 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle-Space Informed Detection of Autoencoded Blind False Data Injection Attacks on Power Systems
May 27, 2026The rapid growth of AI-driven data centers and large-scale energy storage systems is increasing the reliance of power system operation on real-time measurement data and automated decision-making. However, many existing detection methods rely on statistical or data-driven analysis of measurements and can fail when attackers exploit the same data structure to craft stealthy perturbations. To illustrate this limitation, we demonstrate a blind False Data Injection Attack (FDIA) in which an Autoencoder learns the measurement manifold and generates perturbations aligned with the Jacobian null space, thereby allowing the attack to evade both residual-based baddata detectors and time-series anomaly detectors. To mitigate data-driven FDIAs which exploit the null space, we propose a topology-informed Cycle-Space Detector (CSD) that leverages the Cycle-Space of the network to impose structural constraints that enhance null space estimation. In addition, we prove that by using the Minimum Cycle Basis (MCB), the proposed CSD achieves the optimal generalization error for attack detection. By exploiting topology-derived cycle constraints rather than relying solely on numerical null space estimation, the proposed method does not require precise line parameters and improves the separation between normal and attacked measurements. Simulation results on IEEE 14-, 30-, 57-, and 118-bus systems demonstrate that the proposed method effectively detects data-driven FDIAs under realistic measurement noise.
Projective Psychological Assessment of Large Multimodal Models Using Thematic Apperception Tests
Feb 19, 2026Thematic Apperception Test (TAT) is a psychometrically grounded, multidimensional assessment framework that systematically differentiates between cognitive-representational and affective-relational components of personality-like functioning. This test is a projective psychological framework designed to uncover unconscious aspects of personality. This study examines whether the personality traits of Large Multimodal Models (LMMs) can be assessed through non-language-based modalities, using the Social Cognition and Object Relations Scale - Global (SCORS-G). LMMs are employed in two distinct roles: as subject models (SMs), which generate stories in response to TAT images, and as evaluator models (EMs), who assess these narratives using the SCORS-G framework. Evaluators demonstrated an excellent ability to understand and analyze TAT responses. Their interpretations are highly consistent with those of human experts. Assessment results highlight that all models understand interpersonal dynamics very well and have a good grasp of the concept of self. However, they consistently fail to perceive and regulate aggression. Performance varied systematically across model families, with larger and more recent models consistently outperforming smaller and earlier ones across SCORS-G dimensions.
Fake News Data Collection and Classification: Iterative Query Selection for Opaque Search Engines with Pseudo Relevance Feedback
Dec 23, 2020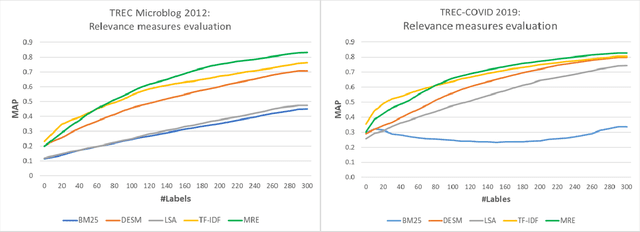
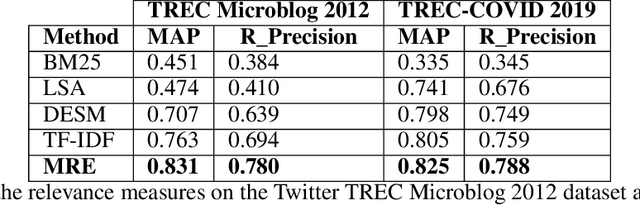
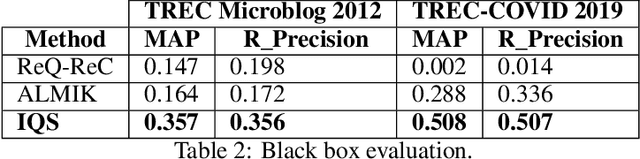
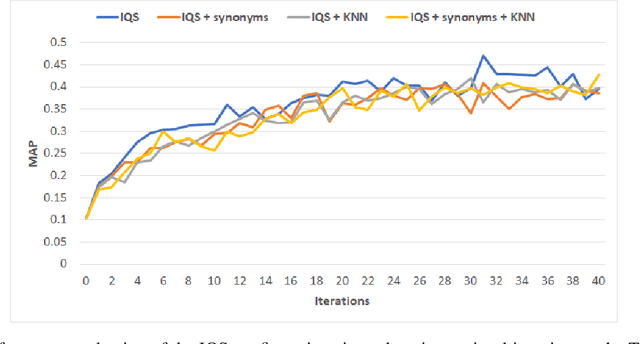
Retrieving information from an online search engine is the first and most important step in many data mining tasks. Most of the search engines currently available on the web, including all social media platforms, are black-boxes (a.k.a opaque) supporting short keyword queries. In these settings, retrieving all posts and comments discussing a particular news item automatically and at large scales is a challenging task. In this paper, we propose a method for generating short keyword queries given a prototype document. The proposed algorithm interacts with the opaque search engine to iteratively improve the query. It is evaluated on the Twitter TREC Microblog 2012 and TREC-COVID 2019 datasets showing superior performance compared to state of the art and is applied to automatically collect large scale dataset for training machine learning classifiers for fake news detection. The classifiers training on 70,000 labeled news items and more than 61 million associated tweets automatically collected using the proposed method obtained impressive performance of AUC and accuracy of 0.92, and 0.86, respectively.
