 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semi-supervised Spatial Spectral Regularized Manifold Local Scaling Cut With HGF for Dimensionality Reduction of Hyperspectral Images
Nov 20, 2018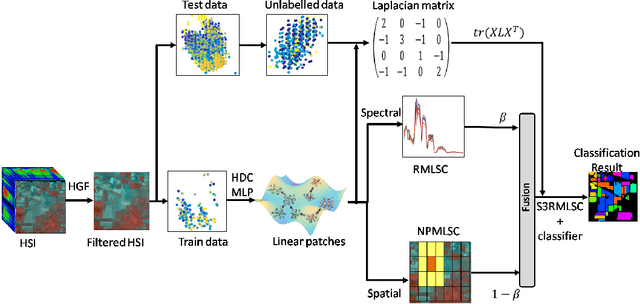
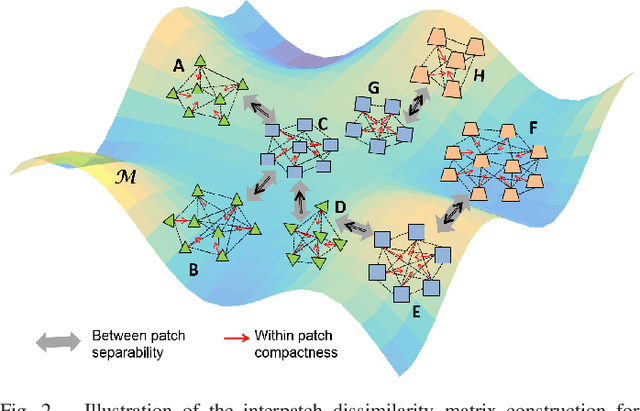
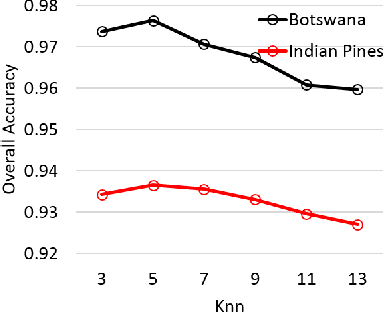
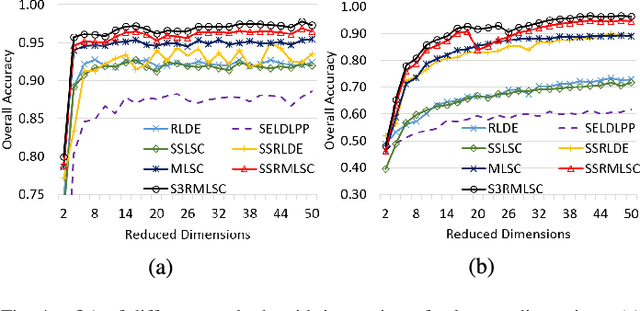
Hyperspectral images (HSI) contain a wealth of information over hundreds of contiguous spectral bands, making it possible to classify materials through subtle spectral discrepancies. However, the classification of this rich spectral information is accompanied by the challenges like high dimensionality, singularity, limited training samples, lack of labeled data samples, heteroscedasticity and nonlinearity. To address these challenges, we propose a semi-supervised graph based dimensionality reduction method named `semi-supervised spatial spectral regularized manifold local scaling cut' (S3RMLSC). The underlying idea of the proposed method is to exploit the limited labeled information from both the spectral and spatial domains along with the abundant unlabeled samples to facilitate the classification task by retaining the original distribution of the data. In S3RMLSC, a hierarchical guided filter (HGF) is initially used to smoothen the pixels of the HSI data to preserve the spatial pixel consistency. This step is followed by the construction of linear patches from the nonlinear manifold by using the maximal linear patch (MLP) criterion. Then the inter-patch and intra-patch dissimilarity matrices are constructed in both spectral and spatial domains by regularized manifold local scaling cut (RMLSC) and neighboring pixel manifold local scaling cut (NPMLSC) respectively. Finally, we obtain the projection matrix by optimizing the updated semi-supervised spatial-spectral between-patch and total-patch dissimilarity. The effectiveness of the proposed DR algorithm is illustrated with publicly available real-world HSI datasets.
