 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypercomplex Image-to-Image Translation
May 04, 2022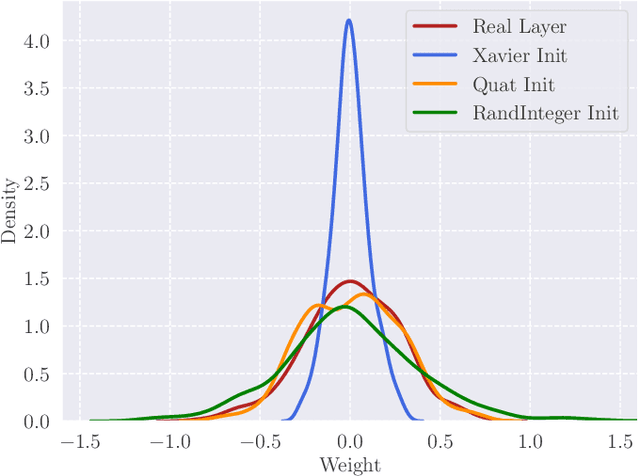
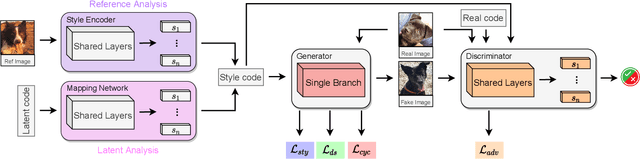


Image-to-image translation (I2I) aims at transferring the content representation from an input domain to an output one, bouncing along different target domains. Recent I2I generative models, which gain outstanding results in this task, comprise a set of diverse deep networks each with tens of million parameters. Moreover, images are usually three-dimensional being composed of RGB channels and common neural models do not take dimensions correlation into account, losing beneficial information. In this paper, we propose to leverage hypercomplex algebra properties to define lightweight I2I generative models capable of preserving pre-existing relations among image dimensions, thus exploiting additional input information. On manifold I2I benchmarks, we show how the proposed Quaternion StarGANv2 and parameterized hypercomplex StarGANv2 (PHStarGANv2) reduce parameters and storage memory amount while ensuring high domain translation performance and good image quality as measured by FID and LPIPS scores. Full code is available at: https://github.com/ispamm/HI2I.
Dual Quaternion Ambisonics Array for Six-Degree-of-Freedom Acoustic Representation
Apr 04, 2022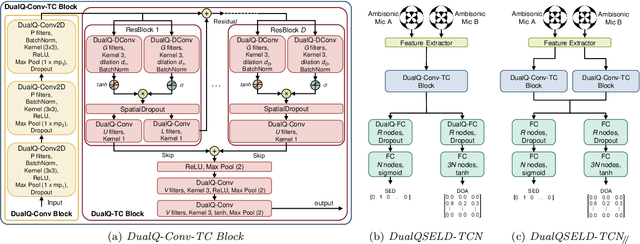

Spatial audio methods are gaining a growing interest due to the spread of immersive audio experiences and applications, such as virtual and augmented reality. For these purposes, 3D audio signals are often acquired through arrays of Ambisonics microphones, each comprising four capsules that decompose the sound field in spherical harmonics. In this paper, we propose a dual quaternion representation of the spatial sound field acquired through an array of two First Order Ambisonics (FOA) microphones. The audio signals are encapsulated in a dual quaternion that leverages quaternion algebra properties to exploit correlations among them. This augmented representation with 6 degrees of freedom (6DOF) involves a more accurate coverage of the sound field, resulting in a more precise sound localization and a more immersive audio experience. We evaluate our approach on a sound event localization and detection (SELD) benchmark. We show that our dual quaternion SELD model with temporal convolution blocks (DualQSELD-TCN) achieves better results with respect to real and quaternion-valued baselines thanks to our augmented representation of the sound field. Full code is available at: https://github.com/ispamm/DualQSELD-TCN.
