 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEELBERT: Tiny Models through Dynamic Embeddings
Oct 31, 2023



We introduce EELBERT, an approach for compression of transformer-based models (e.g., BERT), with minimal impact on the accuracy of downstream tasks. This is achieved by replacing the input embedding layer of the model with dynamic, i.e. on-the-fly, embedding computations. Since the input embedding layer accounts for a significant fraction of the model size, especially for the smaller BERT variants, replacing this layer with an embedding computation function helps us reduce the model size significantly. Empirical evaluation on the GLUE benchmark shows that our BERT variants (EELBERT) suffer minimal regression compared to the traditional BERT models. Through this approach, we are able to develop our smallest model UNO-EELBERT, which achieves a GLUE score within 4% of fully trained BERT-tiny, while being 15x smaller (1.2 MB) in size.
Machine Learning as an Accurate Predictor for Percolation Threshold of Diverse Networks
Dec 16, 2022



Percolation threshold is an important measure to determine the inherent rigidity of large networks. Predictors of the percolation threshold for large networks are computationally intense to run, hence it is a necessity to develop predictors of the percolation threshold of networks, that do not rely on numerical simulations. We demonstrate the efficacy of five machine learning-based regression techniques for the accurate prediction of the percolation threshold. The dataset generated to train the machine learning models contains a total of 777 real and synthetic networks and consists of 5 statistical and structural properties of networks as features and the numerically computed percolation threshold as the output attribute. We establish that the machine learning models outperform three existing empirical estimators of bond percolation threshold, and extend this experiment to predict site and explosive percolation. We also compare the performance of our models in predicting the percolation threshold and find that the gradient boosting regressor, multilayer perceptron and random forests regression models achieve the least RMSE values among the models utilized.
Languages You Know Influence Those You Learn: Impact of Language Characteristics on Multi-Lingual Text-to-Text Transfer
Dec 04, 2022



Multi-lingual language models (LM), such as mBERT, XLM-R, mT5, mBART, have been remarkably successful in enabling natural language tasks in low-resource languages through cross-lingual transfer from high-resource ones. In this work, we try to better understand how such models, specifically mT5, transfer *any* linguistic and semantic knowledge across languages, even though no explicit cross-lingual signals are provided during pre-training. Rather, only unannotated texts from each language are presented to the model separately and independently of one another, and the model appears to implicitly learn cross-lingual connections. This raises several questions that motivate our study, such as: Are the cross-lingual connections between every language pair equally strong? What properties of source and target language impact the strength of cross-lingual transfer? Can we quantify the impact of those properties on the cross-lingual transfer? In our investigation, we analyze a pre-trained mT5 to discover the attributes of cross-lingual connections learned by the model. Through a statistical interpretation framework over 90 language pairs across three tasks, we show that transfer performance can be modeled by a few linguistic and data-derived features. These observations enable us to interpret cross-lingual understanding of the mT5 model. Through these observations, one can favorably choose the best source language for a task, and can anticipate its training data demands. A key finding of this work is that similarity of syntax, morphology and phonology are good predictors of cross-lingual transfer, significantly more than just the lexical similarity of languages. For a given language, we are able to predict zero-shot performance, that increases on a logarithmic scale with the number of few-shot target language data points.
Can Open Domain Question Answering Systems Answer Visual Knowledge Questions?
Feb 09, 2022
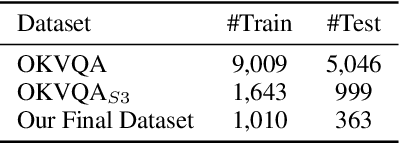

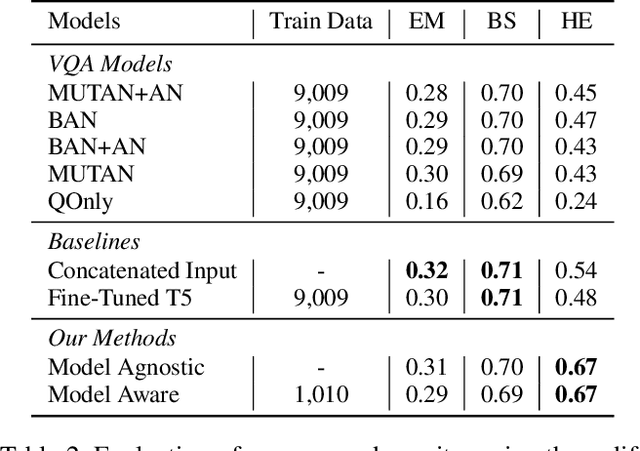
The task of Outside Knowledge Visual Question Answering (OKVQA) requires an automatic system to answer natural language questions about pictures and images using external knowledge. We observe that many visual questions, which contain deictic referential phrases referring to entities in the image, can be rewritten as "non-grounded" questions and can be answered by existing text-based question answering systems. This allows for the reuse of existing text-based Open Domain Question Answering (QA) Systems for visual question answering. In this work, we propose a potentially data-efficient approach that reuses existing systems for (a) image analysis, (b) question rewriting, and (c) text-based question answering to answer such visual questions. Given an image and a question pertaining to that image (a visual question), we first extract the entities present in the image using pre-trained object and scene classifiers. Using these detected entities, the visual questions can be rewritten so as to be answerable by open domain QA systems. We explore two rewriting strategies: (1) an unsupervised method using BERT for masking and rewriting, and (2) a weakly supervised approach that combines adaptive rewriting and reinforcement learning techniques to use the implicit feedback from the QA system. We test our strategies on the publicly available OKVQA dataset and obtain a competitive performance with state-of-the-art models while using only 10% of the training data.
