 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generate-Validate Approach to Answering Questions about Qualitative Relationships
Aug 09, 2019

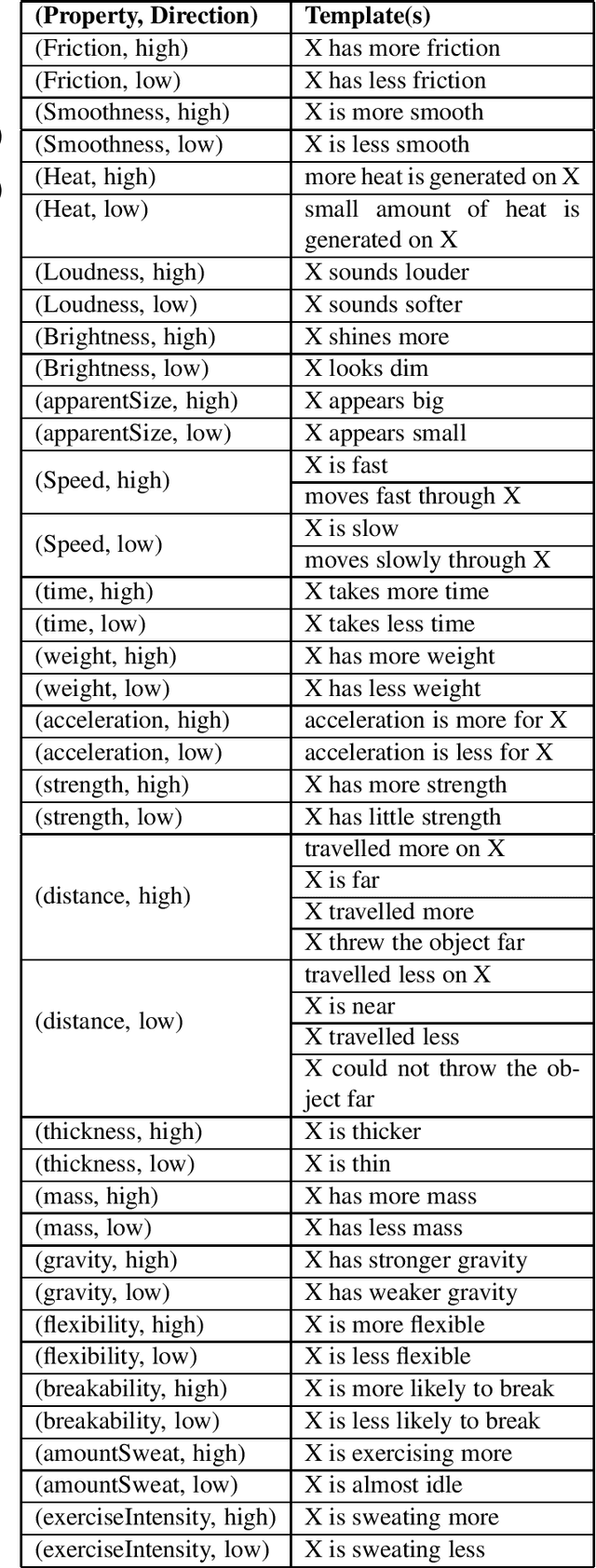
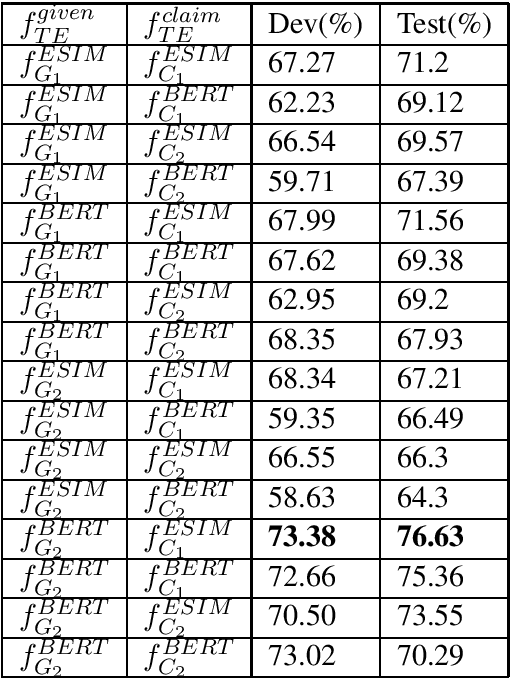
Qualitative relationships describe how increasing or decreasing one property (e.g. altitude) affects another (e.g. temperature). They are an important aspect of natural language question answering and are crucial for building chatbots or voice agents where one may enquire about qualitative relationships. Recently a dataset about question answering involving qualitative relationships has been proposed, and a few approaches to answer such questions have been explored, in the heart of which lies a semantic parser that converts the natural language input to a suitable logical form. A problem with existing semantic parsers is that they try to directly convert the input sentences to a logical form. Since the output language varies with each application, it forces the semantic parser to learn almost everything from scratch. In this paper, we show that instead of using a semantic parser to produce the logical form, if we apply the generate-validate framework i.e. generate a natural language description of the logical form and validate if the natural language description is followed from the input text, we get a better scope for transfer learning and our method outperforms the state-of-the-art by a large margin of 7.93%.
On Optimizing Human-Machine Task Assignments
Sep 24, 2015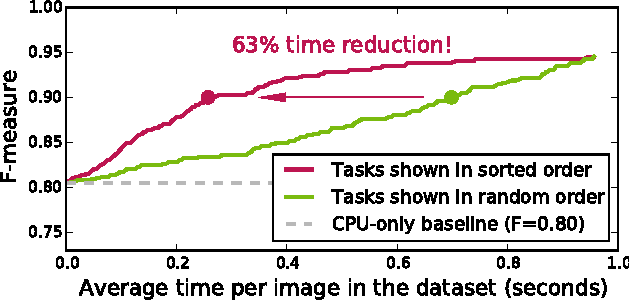
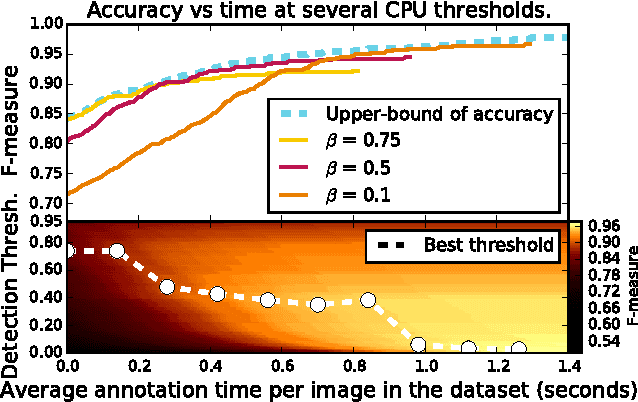
When crowdsourcing systems are used in combination with machine inference systems in the real world, they benefit the most when the machine system is deeply integrated with the crowd workers. However, if researchers wish to integrate the crowd with "off-the-shelf" machine classifiers, this deep integration is not always possible. This work explores two strategies to increase accuracy and decrease cost under this setting. First, we show that reordering tasks presented to the human can create a significant accuracy improvement. Further, we show that greedily choosing parameters to maximize machine accuracy is sub-optimal, and joint optimization of the combined system improves performance.