 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggression in Hindi and English Speech: Acoustic Correlates and Automatic Identification
Apr 06, 2022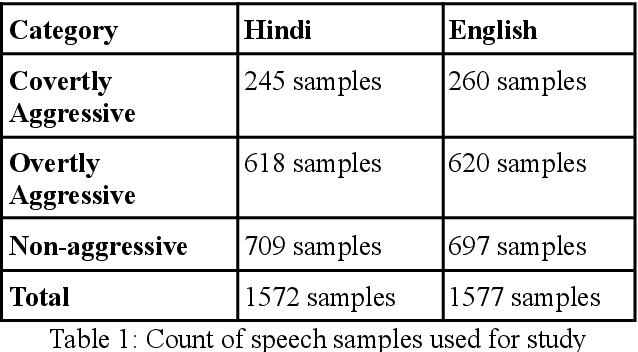
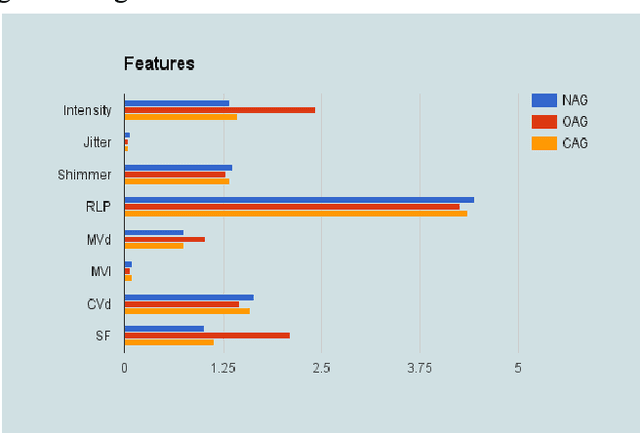
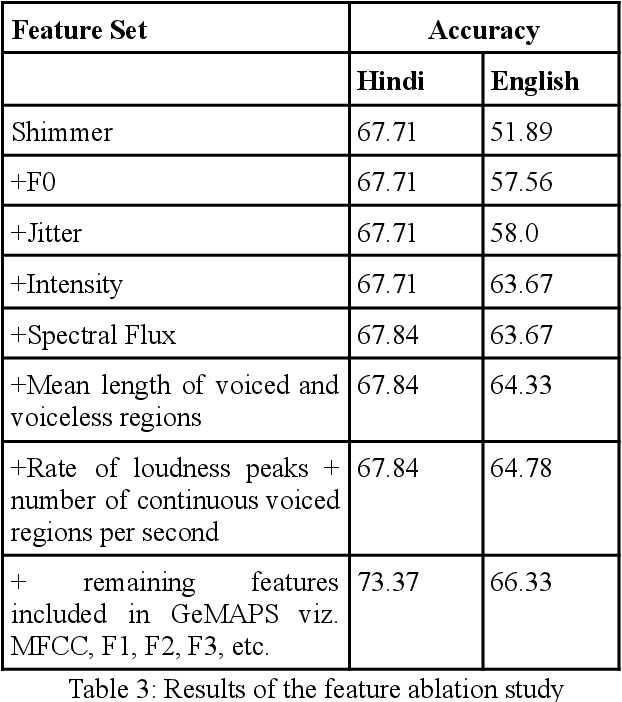
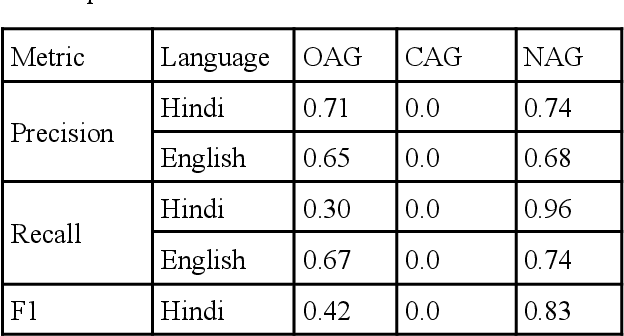
In the present paper, we will present the results of an acoustic analysis of political discourse in Hindi and discuss some of the conventionalised acoustic features of aggressive speech regularly employed by the speakers of Hindi and English. The study is based on a corpus of slightly over 10 hours of political discourse and includes debates on news channel and political speeches. Using this study, we develop two automatic classification systems for identifying aggression in English and Hindi speech, based solely on an acoustic model. The Hindi classifier, trained using 50 hours of annotated speech, and English classifier, trained using 40 hours of annotated speech, achieve a respectable accuracy of over 73% and 66% respectively. In this paper, we discuss the development of this annotated dataset, the experiments for developing the classifier and discuss the errors that it makes.