ESCaF: Pupil Centre Localization Algorithm with Candidate Filtering
Jul 27, 2018
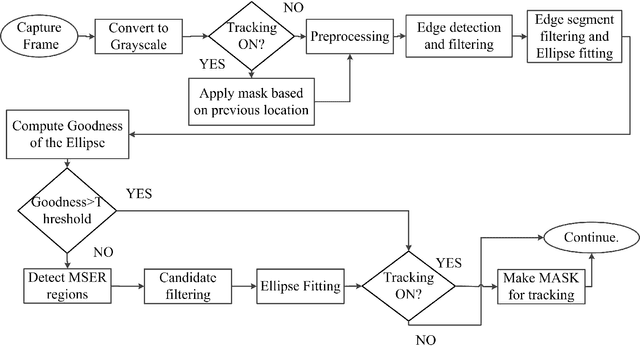
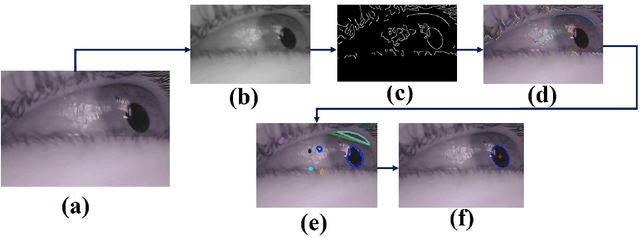
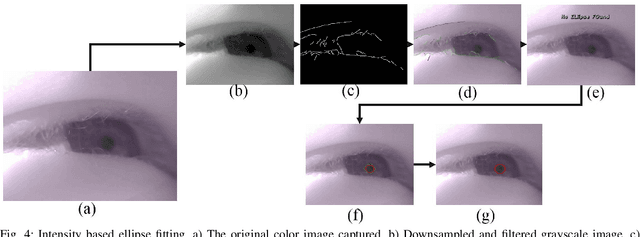
Algorithms for accurate localization of pupil centre is essential for gaze tracking in real world conditions. Most of the algorithms fail in real world conditions like illumination variations, contact lenses, glasses, eye makeup, motion blur, noise, etc. We propose a new algorithm which improves the detection rate in real world conditions. The proposed algorithm uses both edges as well as intensity information along with a candidate filtering approach to identify the best pupil candidate. A simple tracking scheme has also been added which improves the processing speed. The algorithm has been evaluated in Labelled Pupil in the Wild (LPW) dataset, largest in its class which contains real world conditions. The proposed algorithm outperformed the state of the art algorithms while achieving real-time performance.
A Trace Lasso Regularized L1-norm Graph Cut for Highly Correlated Noisy Hyperspectral Image
Jul 22, 2018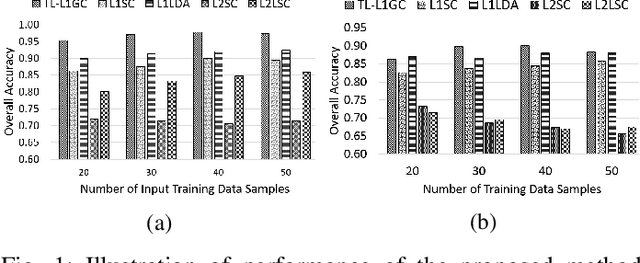
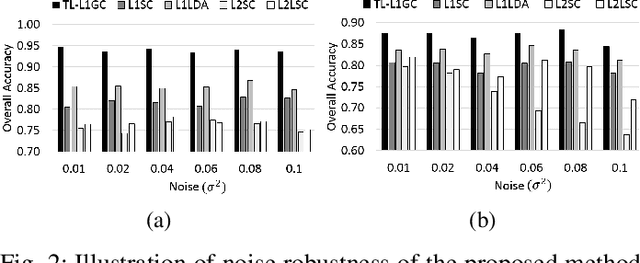
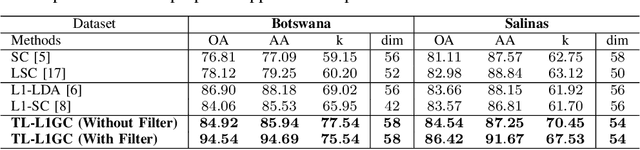
This work proposes an adaptive trace lasso regularized L1-norm based graph cut method for dimensionality reduction of Hyperspectral images, called as `Trace Lasso-L1 Graph Cut' (TL-L1GC). The underlying idea of this method is to generate the optimal projection matrix by considering both the sparsity as well as the correlation of the data samples. The conventional L2-norm used in the objective function is sensitive to noise and outliers. Therefore, in this work L1-norm is utilized as a robust alternative to L2-norm. Besides, for further improvement of the results, we use a penalty function of trace lasso with the L1GC method. It adaptively balances the L2-norm and L1-norm simultaneously by considering the data correlation along with the sparsity. We obtain the optimal projection matrix by maximizing the ratio of between-class dispersion to within-class dispersion using L1-norm with trace lasso as the penalty. Furthermore, an iterative procedure for this TL-L1GC method is proposed to solve the optimization function. The effectiveness of this proposed method is evaluated on two benchmark HSI datasets.
