 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Key Challenges of Adversarial Attacks and Defenses in the Tabular Domain: A Methodological Framework for Coherence and Consistency
Dec 10, 2024



Machine learning models trained on tabular data are vulnerable to adversarial attacks, even in realistic scenarios where attackers have access only to the model's outputs. Researchers evaluate such attacks by considering metrics like success rate, perturbation magnitude, and query count. However, unlike other data domains, the tabular domain contains complex interdependencies among features, presenting a unique aspect that should be evaluated: the need for the attack to generate coherent samples and ensure feature consistency for indistinguishability. Currently, there is no established methodology for evaluating adversarial samples based on these criteria. In this paper, we address this gap by proposing new evaluation criteria tailored for tabular attacks' quality; we defined anomaly-based framework to assess the distinguishability of adversarial samples and utilize the SHAP explainability technique to identify inconsistencies in the model's decision-making process caused by adversarial samples. These criteria could form the basis for potential detection methods and be integrated into established evaluation metrics for assessing attack's quality Additionally, we introduce a novel technique for perturbing dependent features while maintaining coherence and feature consistency within the sample. We compare different attacks' strategies, examining black-box query-based attacks and transferability-based gradient attacks across four target models. Our experiments, conducted on benchmark tabular datasets, reveal significant differences between the examined attacks' strategies in terms of the attacker's risk and effort and the attacks' quality. The findings provide valuable insights on the strengths, limitations, and trade-offs of various adversarial attacks in the tabular domain, laying a foundation for future research on attacks and defense development.
DIESEL -- Dynamic Inference-Guidance via Evasion of Semantic Embeddings in LLMs
Nov 28, 2024In recent years, conversational large language models (LLMs) have shown tremendous success in tasks such as casual conversation, question answering, and personalized dialogue, making significant advancements in domains like virtual assistance, social interaction, and online customer engagement. However, they often generate responses that are not aligned with human values (e.g., ethical standards, safety, or social norms), leading to potentially unsafe or inappropriate outputs. While several techniques have been proposed to address this problem, they come with a cost, requiring computationally expensive training or dramatically increasing the inference time. In this paper, we present DIESEL, a lightweight inference guidance technique that can be seamlessly integrated into any autoregressive LLM to semantically filter undesired concepts from the response. DIESEL can function either as a standalone safeguard or as an additional layer of defense, enhancing response safety by reranking the LLM's proposed tokens based on their similarity to predefined negative concepts in the latent space. This approach provides an efficient and effective solution for maintaining alignment with human values. Our evaluation demonstrates DIESEL's effectiveness on state-of-the-art conversational models (e.g., Llama 3), even in challenging jailbreaking scenarios that test the limits of response safety. We further show that DIESEL can be generalized to use cases other than safety, providing a versatile solution for general-purpose response filtering with minimal computational overhead.
The Information Security Awareness of Large Language Models
Nov 20, 2024