Prosody Labelled Dataset for Hindi using Semi-Automated Approach
Dec 11, 2021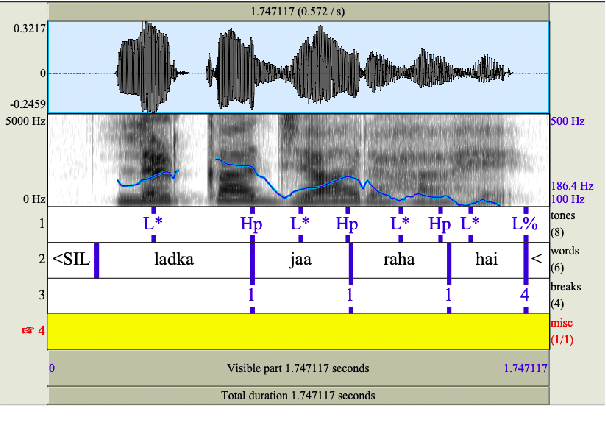
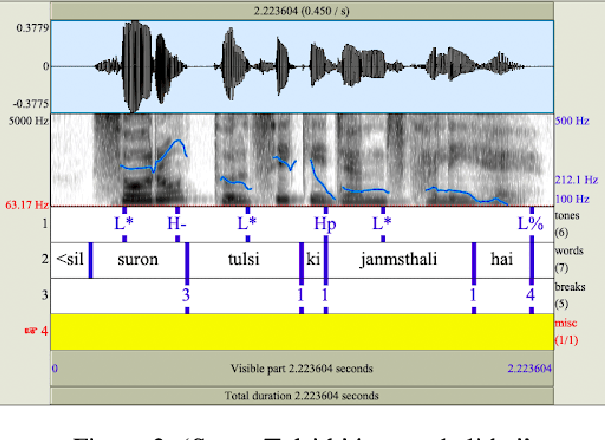
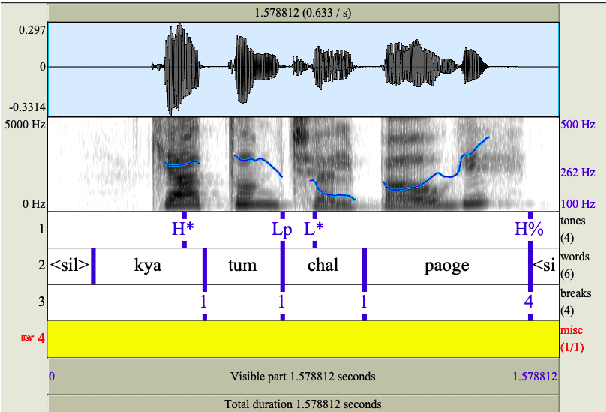
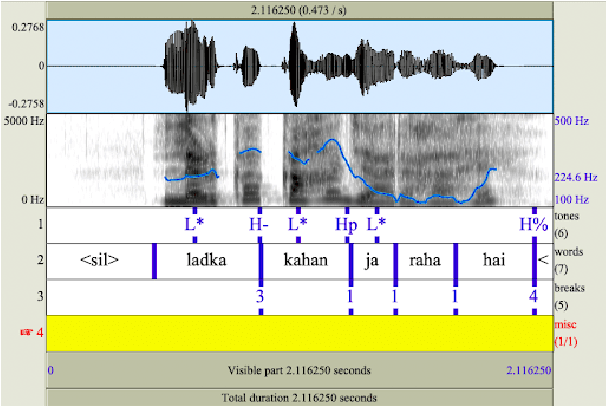
This study aims to develop a semi-automatically labelled prosody database for Hindi, for enhancing the intonation component in ASR and TTS systems, which is also helpful for building Speech to Speech Machine Translation systems. Although no single standard for prosody labelling exists in Hindi, researchers in the past have employed perceptual and statistical methods in literature to draw inferences about the behaviour of prosody patterns in Hindi. Based on such existing research and largely agreed upon theories of intonation in Hindi, this study attempts to first develop a manually annotated prosodic corpus of Hindi speech data, which is then used for training prediction models for generating automatic prosodic labels. A total of 5,000 sentences (23,500 words) for declarative and interrogative types have been labelled. The accuracy of the trained models for pitch accent, intermediate phrase boundaries and accentual phrase boundaries is 73.40%, 93.20%, and 43% respectively.