A Supervised Geometry-Aware Mapping Approach for Classification of Hyperspectral Images
Jul 07, 2018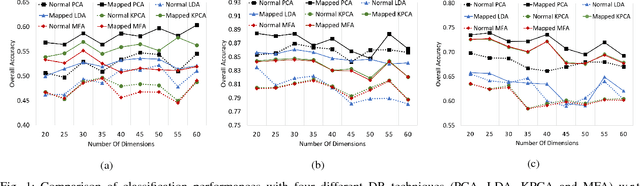
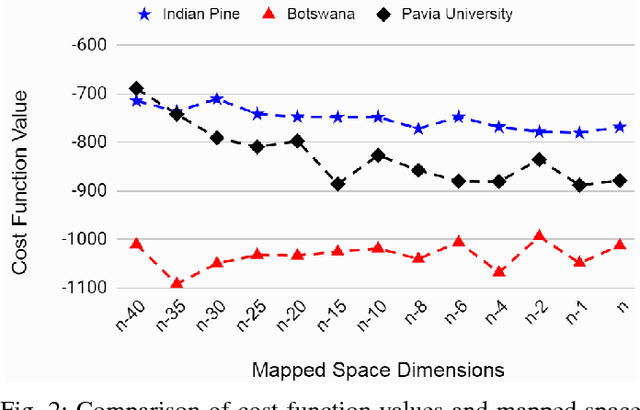
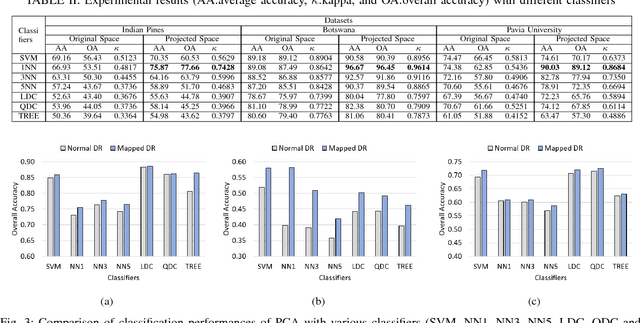
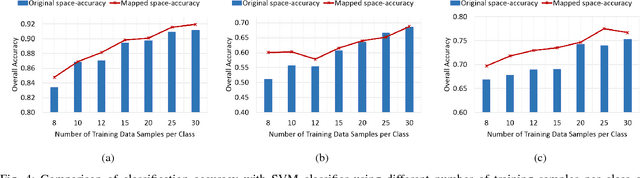
The lack of proper class discrimination among the Hyperspectral (HS) data points poses a potential challenge in HS classification. To address this issue, this paper proposes an optimal geometry-aware transformation for enhancing the classification accuracy. The underlying idea of this method is to obtain a linear projection matrix by solving a nonlinear objective function based on the intrinsic geometrical structure of the data. The objective function is constructed to quantify the discrimination between the points from dissimilar classes on the projected data space. Then the obtained projection matrix is used to linearly map the data to more discriminative space. The effectiveness of the proposed transformation is illustrated with three benchmark real-world HS data sets. The experiments reveal that the classification and dimensionality reduction methods on the projected discriminative space outperform their counterpart in the original space.
