 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Stability with Continuous Data Updates
Jan 14, 2022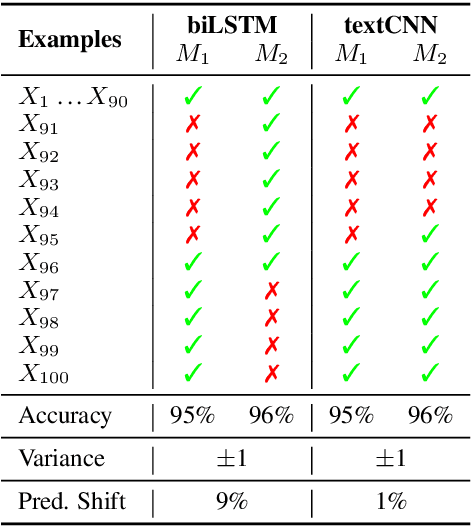
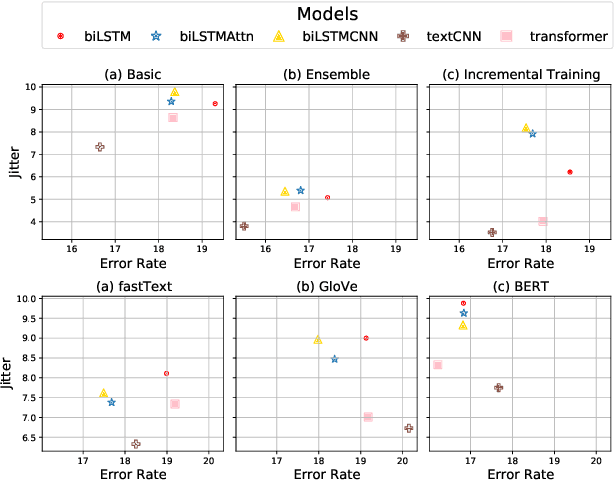
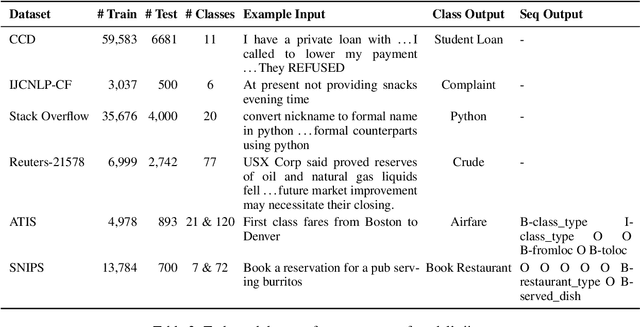
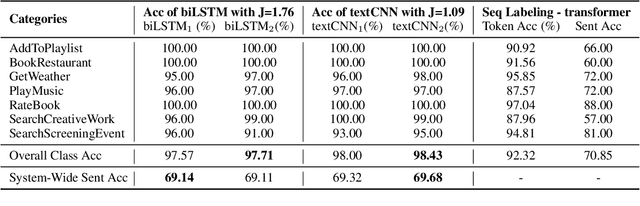
In this paper, we study the "stability" of machine learning (ML) models within the context of larger, complex NLP systems with continuous training data updates. For this study, we propose a methodology for the assessment of model stability (which we refer to as jitter under various experimental conditions. We find that model design choices, including network architecture and input representation, have a critical impact on stability through experiments on four text classification tasks and two sequence labeling tasks. In classification tasks, non-RNN-based models are observed to be more stable than RNN-based ones, while the encoder-decoder model is less stable in sequence labeling tasks. Moreover, input representations based on pre-trained fastText embeddings contribute to more stability than other choices. We also show that two learning strategies -- ensemble models and incremental training -- have a significant influence on stability. We recommend ML model designers account for trade-offs in accuracy and jitter when making modeling choices.
Live Blog Corpus for Summarization
Feb 27, 2018

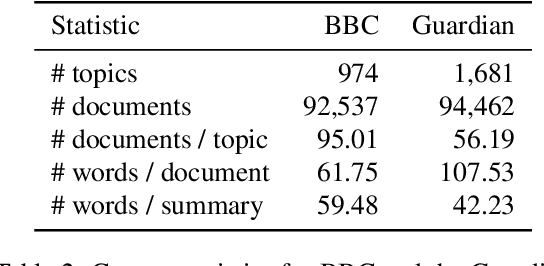
Live blogs are an increasingly popular news format to cover breaking news and live events in online journalism. Online news websites around the world are using this medium to give their readers a minute by minute update on an event. Good summaries enhance the value of the live blogs for a reader but are often not available. In this paper, we study a way of collecting corpora for automatic live blog summarization. In an empirical evaluation using well-known state-of-the-art summarization systems, we show that live blogs corpus poses new challenges in the field of summarization. We make our tools publicly available to reconstruct the corpus to encourage the research community and replicate our results.