Findings of the LoResMT 2021 Shared Task on COVID and Sign Language for Low-resource Languages
Aug 18, 2021

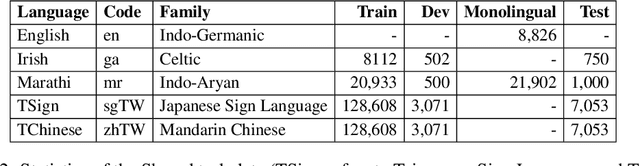
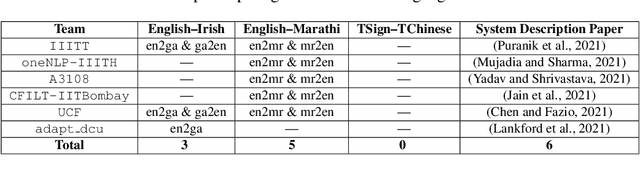
We present the findings of the LoResMT 2021 shared task which focuses on machine translation (MT) of COVID-19 data for both low-resource spoken and sign languages. The organization of this task was conducted as part of the fourth workshop on technologies for machine translation of low resource languages (LoResMT). Parallel corpora is presented and publicly available which includes the following directions: English$\leftrightarrow$Irish, English$\leftrightarrow$Marathi, and Taiwanese Sign language$\leftrightarrow$Traditional Chinese. Training data consists of 8112, 20933 and 128608 segments, respectively. There are additional monolingual data sets for Marathi and English that consist of 21901 segments. The results presented here are based on entries from a total of eight teams. Three teams submitted systems for English$\leftrightarrow$Irish while five teams submitted systems for English$\leftrightarrow$Marathi. Unfortunately, there were no systems submissions for the Taiwanese Sign language$\leftrightarrow$Traditional Chinese task. Maximum system performance was computed using BLEU and follow as 36.0 for English--Irish, 34.6 for Irish--English, 24.2 for English--Marathi, and 31.3 for Marathi--English.
Developing a Multilingual Annotated Corpus of Misogyny and Aggression
Mar 16, 2020
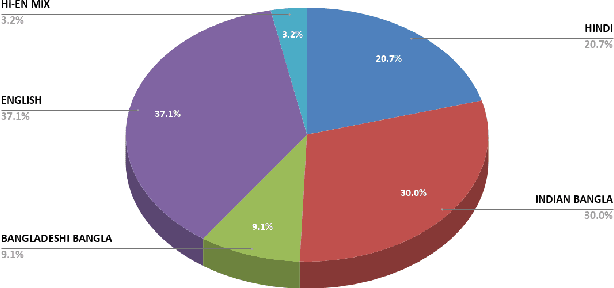

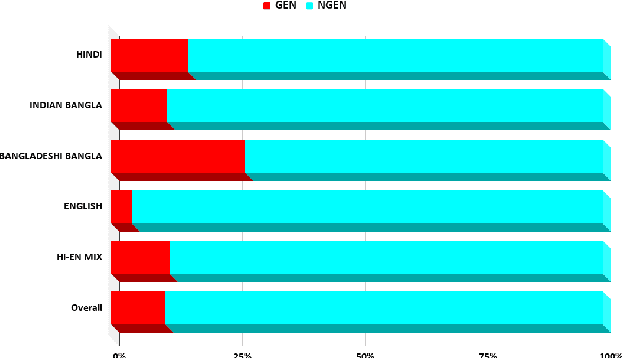
In this paper, we discuss the development of a multilingual annotated corpus of misogyny and aggression in Indian English, Hindi, and Indian Bangla as part of a project on studying and automatically identifying misogyny and communalism on social media (the ComMA Project). The dataset is collected from comments on YouTube videos and currently contains a total of over 20,000 comments. The comments are annotated at two levels - aggression (overtly aggressive, covertly aggressive, and non-aggressive) and misogyny (gendered and non-gendered). We describe the process of data collection, the tagset used for annotation, and issues and challenges faced during the process of annotation. Finally, we discuss the results of the baseline experiments conducted to develop a classifier for misogyny in the three languages.