Recognition of Activities from Eye Gaze and Egocentric Video
May 18, 2018
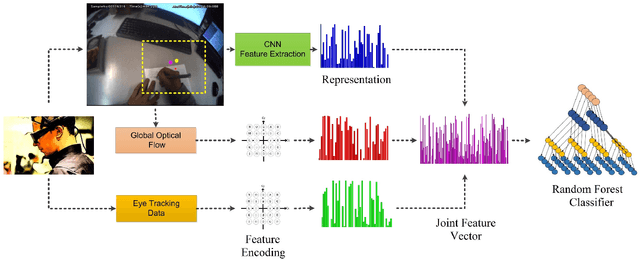
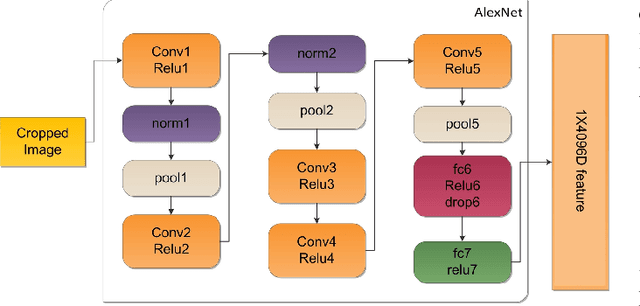
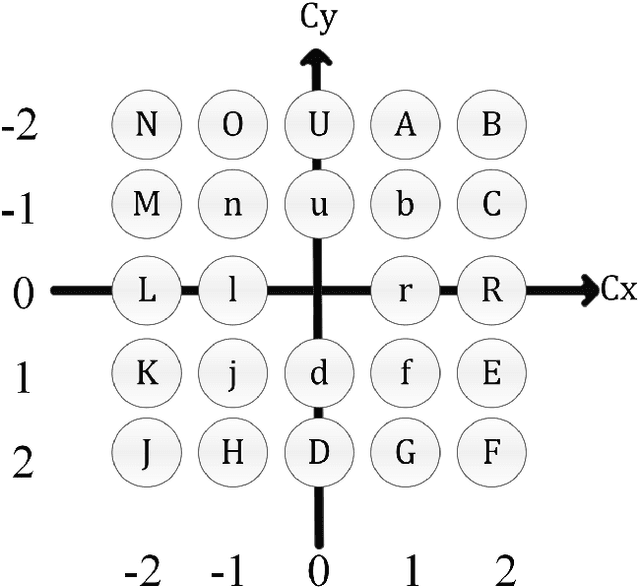
This paper presents a framework for recognition of human activity from egocentric video and eye tracking data obtained from a head-mounted eye tracker. Three channels of information such as eye movement, ego-motion, and visual features are combined for the classification of activities. Image features were extracted using a pre-trained convolutional neural network. Eye and ego-motion are quantized, and the windowed histograms are used as the features. The combination of features obtains better accuracy for activity classification as compared to individual features.