L3DAS22 Challenge: Learning 3D Audio Sources in a Real Office Environment
Feb 21, 2022
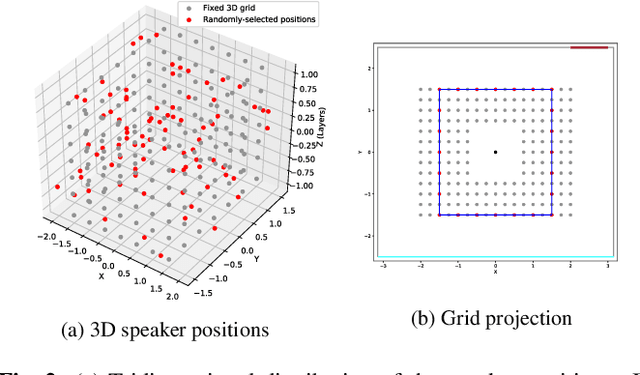
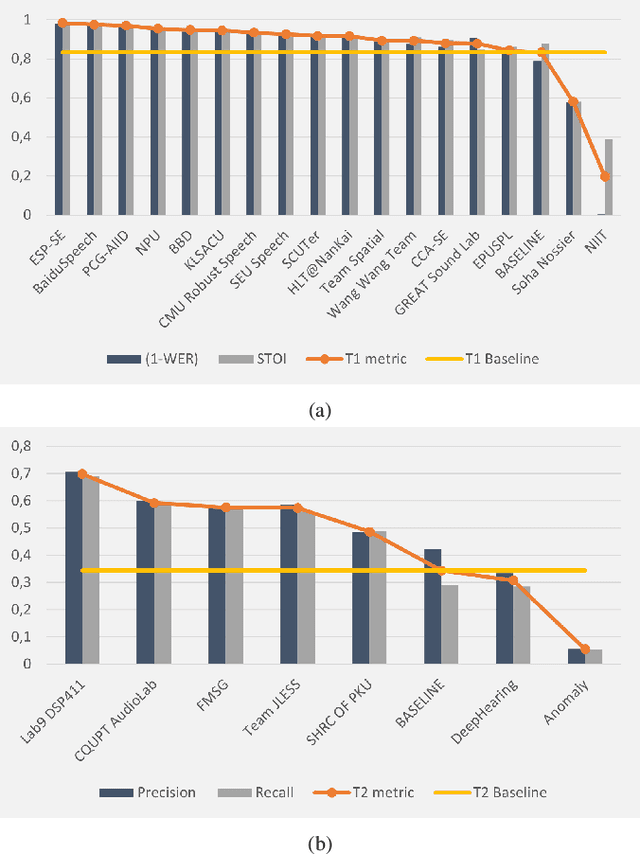
The L3DAS22 Challenge is aimed at encouraging the development of machine learning strategies for 3D speech enhancement and 3D sound localization and detection in office-like environments. This challenge improves and extends the tasks of the L3DAS21 edition. We generated a new dataset, which maintains the same general characteristics of L3DAS21 datasets, but with an extended number of data points and adding constrains that improve the baseline model's efficiency and overcome the major difficulties encountered by the participants of the previous challenge. We updated the baseline model of Task 1, using the architecture that ranked first in the previous challenge edition. We wrote a new supporting API, improving its clarity and ease-of-use. In the end, we present and discuss the results submitted by all participants. L3DAS22 Challenge website: www.l3das.com/icassp2022.
Continual Learning with Invertible Generative Models
Feb 11, 2022



Catastrophic forgetting (CF) happens whenever a neural network overwrites past knowledge while being trained on new tasks. Common techniques to handle CF include regularization of the weights (using, e.g., their importance on past tasks), and rehearsal strategies, where the network is constantly re-trained on past data. Generative models have also been applied for the latter, in order to have endless sources of data. In this paper, we propose a novel method that combines the strengths of regularization and generative-based rehearsal approaches. Our generative model consists of a normalizing flow (NF), a probabilistic and invertible neural network, trained on the internal embeddings of the network. By keeping a single NF throughout the training process, we show that our memory overhead remains constant. In addition, exploiting the invertibility of the NF, we propose a simple approach to regularize the network's embeddings with respect to past tasks. We show that our method performs favorably with espect to state-of-the-art approaches in the literature, with bounded computational power and memory overheads.
