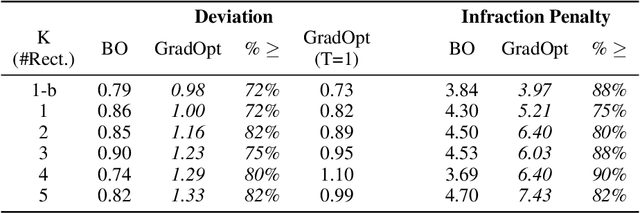
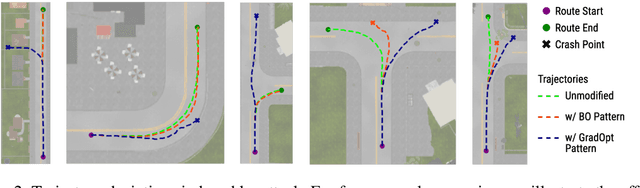
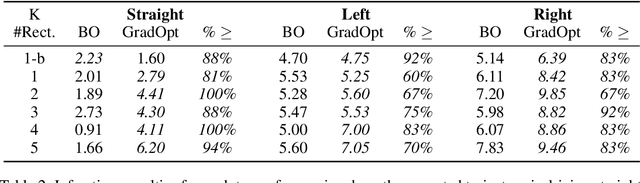
There is considerable evidence that deep neural networks are vulnerable to adversarial perturbations applied directly to their digital inputs. However, it remains an open question whether this translates to vulnerabilities in real-world systems. Specifically, in the context of image inputs to autonomous driving systems, an attack can be achieved only by modifying the physical environment, so as to ensure that the resulting stream of video inputs to the car's controller leads to incorrect driving decisions. Inducing this effect on the video inputs indirectly through the environment requires accounting for system dynamics and tracking viewpoint changes. We propose a scalable and efficient approach for finding adversarial physical modifications, using a differentiable approximation for the mapping from environmental modifications-namely, rectangles drawn on the road-to the corresponding video inputs to the controller network. Given the color, location, position, and orientation parameters of the rectangles, our mapping composites them onto pre-recorded video streams of the original environment. Our mapping accounts for geometric and color variations, is differentiable with respect to rectangle parameters, and uses multiple original video streams obtained by varying the driving trajectory. When combined with a neural network-based controller, our approach allows the design of adversarial modifications through end-to-end gradient-based optimization. We evaluate our approach using the Carla autonomous driving simulator, and show that it is significantly more scalable and far more effective at generating attacks than a prior black-box approach based on Bayesian Optimization.
A MEMS-based Foveating LIDAR to enable Real-time Adaptive Depth Sensing
Mar 21, 2020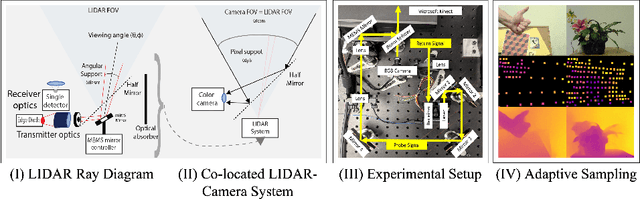


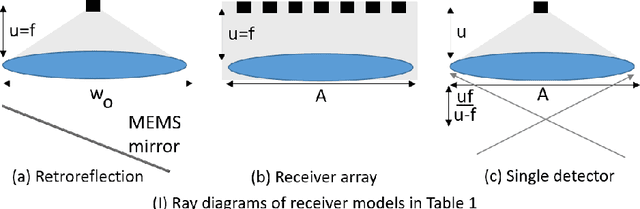
Most active depth sensors sample their visual field using a fixed pattern, decided by accuracy, speed and cost trade-offs, rather than scene content. However, a number of recent works have demonstrated that adapting measurement patterns to scene content can offer significantly better trade-offs. We propose a hardware LIDAR design that allows flexible real-time measurements according to dynamically specified measurement patterns. Our flexible depth sensor design consists of a controllable scanning LIDAR that can foveate, or increase resolution in regions of interest, and that can fully leverage the power of adaptive depth sensing. We describe our optical setup and calibration, which enables fast sparse depth measurements using a scanning MEMS (micro-electro mechanical) mirror. We validate the efficacy of our prototype LIDAR design by testing on over 75 static and dynamic scenes spanning a range of environments. We also show CNN-based depth-map completion of sparse measurements obtained by our sensor. Our experiments show that our sensor can realize adaptive depth sensing systems.