The popularity of large language models (LLMs) continues to increase, and LLM-based assistants have become ubiquitous, assisting people of diverse backgrounds in many aspects of life. Significant resources have been invested in the safety of LLMs and their alignment with social norms. However, research examining their behavior from the information security awareness (ISA) perspective is lacking. Chatbots and LLM-based assistants may put unwitting users in harm's way by facilitating unsafe behavior. We observe that the ISA inherent in some of today's most popular LLMs varies significantly, with most models requiring user prompts with a clear security context to utilize their security knowledge and provide safe responses to users. Based on this observation, we created a comprehensive set of 30 scenarios to assess the ISA of LLMs. These scenarios benchmark the evaluated models with respect to all focus areas defined in a mobile ISA taxonomy. Among our findings is that ISA is mildly affected by changing the model's temperature, whereas adjusting the system prompt can substantially impact it. This underscores the necessity of setting the right system prompt to mitigate ISA weaknesses. Our findings also highlight the importance of ISA assessment for the development of future LLM-based assistants.
DOMBA: Double Model Balancing for Access-Controlled Language Models via Minimum-Bounded Aggregation
Aug 20, 2024The utility of large language models (LLMs) depends heavily on the quality and quantity of their training data. Many organizations possess large data corpora that could be leveraged to train or fine-tune LLMs tailored to their specific needs. However, these datasets often come with access restrictions that are based on user privileges and enforced by access control mechanisms. Training LLMs on such datasets could result in exposure of sensitive information to unauthorized users. A straightforward approach for preventing such exposure is to train a separate model for each access level. This, however, may result in low utility models due to the limited amount of training data per model compared to the amount in the entire organizational corpus. Another approach is to train a single LLM on all the data while limiting the exposure of unauthorized information. However, current exposure-limiting methods for LLMs are ineffective for access-controlled data, where sensitive information appears frequently across many training examples. We propose DOMBA - double model balancing - a simple approach for training and deploying LLMs that provides high utility and access-control functionality with security guarantees. DOMBA aggregates the probability distributions of two models, each trained on documents with (potentially many) different access levels, using a "min-bounded" average function (a function that is bounded by the smaller value, e.g., harmonic mean). A detailed mathematical analysis and extensive evaluation show that DOMBA safeguards restricted information while offering utility comparable to non-secure models.
Detection of Compromised Functions in a Serverless Cloud Environment
Aug 05, 2024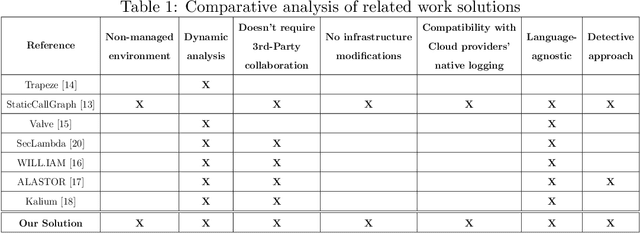
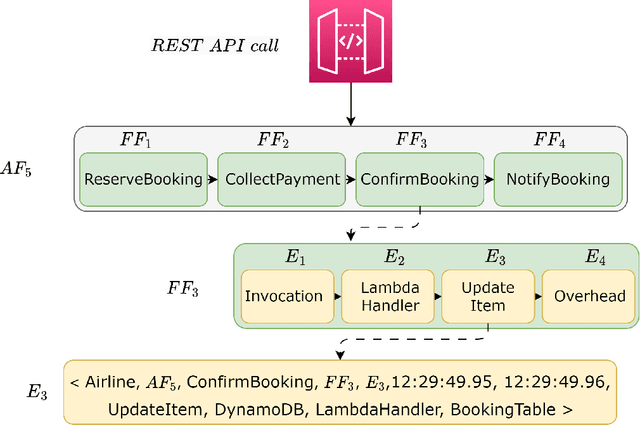
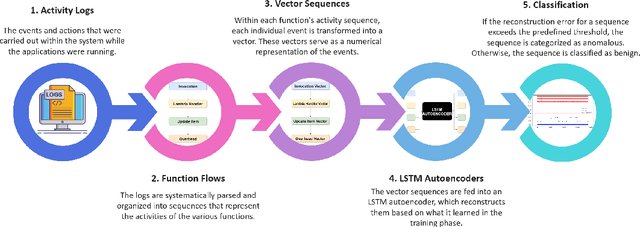
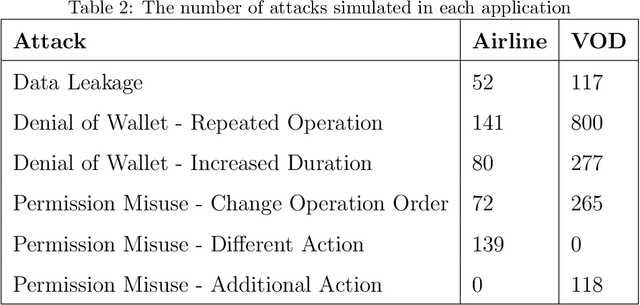
Serverless computing is an emerging cloud paradigm with serverless functions at its core. While serverless environments enable software developers to focus on developing applications without the need to actively manage the underlying runtime infrastructure, they open the door to a wide variety of security threats that can be challenging to mitigate with existing methods. Existing security solutions do not apply to all serverless architectures, since they require significant modifications to the serverless infrastructure or rely on third-party services for the collection of more detailed data. In this paper, we present an extendable serverless security threat detection model that leverages cloud providers' native monitoring tools to detect anomalous behavior in serverless applications. Our model aims to detect compromised serverless functions by identifying post-exploitation abnormal behavior related to different types of attacks on serverless functions, and therefore, it is a last line of defense. Our approach is not tied to any specific serverless application, is agnostic to the type of threats, and is adaptable through model adjustments. To evaluate our model's performance, we developed a serverless cybersecurity testbed in an AWS cloud environment, which includes two different serverless applications and simulates a variety of attack scenarios that cover the main security threats faced by serverless functions. Our evaluation demonstrates our model's ability to detect all implemented attacks while maintaining a negligible false alarm rate.
GeNet: A Multimodal LLM-Based Co-Pilot for Network Topology and Configuration
Jul 11, 2024



Communication network engineering in enterprise environments is traditionally a complex, time-consuming, and error-prone manual process. Most research on network engineering automation has concentrated on configuration synthesis, often overlooking changes in the physical network topology. This paper introduces GeNet, a multimodal co-pilot for enterprise network engineers. GeNet is a novel framework that leverages a large language model (LLM) to streamline network design workflows. It uses visual and textual modalities to interpret and update network topologies and device configurations based on user intents. GeNet was evaluated on enterprise network scenarios adapted from Cisco certification exercises. Our results demonstrate GeNet's ability to interpret network topology images accurately, potentially reducing network engineers' efforts and accelerating network design processes in enterprise environments. Furthermore, we show the importance of precise topology understanding when handling intents that require modifications to the network's topology.
LLMCloudHunter: Harnessing LLMs for Automated Extraction of Detection Rules from Cloud-Based CTI
Jul 06, 2024