Pixle: a fast and effective black-box attack based on rearranging pixels
Feb 04, 2022
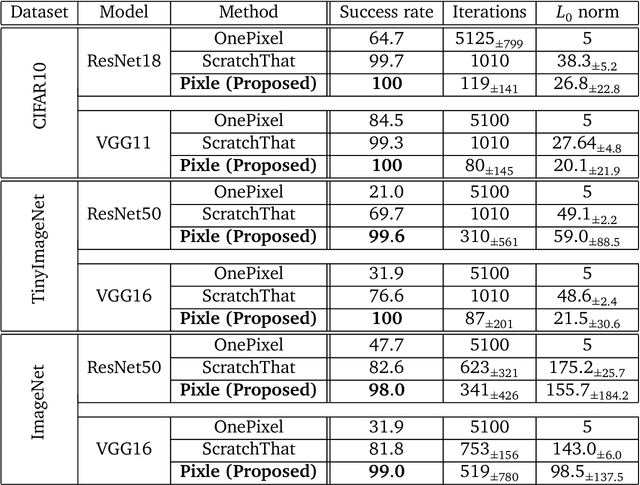
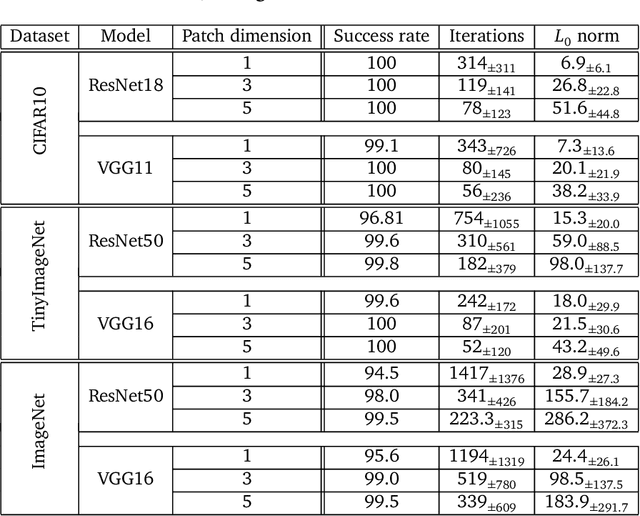
Recent research has found that neural networks are vulnerable to several types of adversarial attacks, where the input samples are modified in such a way that the model produces a wrong prediction that misclassifies the adversarial sample. In this paper we focus on black-box adversarial attacks, that can be performed without knowing the inner structure of the attacked model, nor the training procedure, and we propose a novel attack that is capable of correctly attacking a high percentage of samples by rearranging a small number of pixels within the attacked image. We demonstrate that our attack works on a large number of datasets and models, that it requires a small number of iterations, and that the distance between the original sample and the adversarial one is negligible to the human eye.
A Meta-Learning Approach for Training Explainable Graph Neural Networks
Sep 20, 2021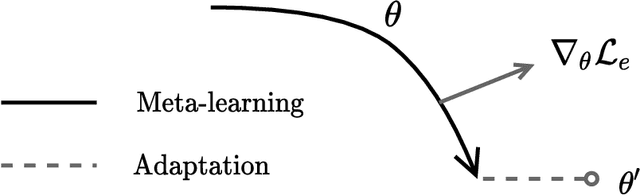

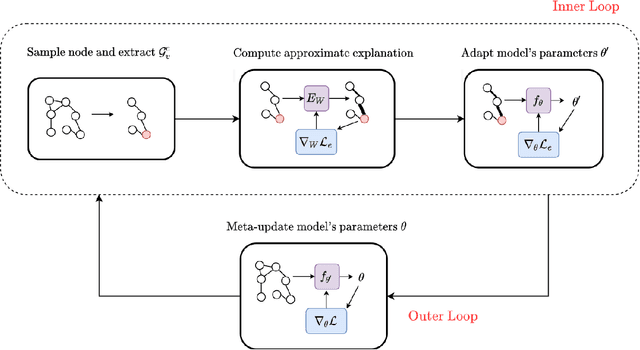
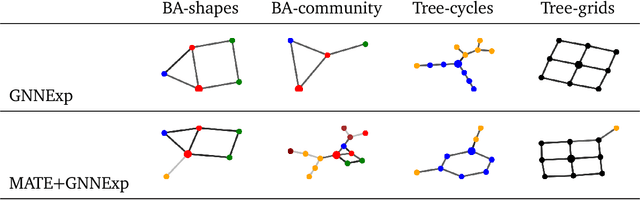
In this paper, we investigate the degree of explainability of graph neural networks (GNNs). Existing explainers work by finding global/local subgraphs to explain a prediction, but they are applied after a GNN has already been trained. Here, we propose a meta-learning framework for improving the level of explainability of a GNN directly at training time, by steering the optimization procedure towards what we call `interpretable minima'. Our framework (called MATE, MetA-Train to Explain) jointly trains a model to solve the original task, e.g., node classification, and to provide easily processable outputs for downstream algorithms that explain the model's decisions in a human-friendly way. In particular, we meta-train the model's parameters to quickly minimize the error of an instance-level GNNExplainer trained on-the-fly on randomly sampled nodes. The final