Basis Prediction Networks for Effective Burst Denoising with Large Kernels
Dec 09, 2019
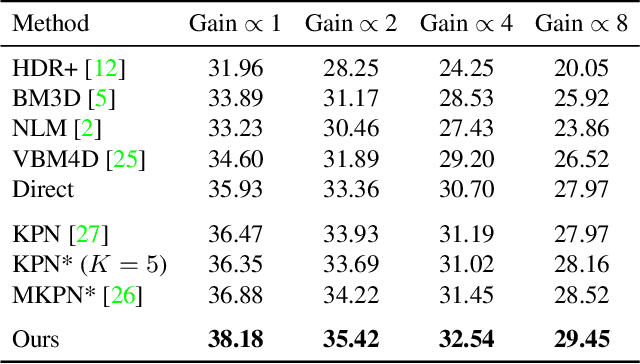
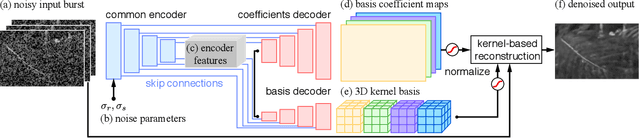
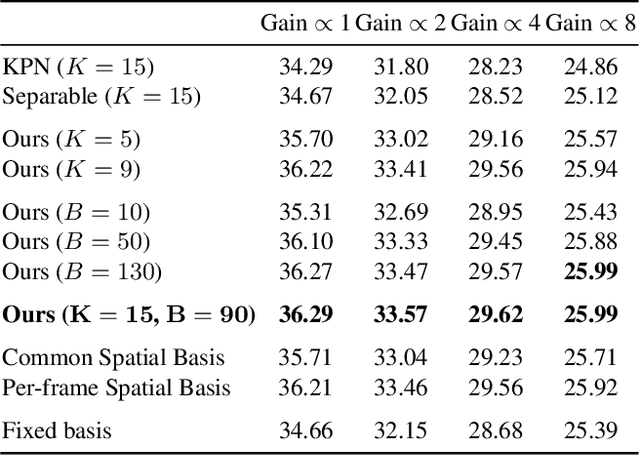
Bursts of images exhibit significant self-similarity across both time and space. This motivates a representation of the kernels as linear combinations of a small set of basis elements. To this end, we introduce a novel basis prediction network that, given an input burst, predicts a set of global basis kernels --- shared within the image --- and the corresponding mixing coefficients --- which are specific to individual pixels. Compared to other state-of-the-art deep learning techniques that output a large tensor of per-pixel spatiotemporal kernels, our formulation substantially reduces the dimensionality of the network output. This allows us to effectively exploit larger denoising kernels and achieve significant quality improvements (over 1dB PSNR) at reduced run-times compared to state-of-the-art methods.