English-Bhojpuri SMT System: Insights from the Karaka Model
May 06, 2019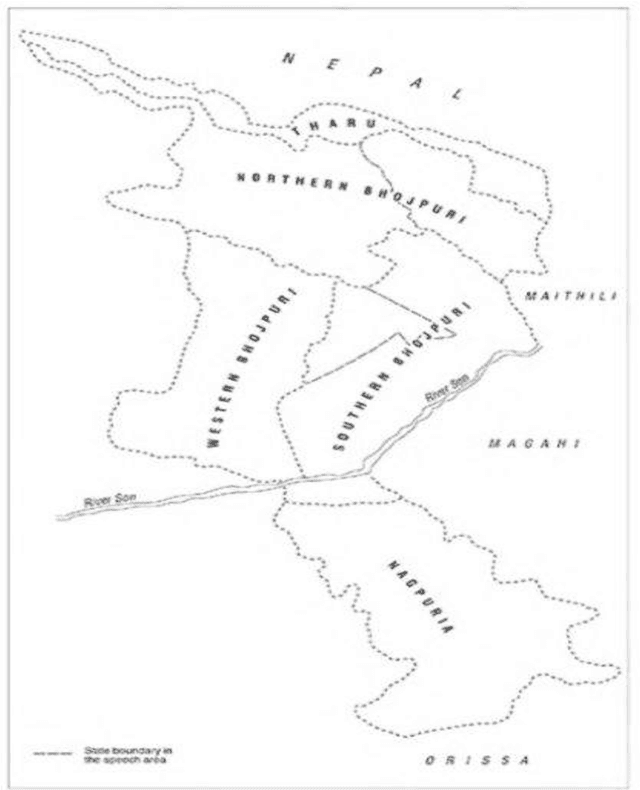
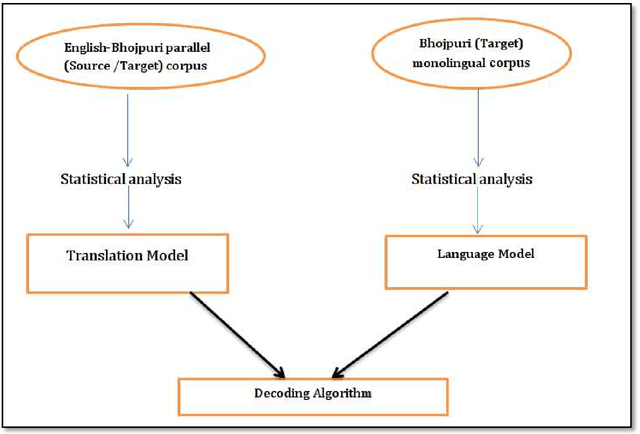
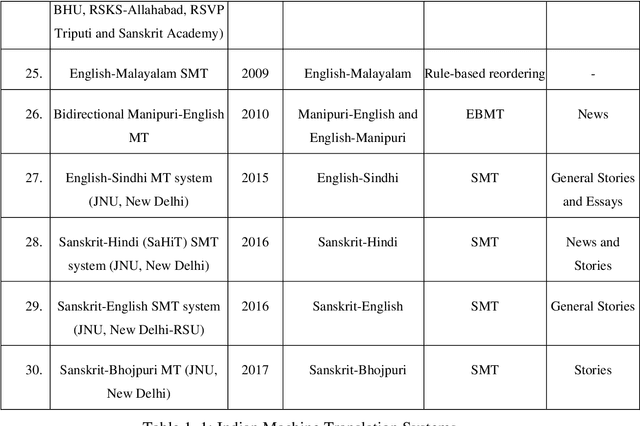
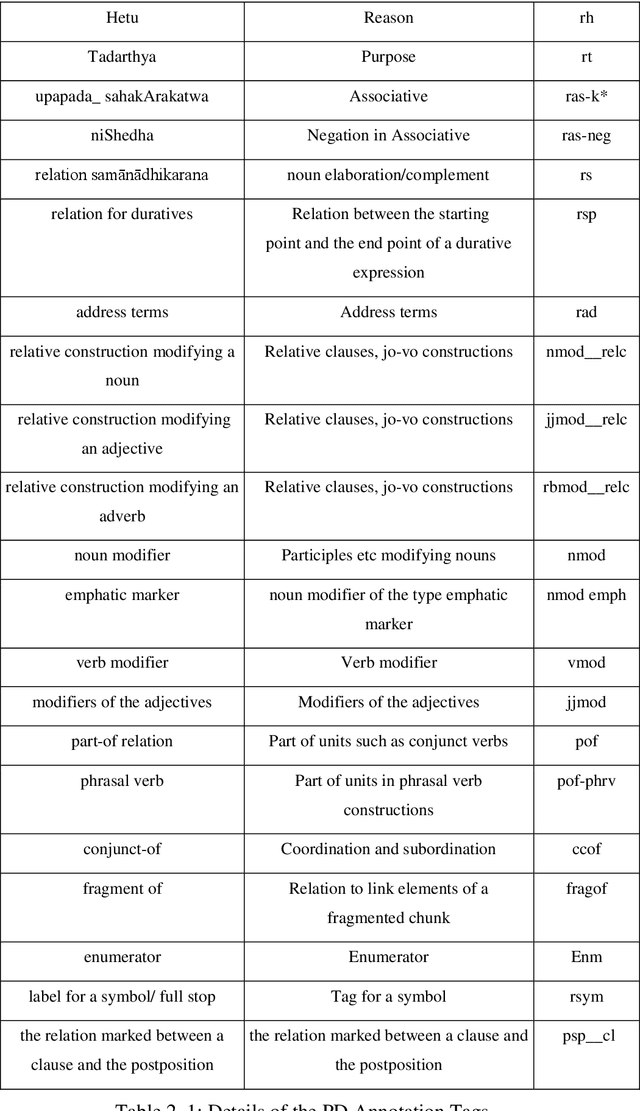
This thesis has been divided into six chapters namely: Introduction, Karaka Model and it impacts on Dependency Parsing, LT Resources for Bhojpuri, English-Bhojpuri SMT System: Experiment, Evaluation of EB-SMT System, and Conclusion. Chapter one introduces this PhD research by detailing the motivation of the study, the methodology used for the study and the literature review of the existing MT related work in Indian Languages. Chapter two talks of the theoretical background of Karaka and Karaka model. Along with this, it talks about previous related work. It also discusses the impacts of the Karaka model in NLP and dependency parsing. It compares Karaka dependency