internal representation relies upon a set of features that can be `better' understood by an explanation algorithm, e.g., another instance of GNNExplainer. Our model-agnostic approach can improve the explanations produced for different GNN architectures and use any instance-based explainer to drive this process. Experiments on synthetic and real-world datasets for node and graph classification show that we can produce models that are consistently easier to explain by different algorithms. Furthermore, this increase in explainability comes at no cost for the accuracy of the model.
Structured Ensembles: an Approach to Reduce the Memory Footprint of Ensemble Methods
May 06, 2021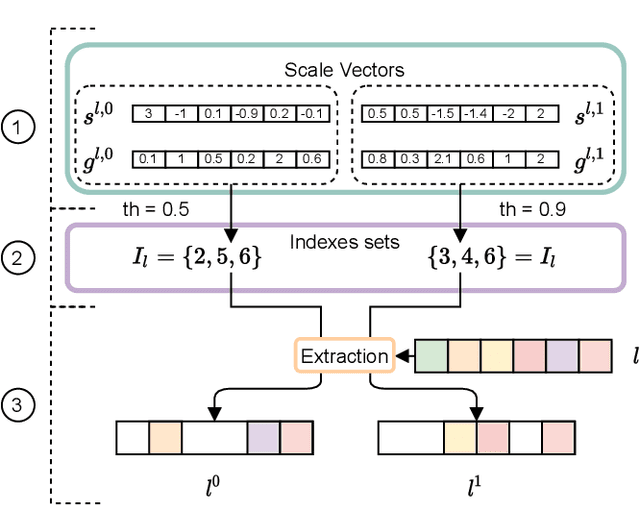
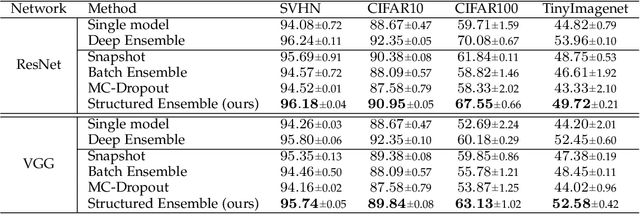
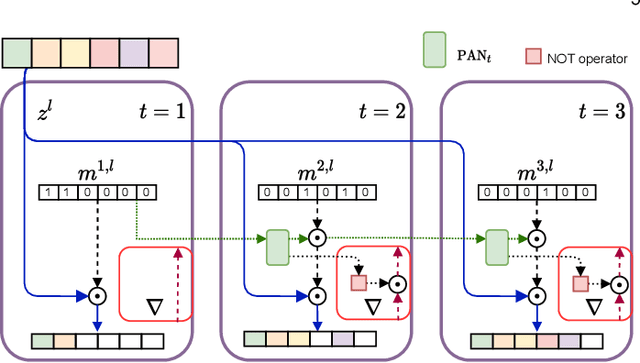
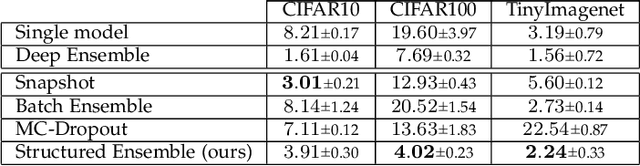
In this paper, we propose a novel ensembling technique for deep neural networks, which is able to drastically reduce the required memory compared to alternative approaches. In particular, we propose to extract multiple sub-networks from a single, untrained neural network by solving an end-to-end optimization task combining differentiable scaling over the original architecture, with multiple regularization terms favouring the diversity of the ensemble. Since our proposal aims to detect and extract sub-structures, we call it Structured Ensemble. On a large experimental evaluation, we show that our method can achieve higher or comparable accuracy to competing methods while requiring significantly less storage. In addition, we evaluate our ensembles in terms of predictive calibration and uncertainty, showing they compare favourably with the state-of-the-art. Finally, we draw a link with the continual learning literature, and we propose a modification of our framework to handle continuous streams of tasks with a sub-linear memory cost. We compare with a number of alternative strategies to mitigate catastrophic forgetting, highlighting advantages in terms of average accuracy and memory.