How Does That Sound? Multi-Language SpokenName2Vec Algorithm Using Speech Generation and Deep Learning
May 24, 2020
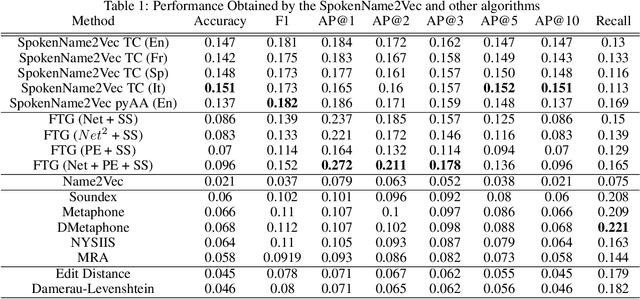

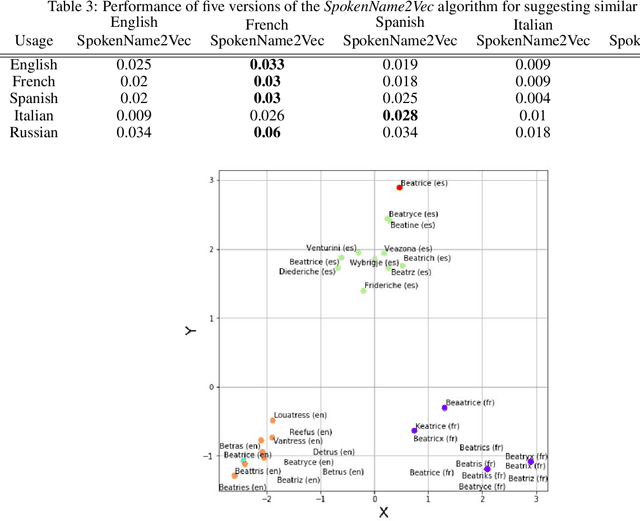
Searching for information about a specific person is an online activity frequently performed by many users. In most cases, users are aided by queries containing a name and sending back to the web search engines for finding their will. Typically, Web search engines provide just a few accurate results associated with a name-containing query. Currently, most solutions for suggesting synonyms in online search are based on pattern matching and phonetic encoding, however very often, the performance of such solutions is less than optimal. In this paper, we propose SpokenName2Vec, a novel and generic approach which addresses the similar name suggestion problem by utilizing automated speech generation, and deep learning to produce spoken name embeddings. This sophisticated and innovative embeddings captures the way people pronounce names in any language and accent. Utilizing the name pronunciation can be helpful for both differentiating and detecting names that sound alike, but are written differently. The proposed approach was demonstrated on a large-scale dataset consisting of 250,000 forenames and evaluated using a machine learning classifier and 7,399 names with their verified synonyms. The performance of the proposed approach was found to be superior to 12 other algorithms evaluated in this study, including well used phonetic and string similarity algorithms, and two recently proposed algorithms. The results obtained suggest that the proposed approach could serve as a useful and valuable tool for solving the similar name suggestion problem.