Graph Scaling Cut with L1-Norm for Classification of Hyperspectral Images
Sep 09, 2017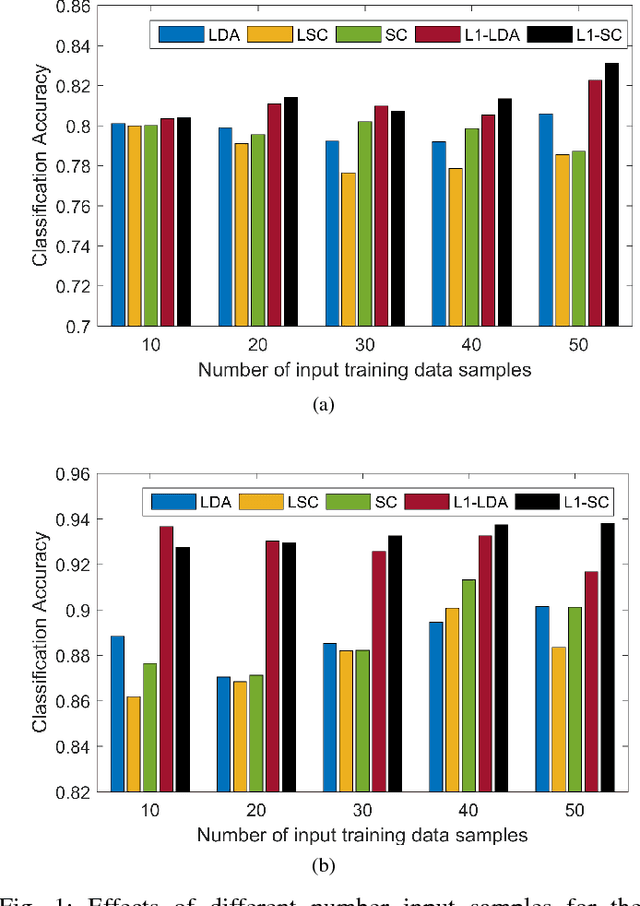
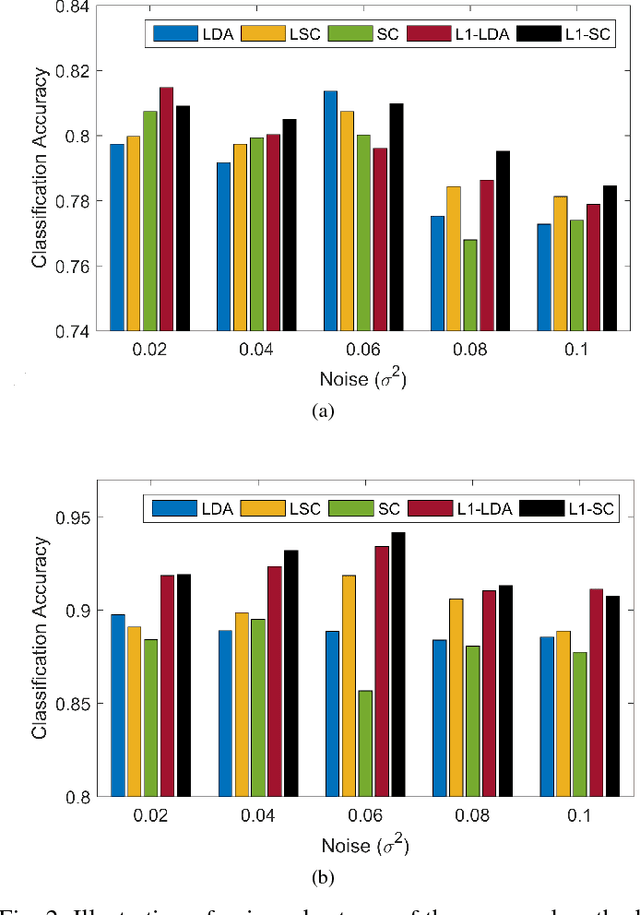

In this paper, we propose an L1 normalized graph based dimensionality reduction method for Hyperspectral images, called as L1-Scaling Cut (L1-SC). The underlying idea of this method is to generate the optimal projection matrix by retaining the original distribution of the data. Though L2-norm is generally preferred for computation, it is sensitive to noise and outliers. However, L1-norm is robust to them. Therefore, we obtain the optimal projection matrix by maximizing the ratio of between-class dispersion to within-class dispersion using L1-norm. Furthermore, an iterative algorithm is described to solve the optimization problem. The experimental results of the HSI classification confirm the effectiveness of the proposed L1-SC method on both noisy and noiseless data.
