 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generate-Validate Approach to Answering Questions about Qualitative Relationships
Aug 09, 2019

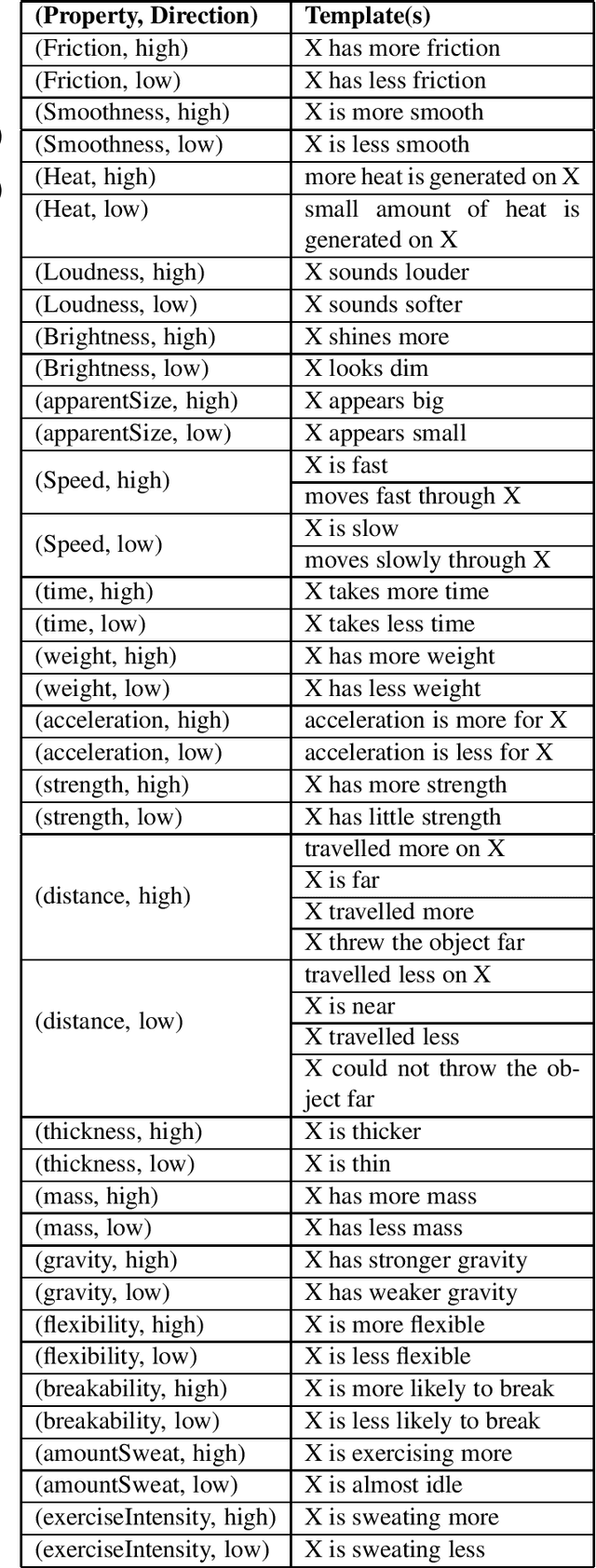
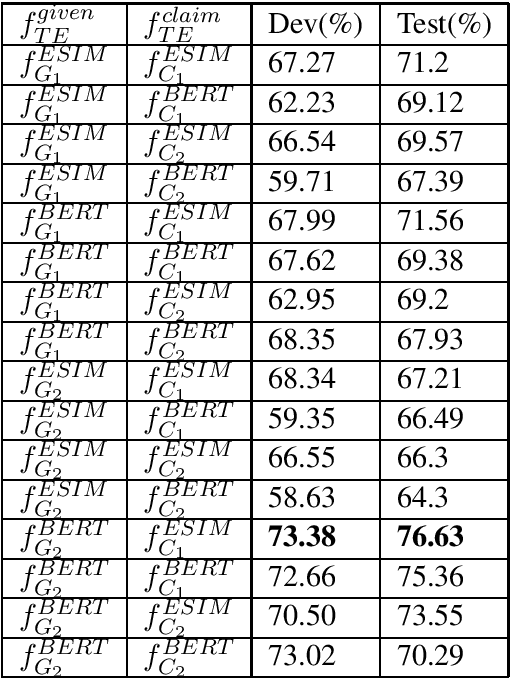
Qualitative relationships describe how increasing or decreasing one property (e.g. altitude) affects another (e.g. temperature). They are an important aspect of natural language question answering and are crucial for building chatbots or voice agents where one may enquire about qualitative relationships. Recently a dataset about question answering involving qualitative relationships has been proposed, and a few approaches to answer such questions have been explored, in the heart of which lies a semantic parser that converts the natural language input to a suitable logical form. A problem with existing semantic parsers is that they try to directly convert the input sentences to a logical form. Since the output language varies with each application, it forces the semantic parser to learn almost everything from scratch. In this paper, we show that instead of using a semantic parser to produce the logical form, if we apply the generate-validate framework i.e. generate a natural language description of the logical form and validate if the natural language description is followed from the input text, we get a better scope for transfer learning and our method outperforms the state-of-the-art by a large margin of 7.93%.
Understanding Roles and Entities: Datasets and Models for Natural Language Inference
Apr 22, 2019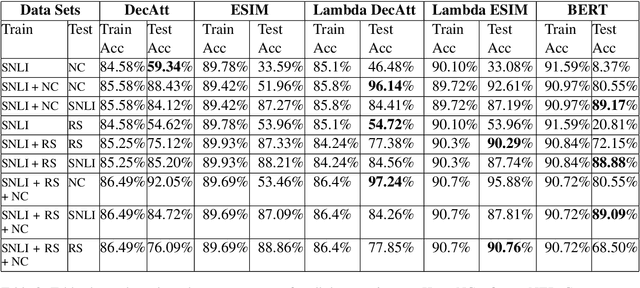
We present two new datasets and a novel attention mechanism for Natural Language Inference (NLI). Existing neural NLI models, even though when trained on existing large datasets, do not capture the notion of entity and role well and often end up making mistakes such as "Peter signed a deal" can be inferred from "John signed a deal". The two datasets have been developed to mitigate such issues and make the systems better at understanding the notion of "entities" and "roles". After training the existing architectures on the new dataset we observe that the existing architectures does not perform well on one of the new benchmark. We then propose a modification to the "word-to-word" attention function which has been uniformly reused across several popular NLI architectures. The resulting architectures perform as well as their unmodified counterparts on the existing benchmarks and perform significantly well on the new benchmark for "roles" and "entities".