L3DAS21 Challenge: Machine Learning for 3D Audio Signal Processing
Apr 29, 2021
The L3DAS21 Challenge is aimed at encouraging and fostering collaborative research on machine learning for 3D audio signal processing, with particular focus on 3D speech enhancement (SE) and 3D sound localization and detection (SELD). Alongside with the challenge, we release the L3DAS21 dataset, a 65 hours 3D audio corpus, accompanied with a Python API that facilitates the data usage and results submission stage. Usually, machine learning approaches to 3D audio tasks are based on single-perspective Ambisonics recordings or on arrays of single-capsule microphones. We propose, instead, a novel multichannel audio configuration based multiple-source and multiple-perspective Ambisonics recordings, performed with an array of two first-order Ambisonics microphones. To the best of our knowledge, it is the first time that a dual-mic Ambisonics configuration is used for these tasks. We provide baseline models and results for both tasks, obtained with state-of-the-art architectures: FaSNet for SE and SELDNet for SELD. This report is aimed at providing all needed information to participate in the L3DAS21 Challenge, illustrating the details of the L3DAS21 dataset, the challenge tasks and the baseline models.
Biased Edge Dropout for Enhancing Fairness in Graph Representation Learning
Apr 29, 2021
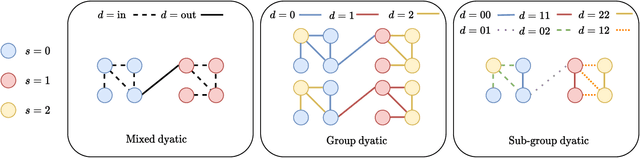
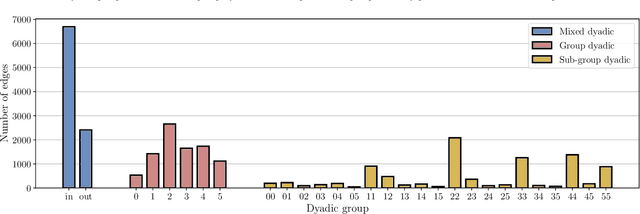

Graph representation learning has become a ubiquitous component in many scenarios, ranging from social network analysis to energy forecasting in smart grids. In several applications, ensuring the fairness of the node (or graph) representations with respect to some protected attributes is crucial for their correct deployment. Yet, fairness in graph deep learning remains under-explored, with few solutions available. In particular, the tendency of similar nodes to cluster on several real-world graphs (i.e., homophily) can dramatically worsen the fairness of these procedures. In this paper, we propose a biased edge dropout algorithm (FairDrop) to counter-act homophily and improve fairness in graph representation learning. FairDrop can be plugged in easily on many existing algorithms, is efficient, adaptable, and can be combined with other fairness-inducing solutions. After describing the general algorithm, we demonstrate its application on two benchmark tasks, specifically, as a random walk model for producing node embeddings, and to a graph convolutional network for link prediction. We prove that the proposed algorithm can successfully improve the fairness of all models up to a small or negligible drop in accuracy, and compares favourably with existing state-of-the-art solutions. In an ablation study, we demonstrate that our algorithm can flexibly interpolate between biasing towards fairness and an unbiased edge dropout. Furthermore, to better evaluate the gains, we propose a new dyadic group definition to measure the bias of a link prediction task when paired with group-based fairness metrics. In particular, we extend the metric used to measure the bias in the node embeddings to take into account the graph structure.