Model Stability with Continuous Data Updates
Jan 14, 2022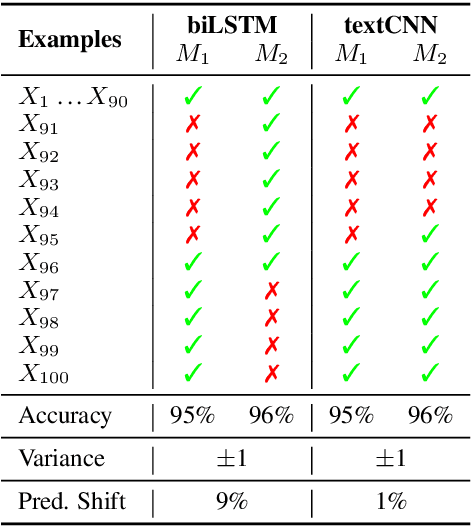
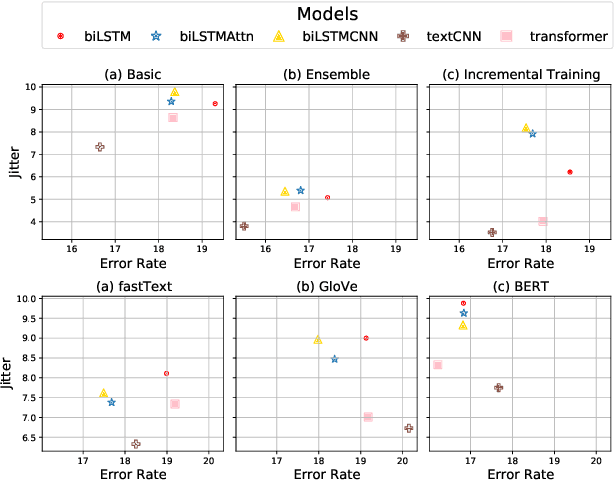
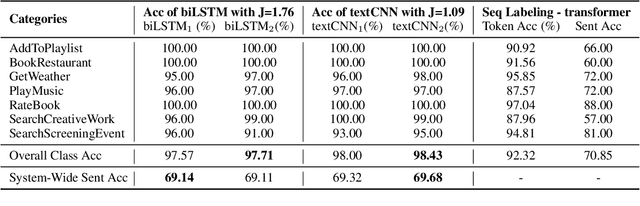
In this paper, we study the "stability" of machine learning (ML) models within the context of larger, complex NLP systems with continuous training data updates. For this study, we propose a methodology for the assessment of model stability (which we refer to as jitter under various experimental conditions. We find that model design choices, including network architecture and input representation, have a critical impact on stability through experiments on four text classification tasks and two sequence labeling tasks. In classification tasks, non-RNN-based models are observed to be more stable than RNN-based ones, while the encoder-decoder model is less stable in sequence labeling tasks. Moreover, input representations based on pre-trained fastText embeddings contribute to more stability than other choices. We also show that two learning strategies -- ensemble models and incremental training -- have a significant influence on stability. We recommend ML model designers account for trade-offs in accuracy and jitter when making modeling choices.