and Universal Dependency. It also presents a brief idea of the implementation of these models in the SMT system for English-Bhojpuri language pair.
The RGNLP Machine Translation Systems for WAT 2018
Dec 03, 2018
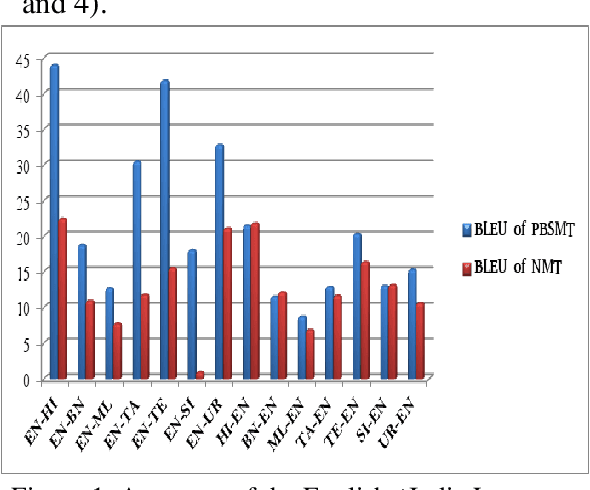
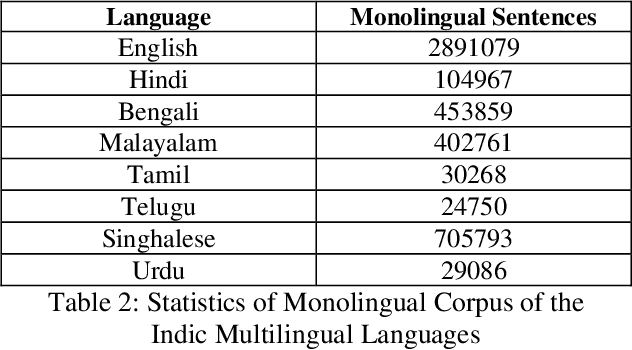
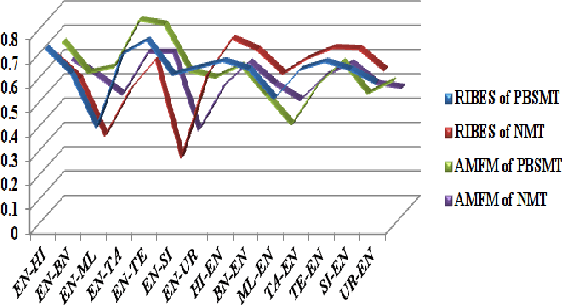
This paper presents the system description of Machine Translation (MT) system(s) for Indic Languages Multilingual Task for the 2018 edition of the WAT Shared Task. In our experiments, we (the RGNLP team) explore both statistical and neural methods across all language pairs. (We further present an extensive comparison of language-related problems for both the approaches in the context of low-resourced settings.) Our PBSMT models were highest score on all automatic evaluation metrics in the English into Telugu, Hindi, Bengali, Tamil portion of the shared task.