An Effective Feature Selection Method Based on Pair-Wise Feature Proximity for High Dimensional Low Sample Size Data
Aug 08, 2017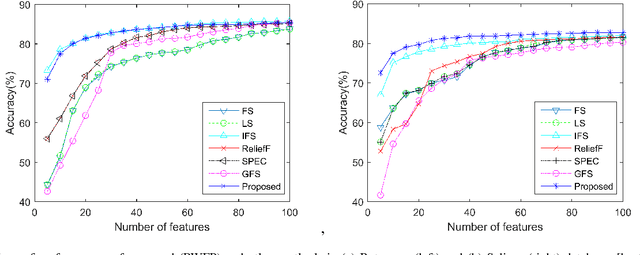
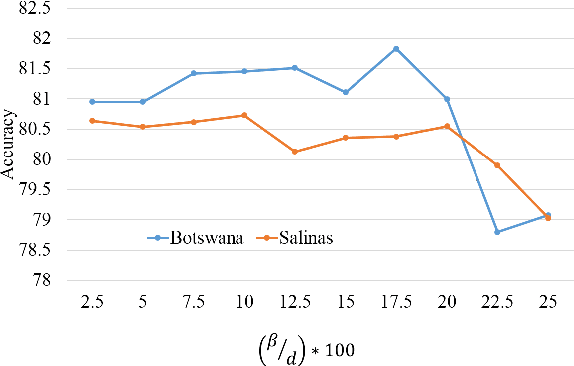
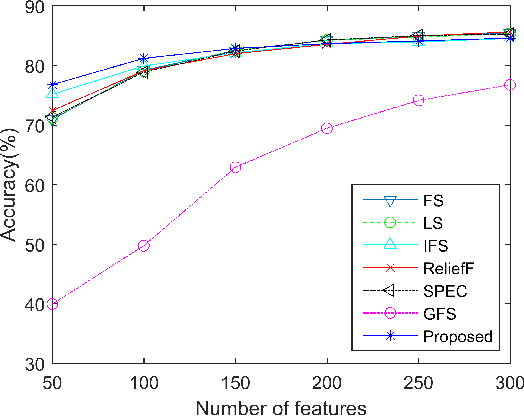
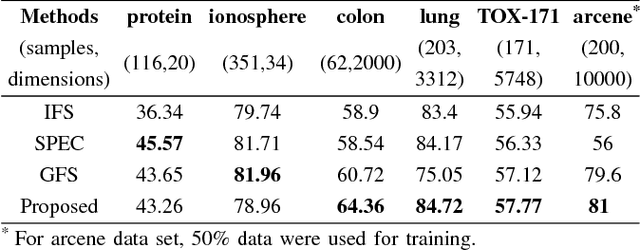
Feature selection has been studied widely in the literature. However, the efficacy of the selection criteria for low sample size applications is neglected in most cases. Most of the existing feature selection criteria are based on the sample similarity. However, the distance measures become insignificant for high dimensional low sample size (HDLSS) data. Moreover, the variance of a feature with a few samples is pointless unless it represents the data distribution efficiently. Instead of looking at the samples in groups, we evaluate their efficiency based on pairwise fashion. In our investigation, we noticed that considering a pair of samples at a time and selecting the features that bring them closer or put them far away is a better choice for feature selection. Experimental results on benchmark data sets demonstrate the effectiveness of the proposed method with low sample size, which outperforms many other state-of-the-art feature selection methods.
An Unsupervised Approach for Overlapping Cervical Cell Cytoplasm Segmentation
Feb 17, 2017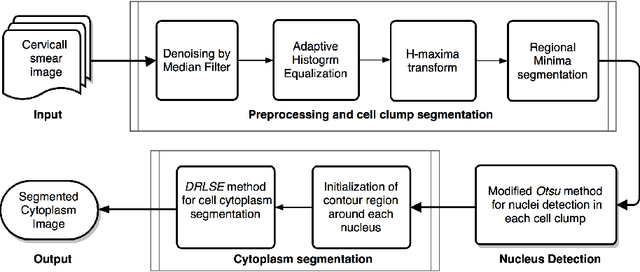


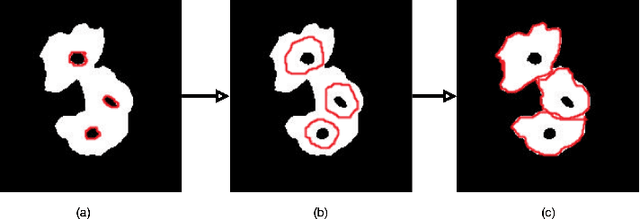
The poor contrast and the overlapping of cervical cell cytoplasm are the major issues in the accurate segmentation of cervical cell cytoplasm. This paper presents an automated unsupervised cytoplasm segmentation approach which can effectively find the cytoplasm boundaries in overlapping cells. The proposed approach first segments the cell clumps from the cervical smear image and detects the nuclei in each cell clump. A modified Otsu method with prior class probability is proposed for accurate segmentation of nuclei from the cell clumps. Using distance regularized level set evolution, the contour around each nucleus is evolved until it reaches the cytoplasm boundaries. Promising results were obtained by experimenting on ISBI 2015 challenge dataset.