Protecting Geolocation Privacy of Photo Collections
Dec 04, 2019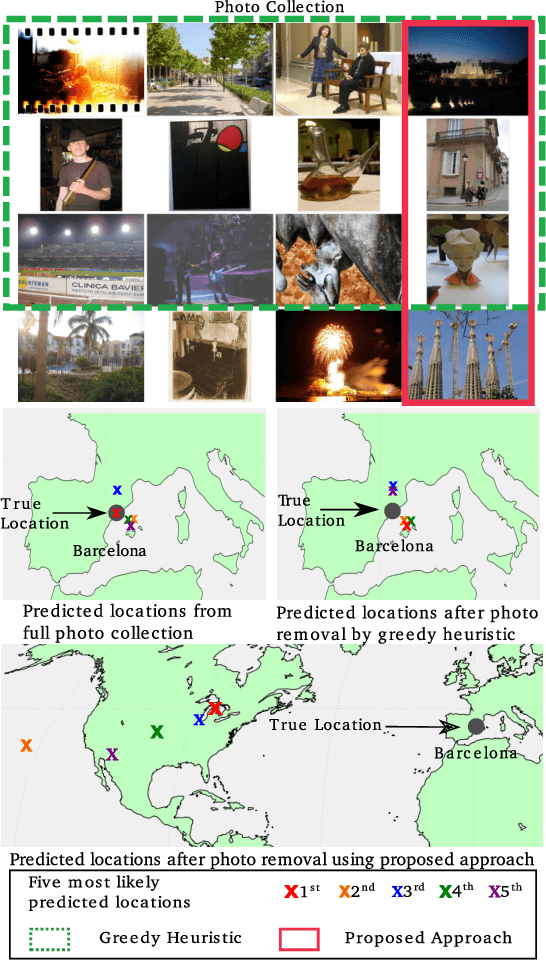
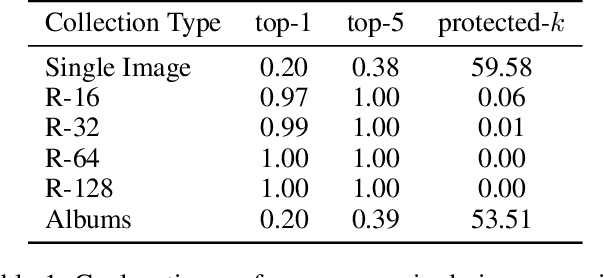
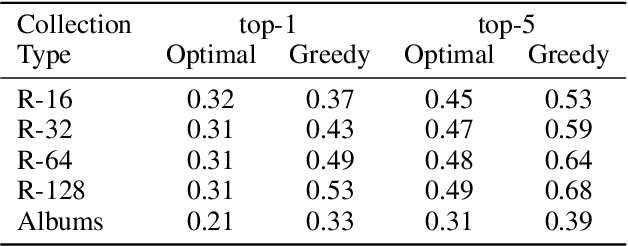
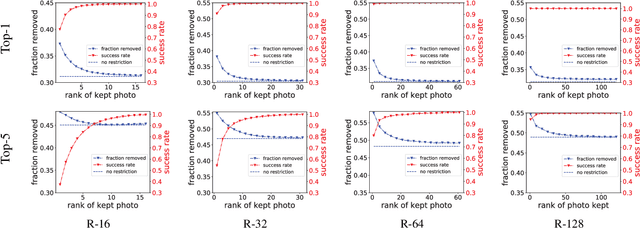
People increasingly share personal information, including their photos and photo collections, on social media. This information, however, can compromise individual privacy, particularly as social media platforms use it to infer detailed models of user behavior, including tracking their location. We consider the specific issue of location privacy as potentially revealed by posting photo collections, which facilitate accurate geolocation with the help of deep learning methods even in the absence of geotags. One means to limit associated inadvertent geolocation privacy disclosure is by carefully pruning select photos from photo collections before these are posted publicly. We study this problem formally as a combinatorial optimization problem in the context of geolocation prediction facilitated by deep learning. We first demonstrate the complexity both by showing that a natural greedy algorithm can be arbitrarily bad and by proving that the problem is NP-Hard. We then exhibit an important tractable special case, as well as a more general approach based on mixed-integer linear programming. Through extensive experiments on real photo collections, we demonstrate that our approaches are indeed highly effective at preserving geolocation privacy.