Demo of Sanskrit-Hindi SMT System
Apr 13, 2018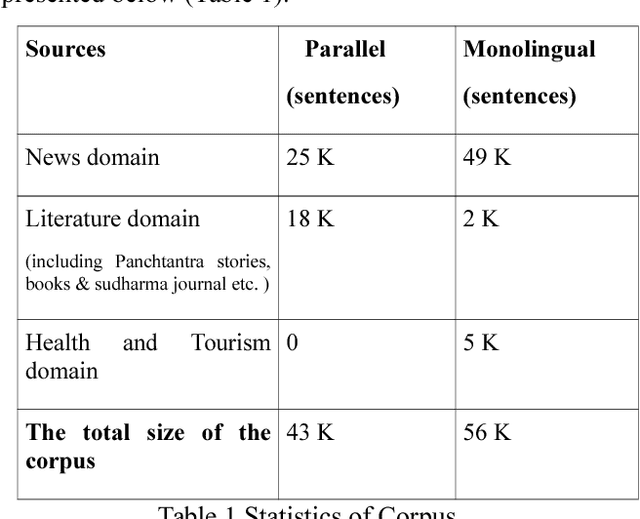
The demo proposal presents a Phrase-based Sanskrit-Hindi (SaHiT) Statistical Machine Translation system. The system has been developed on Moses. 43k sentences of Sanskrit-Hindi parallel corpus and 56k sentences of a monolingual corpus in the target language (Hindi) have been used. This system gives 57 BLEU score.
* Proceedings of the 4th Workshop on Indian Language Data: Resources and Evaluation (under the 11th LREC2018, May 07-12, 2018)
Automatic Language Identification System for Hindi and Magahi
Apr 13, 2018
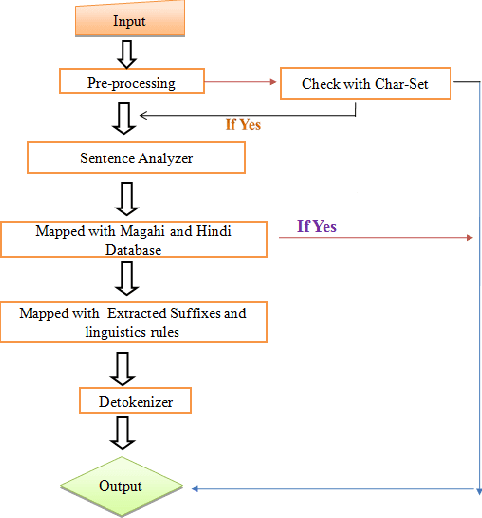
Language identification has become a prerequisite for all kinds of automated text processing systems. In this paper, we present a rule-based language identifier tool for two closely related Indo-Aryan languages: Hindi and Magahi. This system has currently achieved an accuracy of approx 86.34%. We hope to improve this in the future. Automatic identification of languages will be significant in the accuracy of output of Web Crawlers.