* 4 pages, 4 figures, Biomedical Engineering and Sciences (IECBES), 2016 IEEE EMBS Conference on. IEEE, 2016
A Novel Framework based on SVDD to Classify Water Saturation from Seismic Attributes
Dec 02, 2016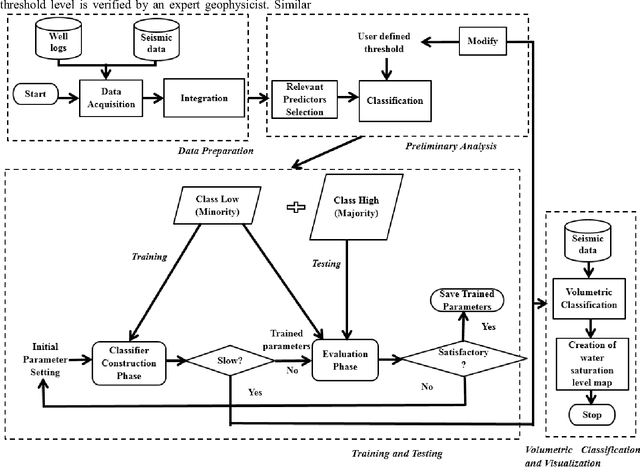
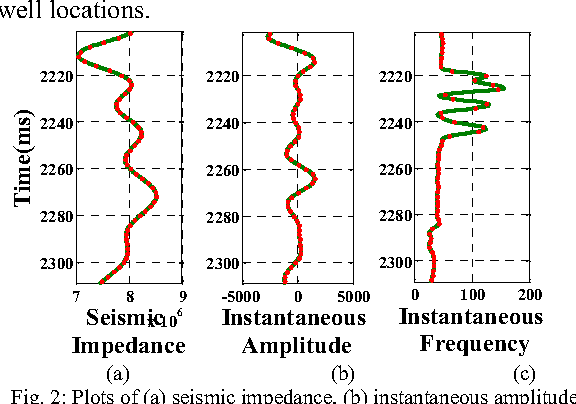
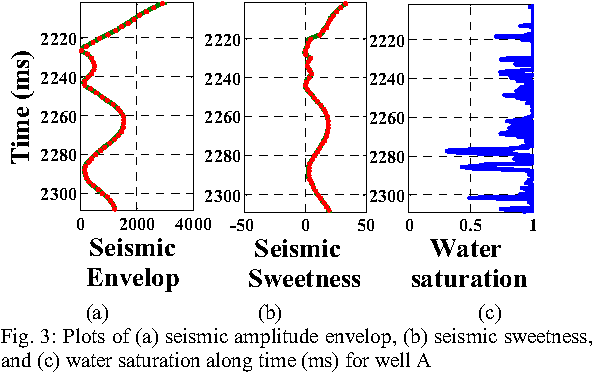
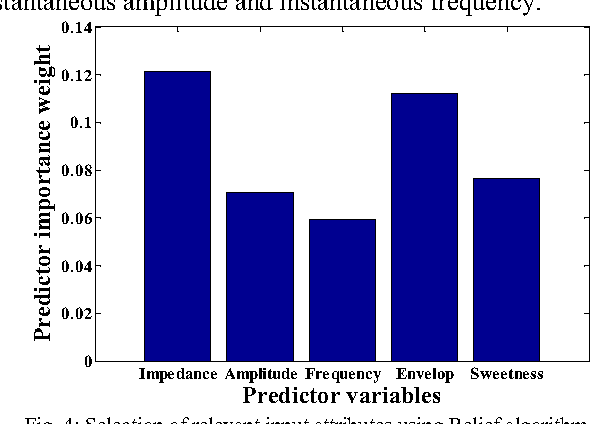
Water saturation is an important property in reservoir engineering domain. Thus, satisfactory classification of water saturation from seismic attributes is beneficial for reservoir characterization. However, diverse and non-linear nature of subsurface attributes makes the classification task difficult. In this context, this paper proposes a generalized Support Vector Data Description (SVDD) based novel classification framework to classify water saturation into two classes (Class high and Class low) from three seismic attributes seismic impedance, amplitude envelop, and seismic sweetness. G-metric means and program execution time are used to quantify the performance of the proposed framework along with established supervised classifiers. The documented results imply that the proposed framework is superior to existing classifiers. The present study is envisioned to contribute in further reservoir modeling.