Neural Network-Inspired Analog-to-Digital Conversion to Achieve Super-Resolution with Low-Precision RRAM Devices
Nov 28, 2019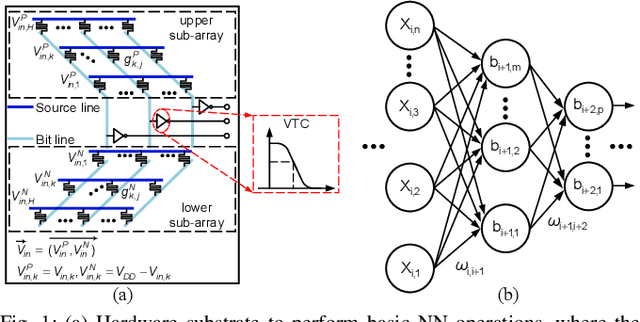
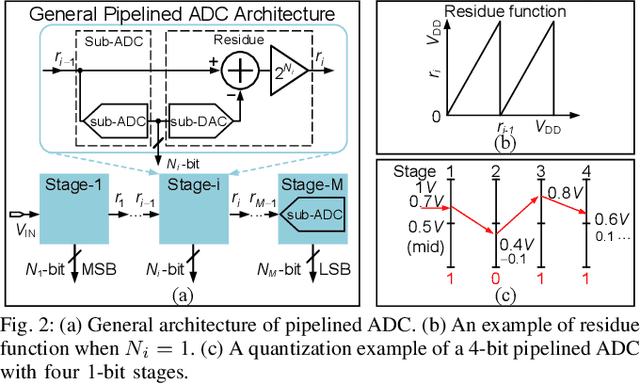
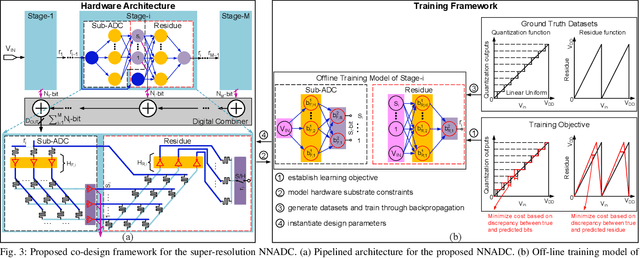
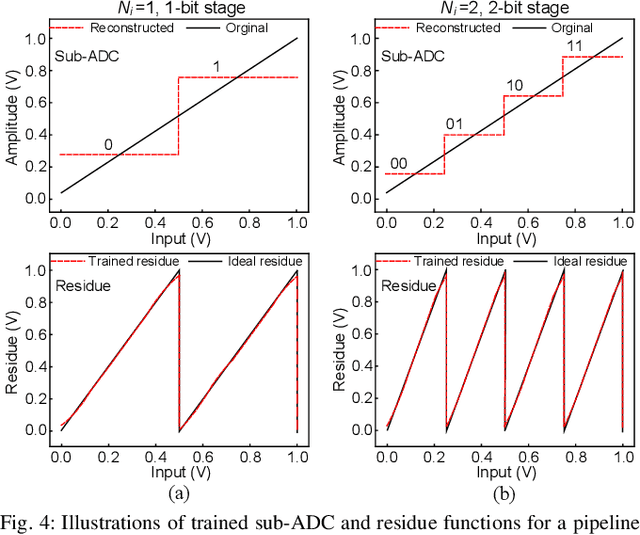
Recent works propose neural network- (NN-) inspired analog-to-digital converters (NNADCs) and demonstrate their great potentials in many emerging applications. These NNADCs often rely on resistive random-access memory (RRAM) devices to realize the NN operations and require high-precision RRAM cells (6~12-bit) to achieve a moderate quantization resolution (4~8-bit). Such optimistic assumption of RRAM resolution, however, is not supported by fabrication data of RRAM arrays in large-scale production process. In this paper, we propose an NN-inspired super-resolution ADC based on low-precision RRAM devices by taking the advantage of a co-design methodology that combines a pipelined hardware architecture with a custom NN training framework. Results obtained from SPICE simulations demonstrate that our method leads to robust design of a 14-bit super-resolution ADC using 3-bit RRAM devices with improved power and speed performance and competitive figure-of-merits (FoMs). In addition to the linear uniform quantization, the proposed ADC can also support configurable high-resolution nonlinear quantization with high conversion speed and low conversion energy, enabling future intelligent analog-to-information interfaces for near-sensor analytics and processing.