Annotating Electronic Medical Records for Question Answering
May 17, 2018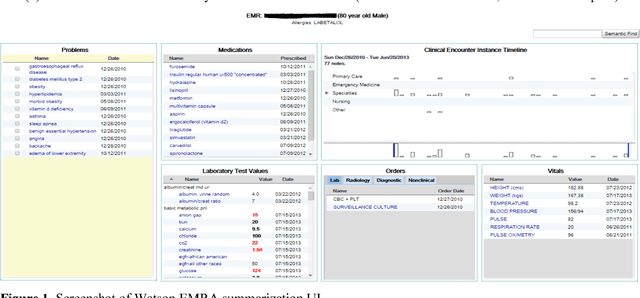
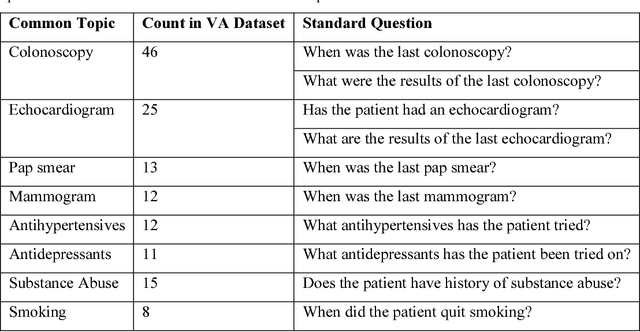
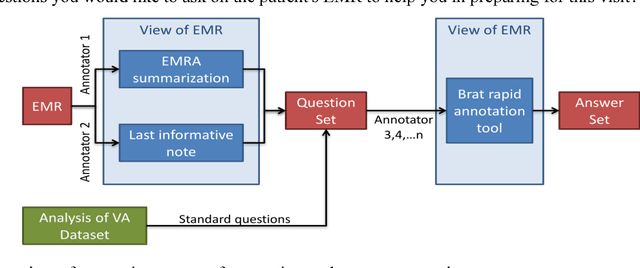
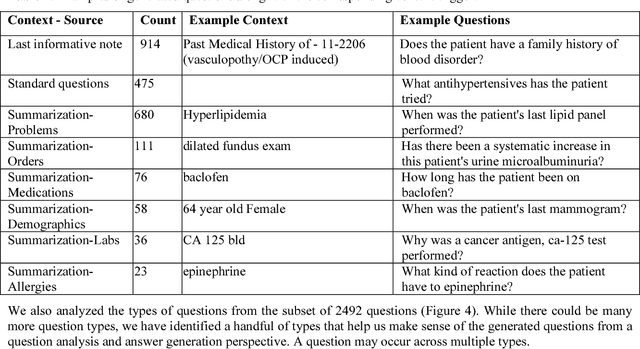
Our research is in the relatively unexplored area of question answering technologies for patient-specific questions over their electronic health records. A large dataset of human expert curated question and answer pairs is an important pre-requisite for developing, training and evaluating any question answering system that is powered by machine learning. In this paper, we describe a process for creating such a dataset of questions and answers. Our methodology is replicable, can be conducted by medical students as annotators, and results in high inter-annotator agreement (0.71 Cohen's kappa). Over the course of 11 months, 11 medical students followed our annotation methodology, resulting in a question answering dataset of 5696 questions over 71 patient records, of which 1747 questions have corresponding answers generated by the medical students.
The Role of Context Types and Dimensionality in Learning Word Embeddings
Jul 19, 2017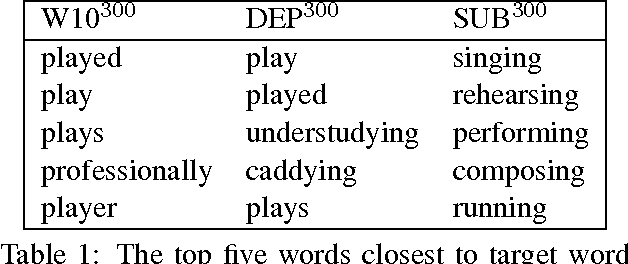
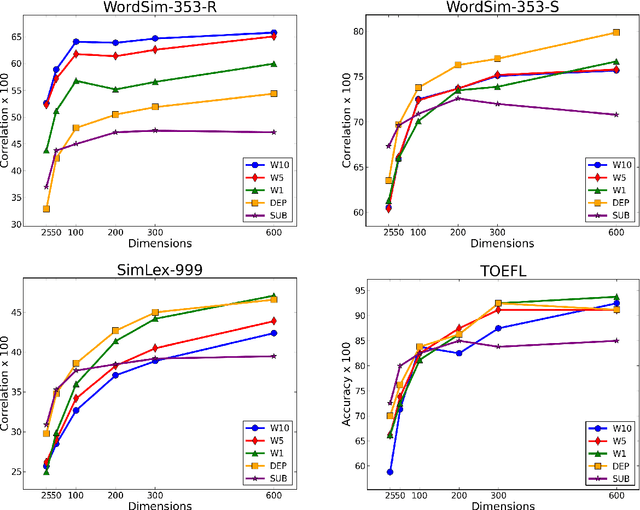
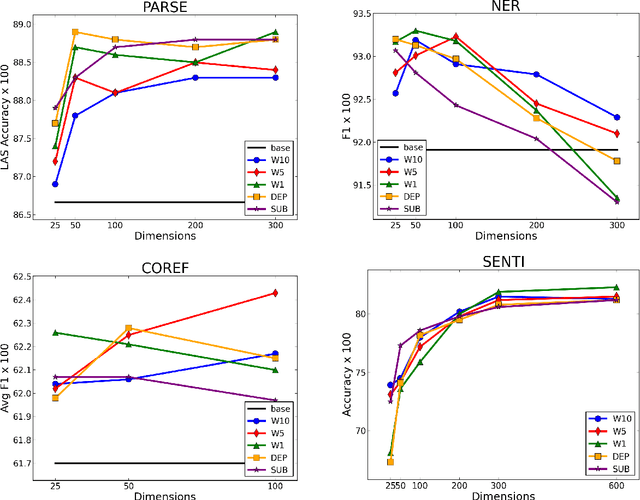
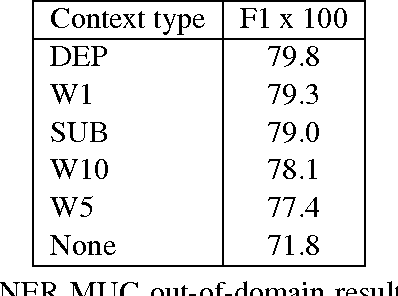