Development of a hybrid learning system based on SVM, ANFIS and domain knowledge: DKFIS
Dec 02, 2016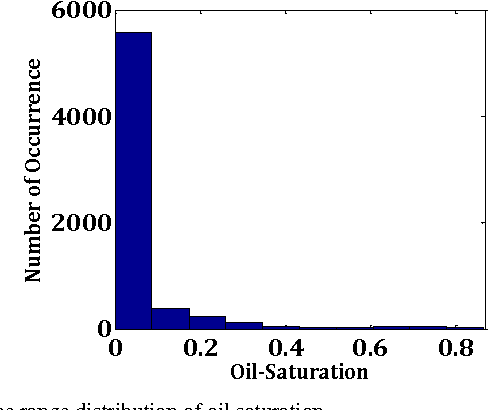
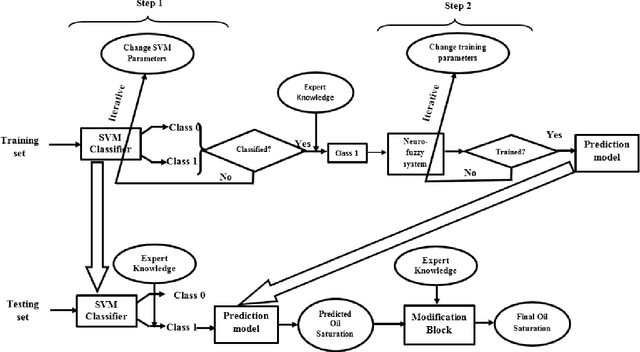
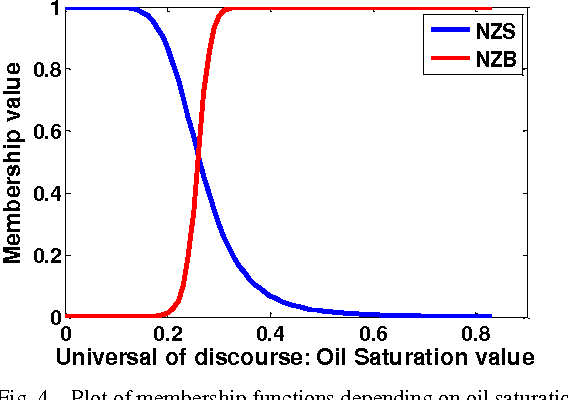
This paper presents the development of a hybrid learning system based on Support Vector Machines (SVM), Adaptive Neuro-Fuzzy Inference System (ANFIS) and domain knowledge to solve prediction problem. The proposed two-stage Domain Knowledge based Fuzzy Information System (DKFIS) improves the prediction accuracy attained by ANFIS alone. The proposed framework has been implemented on a noisy and incomplete dataset acquired from a hydrocarbon field located at western part of India. Here, oil saturation has been predicted from four different well logs i.e. gamma ray, resistivity, density, and clay volume. In the first stage, depending on zero or near zero and non-zero oil saturation levels the input vector is classified into two classes (Class 0 and Class 1) using SVM. The classification results have been further fine-tuned applying expert knowledge based on the relationship among predictor variables i.e. well logs and target variable - oil saturation. Second, an ANFIS is designed to predict non-zero (Class 1) oil saturation values from predictor logs. The predicted output has been further refined based on expert knowledge. It is apparent from the experimental results that the expert intervention with qualitative judgment at each stage has rendered the prediction into the feasible and realistic ranges. The performance analysis of the prediction in terms of four performance metrics such as correlation coefficient (CC), root mean square error (RMSE), and absolute error mean (AEM), scatter index (SI) has established DKFIS as a useful tool for reservoir characterization.