As the number and sophistication of cyber attacks have increased, threat hunting has become a critical aspect of active security, enabling proactive detection and mitigation of threats before they cause significant harm. Open-source cyber threat intelligence (OS-CTI) is a valuable resource for threat hunters, however, it often comes in unstructured formats that require further manual analysis. Previous studies aimed at automating OSCTI analysis are limited since (1) they failed to provide actionable outputs, (2) they did not take advantage of images present in OSCTI sources, and (3) they focused on on-premises environments, overlooking the growing importance of cloud environments. To address these gaps, we propose LLMCloudHunter, a novel framework that leverages large language models (LLMs) to automatically generate generic-signature detection rule candidates from textual and visual OSCTI data. We evaluated the quality of the rules generated by the proposed framework using 12 annotated real-world cloud threat reports. The results show that our framework achieved a precision of 92% and recall of 98% for the task of accurately extracting API calls made by the threat actor and a precision of 99% with a recall of 98% for IoCs. Additionally, 99.18% of the generated detection rule candidates were successfully compiled and converted into Splunk queries.
RAPID: Robust APT Detection and Investigation Using Context-Aware Deep Learning
Jun 08, 2024



Advanced persistent threats (APTs) pose significant challenges for organizations, leading to data breaches, financial losses, and reputational damage. Existing provenance-based approaches for APT detection often struggle with high false positive rates, a lack of interpretability, and an inability to adapt to evolving system behavior. We introduce RAPID, a novel deep learning-based method for robust APT detection and investigation, leveraging context-aware anomaly detection and alert tracing. By utilizing self-supervised sequence learning and iteratively learned embeddings, our approach effectively adapts to dynamic system behavior. The use of provenance tracing both enriches the alerts and enhances the detection capabilities of our approach. Our extensive evaluation demonstrates RAPID's effectiveness and computational efficiency in real-world scenarios. In addition, RAPID achieves higher precision and recall than state-of-the-art methods, significantly reducing false positives. RAPID integrates contextual information and facilitates a smooth transition from detection to investigation, providing security teams with detailed insights to efficiently address APT threats.
GenKubeSec: LLM-Based Kubernetes Misconfiguration Detection, Localization, Reasoning, and Remediation
May 30, 2024A key challenge associated with Kubernetes configuration files (KCFs) is that they are often highly complex and error-prone, leading to security vulnerabilities and operational setbacks. Rule-based (RB) tools for KCF misconfiguration detection rely on static rule sets, making them inherently limited and unable to detect newly-discovered misconfigurations. RB tools also suffer from misdetection, since mistakes are likely when coding the detection rules. Recent methods for detecting and remediating KCF misconfigurations are limited in terms of their scalability and detection coverage, or due to the fact that they have high expertise requirements and do not offer automated remediation along with misconfiguration detection. Novel approaches that employ LLMs in their pipeline rely on API-based, general-purpose, and mainly commercial models. Thus, they pose security challenges, have inconsistent classification performance, and can be costly. In this paper, we propose GenKubeSec, a comprehensive and adaptive, LLM-based method, which, in addition to detecting a wide variety of KCF misconfigurations, also identifies the exact location of the misconfigurations and provides detailed reasoning about them, along with suggested remediation. When empirically compared with three industry-standard RB tools, GenKubeSec achieved equivalent precision (0.990) and superior recall (0.999). When a random sample of KCFs was examined by a Kubernetes security expert, GenKubeSec's explanations as to misconfiguration localization, reasoning and remediation were 100% correct, informative and useful. To facilitate further advancements in this domain, we share the unique dataset we collected, a unified misconfiguration index we developed for label standardization, our experimentation code, and GenKubeSec itself as an open-source tool.
CodeCloak: A Method for Evaluating and Mitigating Code Leakage by LLM Code Assistants
Apr 13, 2024



LLM-based code assistants are becoming increasingly popular among developers. These tools help developers improve their coding efficiency and reduce errors by providing real-time suggestions based on the developer's codebase. While beneficial, these tools might inadvertently expose the developer's proprietary code to the code assistant service provider during the development process. In this work, we propose two complementary methods to mitigate the risk of code leakage when using LLM-based code assistants. The first is a technique for reconstructing a developer's original codebase from code segments sent to the code assistant service (i.e., prompts) during the development process, enabling assessment and evaluation of the extent of code leakage to third parties (or adversaries). The second is CodeCloak, a novel deep reinforcement learning agent that manipulates the prompts before sending them to the code assistant service. CodeCloak aims to achieve the following two contradictory goals: (i) minimizing code leakage, while (ii) preserving relevant and useful suggestions for the developer. Our evaluation, employing GitHub Copilot, StarCoder, and CodeLlama LLM-based code assistants models, demonstrates the effectiveness of our CodeCloak approach on a diverse set of code repositories of varying sizes, as well as its transferability across different models. In addition, we generate a realistic simulated coding environment to thoroughly analyze code leakage risks and evaluate the effectiveness of our proposed mitigation techniques under practical development scenarios.