We provide the first extensive evaluation of how using different types of context to learn skip-gram word embeddings affects performance on a wide range of intrinsic and extrinsic NLP tasks. Our results suggest that while intrinsic tasks tend to exhibit a clear preference to particular types of contexts and higher dimensionality, more careful tuning is required for finding the optimal settings for most of the extrinsic tasks that we considered. Furthermore, for these extrinsic tasks, we find that once the benefit from increasing the embedding dimensionality is mostly exhausted, simple concatenation of word embeddings, learned with different context types, can yield further performance gains. As an additional contribution, we propose a new variant of the skip-gram model that learns word embeddings from weighted contexts of substitute words.
Addressing Limited Data for Textual Entailment Across Domains
Jun 08, 2016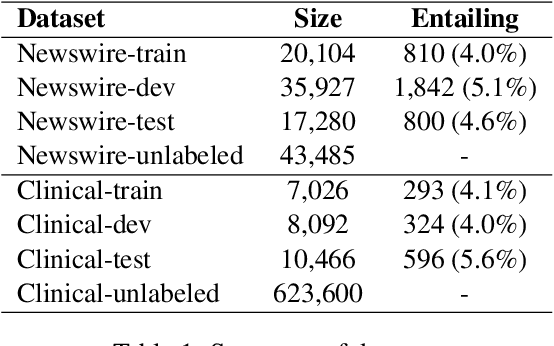


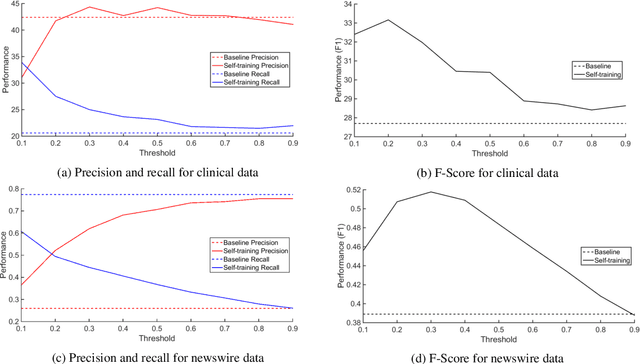
We seek to address the lack of labeled data (and high cost of annotation) for textual entailment in some domains. To that end, we first create (for experimental purposes) an entailment dataset for the clinical domain, and a highly competitive supervised entailment system, ENT, that is effective (out of the box) on two domains. We then explore self-training and active learning strategies to address the lack of labeled data. With self-training, we successfully exploit unlabeled data to improve over ENT by 15% F-score on the newswire domain, and 13% F-score on clinical data. On the other hand, our active learning experiments demonstrate that we can match (and even beat) ENT using only 6.6% of the training data in the clinical domain, and only 5.8% of the training data in the newswire domain.