A New Class of Efficient Adaptive Filters for Online Nonlinear Modeling
Apr 19, 2021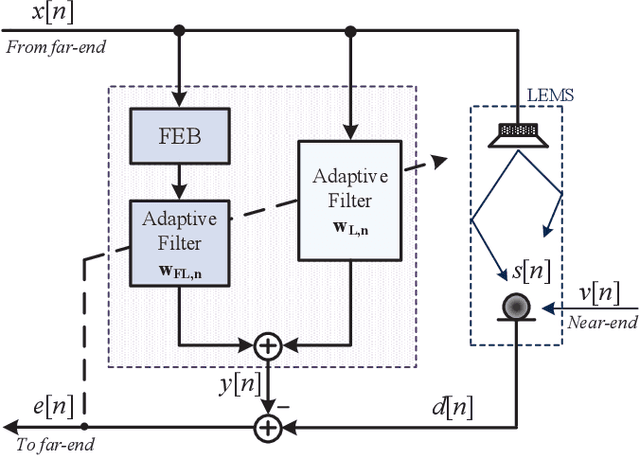
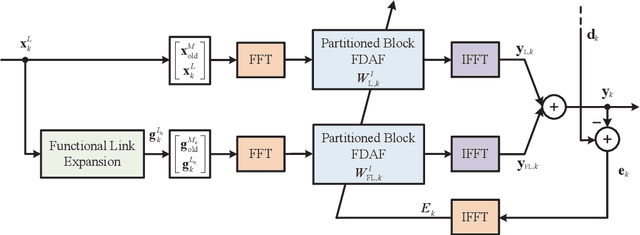
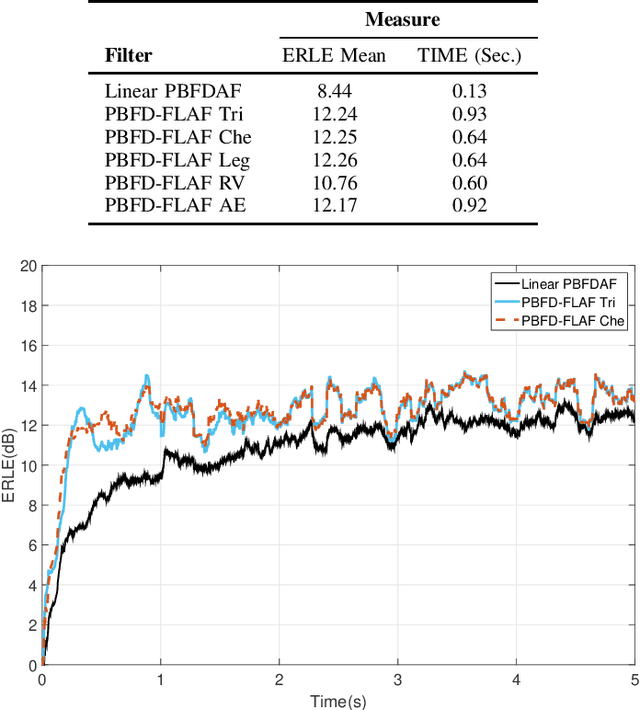

Nonlinear models are known to provide excellent performance in real-world applications that often operate in non-ideal conditions. However, such applications often require online processing to be performed with limited computational resources. In this paper, we propose a new efficient nonlinear model for online applications. The proposed algorithm is based on the linear-in-the-parameters (LIP) nonlinear filters and their implementation as functional link adaptive filters (FLAFs). We focus here on a new effective and efficient approach for FLAFs based on frequency-domain adaptive filters. We introduce the class of frequency-domain functional link adaptive filters (FD-FLAFs) and propose a partitioned block approach for their implementation. We also investigate on the functional link expansions that provide the most significant benefits operating with limited resources in the frequency-domain. We present and compare FD-FLAFs with different expansions to identify the LIP nonlinear filters showing the best tradeoff between performance and computational complexity. Experimental results prove that the frequency domain LIP nonlinear filters can be considered as an efficient and effective solution for online applications, like the nonlinear acoustic echo cancellation.