Automatic Identification of Closely-related Indian Languages: Resources and Experiments
Mar 26, 2018
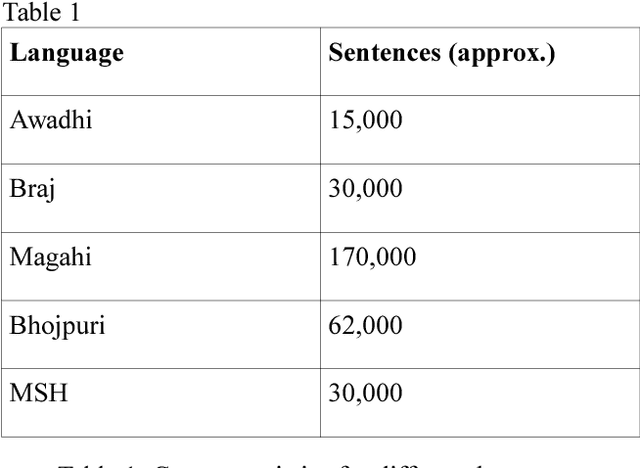
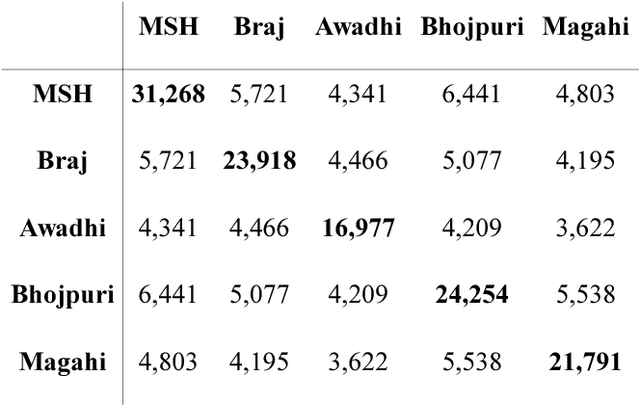
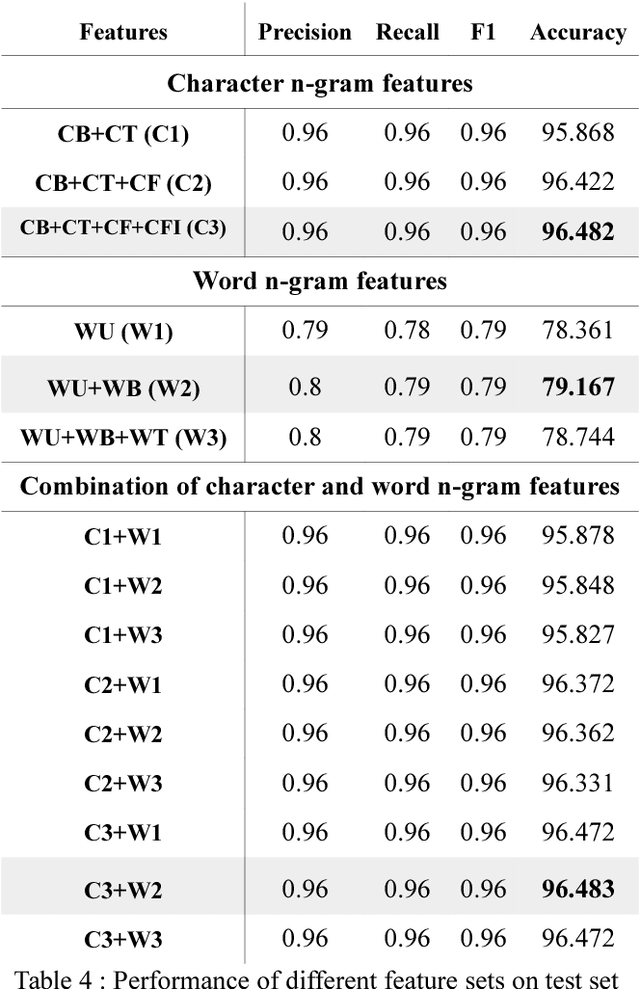
In this paper, we discuss an attempt to develop an automatic language identification system for 5 closely-related Indo-Aryan languages of India, Awadhi, Bhojpuri, Braj, Hindi and Magahi. We have compiled a comparable corpora of varying length for these languages from various resources. We discuss the method of creation of these corpora in detail. Using these corpora, a language identification system was developed, which currently gives state of the art accuracy of 96.48\%. We also used these corpora to study the similarity between the 5 languages at the lexical level, which is the first data-based study of the extent of closeness of these languages.